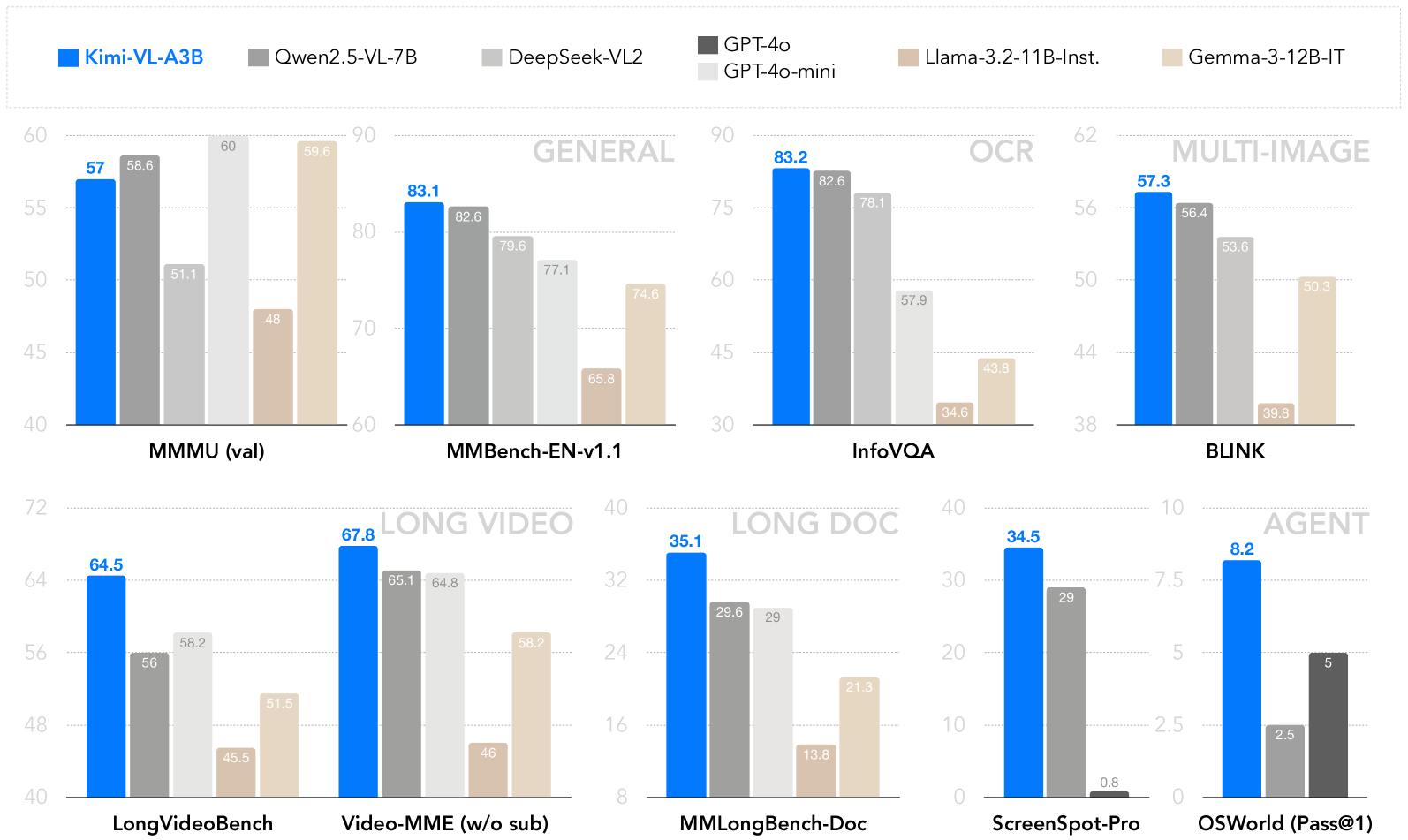
## Bar Chart: Model Performance on Various Benchmarks
### Overview
The image is a bar chart comparing the performance of several language models (Kimi-VL-A3B, Qwen2.5-VL-7B, DeepSeek-VL2, GPT-4o/GPT-4o-mini, Llama-3.2-11B-Inst., and Gemma-3-12B-IT) across different benchmark tasks. The tasks are grouped into categories like General, OCR, Multi-Image, Long Video, Long Doc, and Agent. The y-axis represents the performance score, and each model's score on a given task is represented by the height of its corresponding bar.
### Components/Axes
* **Title**: None explicitly visible in the cropped image.
* **X-Axis**: Represents different benchmark tasks: MMMU (val), MMBench-EN-v1.1, InfoVQA, BLINK, LongVideoBench, Video-MME (w/o sub), MMLongBench-Doc, ScreenSpot-Pro, OSWorld (Pass@1). These are grouped into broader categories: GENERAL, OCR, MULTI-IMAGE, LONG VIDEO, LONG DOC, and AGENT.
