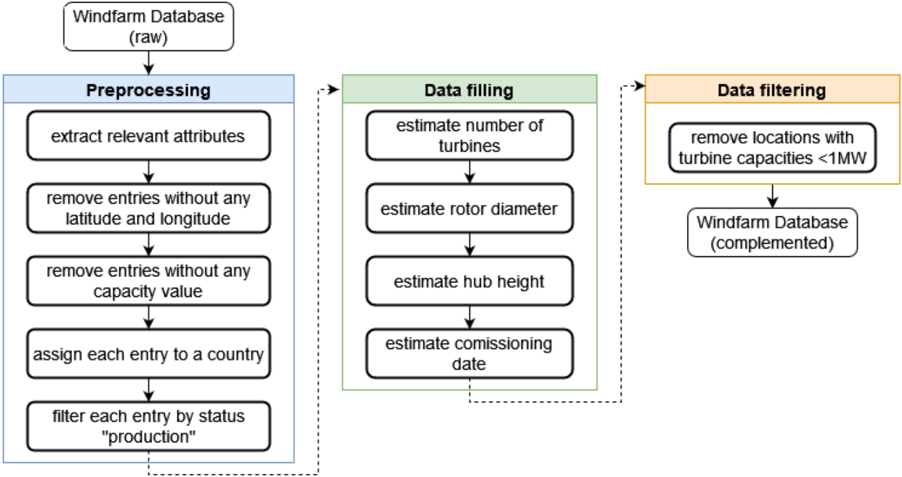
## Flowchart: Windfarm Database Processing Pipeline
### Overview
The flowchart illustrates a three-stage pipeline for processing raw windfarm data into a complemented database. The stages are color-coded: **Preprocessing** (blue), **Data Filling** (green), and **Data Filtering** (orange). Arrows indicate sequential dependencies between steps.
---
### Components/Axes
1. **Preprocessing (Blue Box)**
- Steps:
- Extract relevant attributes
- Remove entries without latitude/longitude
- Remove entries without capacity value
- Assign each entry to a country
- Filter entries by status "production"
2. **Data Filling (Green Box)**
- Steps:
- Estimate number of turbines
- Estimate rotor diameter
- Estimate hub height
- Estimate commissioning date
3. **Data Filtering (Orange Box)**
- Step:
- Remove locations with turbine capacities <1MW
4. **Output**
- Final product: **Windfarm Database (complemented)**
---
### Detailed Analysis
- **Preprocessing** focuses on data cleaning and categorization:
- Removes incomplete entries (missing geospatial or capacity data).
- Assigns country metadata and filters for "production" status.
- **Data Filling** addresses missing values by estimating:
- Turbine count, rotor diameter, hub height, and commissioning dates.
- **Data Filtering** applies a strict threshold:
- Excludes turbines with capacities below 1MW, likely to prioritize utility-scale installations.
---
### Key Observations
1. **Sequential Dependency**:
- Preprocessing must complete before Data Filling; Data Filling must complete before Data Filtering.
- Example: Entries without capacity values are removed in Preprocessing, preventing their inclusion in later stages.
2. **Thresholds**:
- The 1MW capacity cutoff in Data Filtering suggests a focus on large-scale wind farms.
3. **Metadata Enrichment**:
- Data Filling adds derived attributes (e.g., rotor diameter) not present in the raw database.
---
### Interpretation
This pipeline emphasizes **data quality** and **relevance**:
- **Preprocessing** ensures only complete, geolocated, and operational entries proceed.
- **Data Filling** mitigates missing data through estimation, critical for analytical models requiring spatial or temporal granularity.
- **Data Filtering** introduces a domain-specific constraint (1MW+ turbines), aligning the dataset with utility-scale energy analysis goals.
The pipeline’s structure reflects a balance between **completeness** (filling missing data) and **precision** (removing low-capacity entries). The final complemented database likely serves as input for energy yield modeling, capacity factor analysis, or grid integration studies.
**Notable Design Choice**: The use of color coding (blue → green → orange) visually reinforces the progression from raw data to refined output, aiding interpretability for stakeholders.