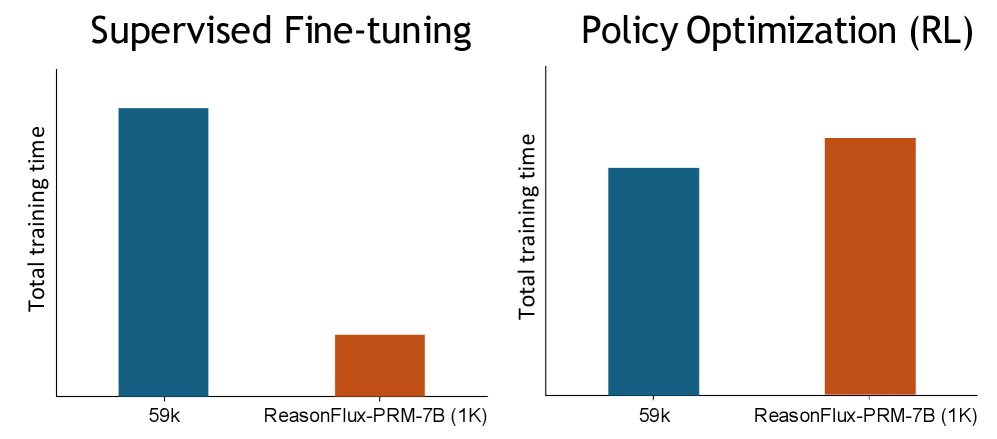
## Bar Chart: Training Time Comparison for Supervised Fine-tuning and Policy Optimization (RL)
### Overview
The image presents a bar chart comparing total training times for two methods: **Supervised Fine-tuning** and **Policy Optimization (RL)**. Each method is evaluated under two configurations: **59k** and **ReasonFlux-PRM-7B (1K)**. The y-axis represents "Total training time," while the x-axis categorizes the methods and configurations.
---
### Components/Axes
- **X-axis (Categories)**:
- **Supervised Fine-tuning**
- **Policy Optimization (RL)**
- Subcategories:
- **59k** (blue bars)
- **ReasonFlux-PRM-7B (1K)** (orange bars)
- **Y-axis (Values)**:
- Labeled "Total training time" with no explicit scale, but approximate values are inferred from bar heights.
- **Legend**:
- **Blue**: Represents **59k** configurations.
- **Orange**: Represents **ReasonFlux-PRM-7B (1K)** configurations.
- **Spatial Grounding**:
- Bars are grouped by method (left: Supervised Fine-tuning; right: Policy Optimization).
- Subcategories (59k vs. ReasonFlux-PRM-7B) are differentiated by color within each group.
---
### Detailed Analysis
#### Supervised Fine-tuning
- **59k (blue bar)**:
- Approximate total training time: **~100k** (highest value in the chart).
- **ReasonFlux-PRM-7B (1K) (orange bar)**:
- Approximate total training time: **~20k** (lowest value in the chart).
#### Policy Optimization (RL)
- **59k (blue bar)**:
- Approximate total training time: **~60k**.
- **ReasonFlux-PRM-7B (1K) (orange bar)**:
- Approximate total training time: **~80k**.
---
### Key Observations
1. **Supervised Fine-tuning** requires significantly more training time for the **59k** configuration compared to **ReasonFlux-PRM-7B (1K)**.
2. **Policy Optimization (RL)** shows a smaller gap between configurations:
- **59k** (60k) vs. **ReasonFlux-PRM-7B (1K)** (80k).
3. The **ReasonFlux-PRM-7B (1K)** configuration has **lower training times** in **Supervised Fine-tuning** but **higher training times** in **Policy Optimization (RL)** compared to its **59k** counterpart.
---
### Interpretation
- **Efficiency Trade-offs**:
- The **ReasonFlux-PRM-7B (1K)** configuration reduces training time in **Supervised Fine-tuning** but increases it in **Policy Optimization (RL)**, suggesting method-specific efficiency.
- **Scale Impact**:
- Larger configurations (**59k**) generally require more training time, but the **ReasonFlux-PRM-7B (1K)** exception in **Policy Optimization (RL)** indicates potential optimization opportunities.
- **Method-Specific Behavior**:
- **Supervised Fine-tuning** is more sensitive to configuration size, while **Policy Optimization (RL)** shows a more balanced performance across configurations.
This chart highlights the importance of method and configuration selection in training efficiency, with **ReasonFlux-PRM-7B (1K)** offering a trade-off between speed and method-specific performance.