* **Y-Axis**: Represents the performance score. The scale varies depending on the task category.
* MMMU (val) and MMBench-EN-v1.1: 40 to 90
* InfoVQA and BLINK: 30 to 62
* LongVideoBench and Video-MME (w/o sub): 40 to 72
* MMLongBench-Doc and ScreenSpot-Pro: 0 to 40
* OSWorld (Pass@1): 0 to 10
* **Legend** (located at the top of the chart):
* Blue: Kimi-VL-A3B
* Gray: Qwen2.5-VL-7B
* Dark Gray: DeepSeek-VL2
* Black: GPT-4o/GPT-4o-mini
* Beige: Llama-3.2-11B-Inst.
* Light Beige: Gemma-3-12B-IT
### Detailed Analysis
Here's a breakdown of the performance of each model on each task, with values extracted from the bar heights:
**GENERAL**
* **MMMU (val)**:
* Kimi-VL-A3B (Blue): 57
* Qwen2.5-VL-7B (Gray): 58.6
* Llama-3.2-11B-Inst. (Beige): 51.1
* Gemma-3-12B-IT (Light Beige): 48
* **MMBench-EN-v1.1**:
* Kimi-VL-A3B (Blue): 83.1
* Qwen2.5-VL-7B (Gray): 82.6
* DeepSeek-VL2 (Dark Gray): 79.6
* GPT-4o/GPT-4o-mini (Black): 77.1
* Llama-3.2-11B-Inst. (Beige): 65.8
* Gemma-3-12B-IT (Light Beige): 74.6
**OCR**
* **InfoVQA**:
* Kimi-VL-A3B (Blue): 83.2
* Qwen2.5-VL-7B (Gray): 82.6
* DeepSeek-VL2 (Dark Gray): 78.1
* Llama-3.2-11B-Inst. (Beige): 57.9
* Gemma-3-12B-IT (Light Beige): 43.8
* GPT-4o/GPT-4o-mini (Black): 34.6
**MULTI-IMAGE**
* **BLINK**:
* Kimi-VL-A3B (Blue): 57.3
* Qwen2.5-VL-7B (Gray): 56.4
* DeepSeek-VL2 (Dark Gray): 53.6
* Llama-3.2-11B-Inst. (Beige): 50.3
* Gemma-3-12B-IT (Light Beige): 39.8
**LONG VIDEO**
* **LongVideoBench**:
* Kimi-VL-A3B (Blue): 64.5
* Qwen2.5-VL-7B (Gray): 56
* DeepSeek-VL2 (Dark Gray): 58.2
* Llama-3.2-11B-Inst. (Beige): 45.5
* Gemma-3-12B-IT (Light Beige): 51.5
* **Video-MME (w/o sub)**:
* Kimi-VL-A3B (Blue): 67.8
* Qwen2.5-VL-7B (Gray): 65.1
* DeepSeek-VL2 (Dark Gray): 64.8
* Llama-3.2-11B-Inst. (Beige): 46
* Gemma-3-12B-IT (Light Beige): 58.2
**LONG DOC**
* **MMLongBench-Doc**:
* Kimi-VL-A3B (Blue): 35.1
* Qwen2.5-VL-7B (Gray): 29.6
* DeepSeek-VL2 (Dark Gray): 29
* Llama-3.2-11B-Inst. (Beige): 13.8
* Gemma-3-12B-IT (Light Beige): 21.3
**AGENT**
* **ScreenSpot-Pro**:
* Kimi-VL-A3B (Blue): 34.5
* Qwen2.5-VL-7B (Gray): 29
* GPT-4o/GPT-4o-mini (Black): 0.8
* **OSWorld (Pass@1)**:
* Kimi-VL-A3B (Blue): 8.2
* Qwen2.5-VL-7B (Gray): 5
* GPT-4o/GPT-4o-mini (Black): 2.5
* DeepSeek-VL2 (Dark Gray): 5
### Key Observations
* Kimi-VL-A3B generally performs well across most tasks, often achieving the highest scores.
* Qwen2.5-VL-7B consistently scores close to Kimi-VL-A3B.
* GPT-4o/GPT-4o-mini shows mixed performance, excelling in some areas but lagging in others (particularly ScreenSpot-Pro).
* Llama-3.2-11B-Inst. and Gemma-3-12B-IT tend to have lower scores compared to Kimi-VL-A3B and Qwen2.5-VL-7B.
### Interpretation
The bar chart provides a comparative analysis of different language models on a variety of tasks, highlighting their strengths and weaknesses. Kimi-VL-A3B appears to be a strong all-around performer. The data suggests that model architecture and training data significantly impact performance on specific tasks. For example, the relatively low score of GPT-4o/GPT-4o-mini on ScreenSpot-Pro suggests it may not be optimized for that particular type of task. The chart is useful for understanding which models are best suited for different applications.