TECHNICAL ASSET FINGERPRINT
2e35a83db70ed2843d8c95d6
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
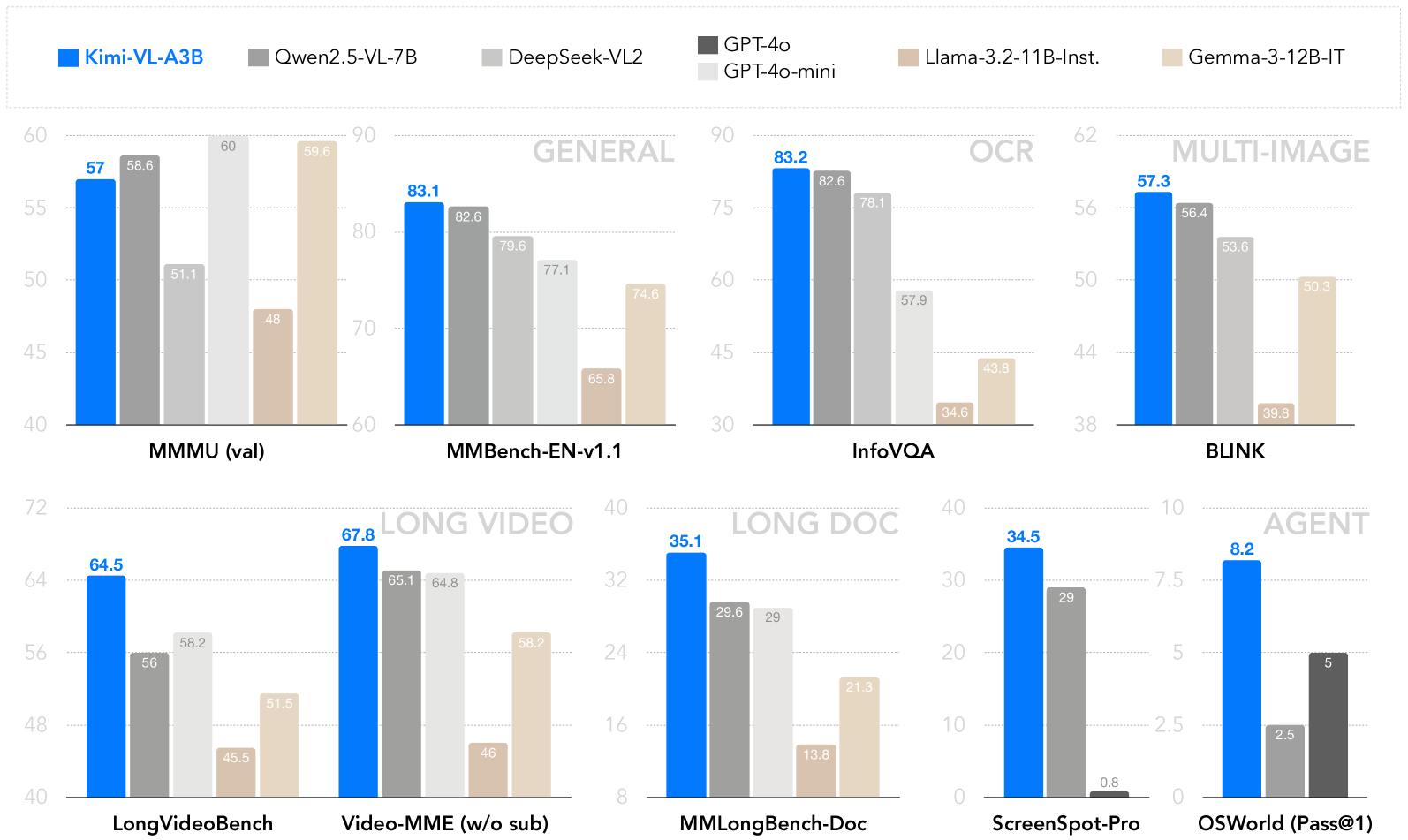
## Grouped Bar Chart: AI Model Performance Across Visual-Language Benchmarks
### Overview
This image is a composite grouped bar chart comparing the performance of seven different AI models across six major benchmark categories, each containing one or two specific tests. The chart is organized into six distinct sections, each representing a benchmark category. The primary purpose is to visually compare the scores of the models, with a particular emphasis on the model "Kimi-VL-A3B," which is highlighted in blue.
### Components/Axes
**Legend (Top Center):**
The legend is positioned at the top of the entire chart, spanning horizontally. It maps model names to specific colors:
* **Kimi-VL-A3B**: Bright Blue
* **Qwen2.5-VL-7B**: Dark Gray
* **DeepSeek-VL2**: Light Gray
* **GPT-4o**: Very Dark Gray (almost black)
* **GPT-4o-mini**: Very Light Gray
* **Llama-3.2-11B-Inst.**: Light Brown/Tan
* **Gemma-3-12B-IT**: Beige/Light Tan
**Chart Sections & Axes:**
The chart is segmented into six regions, each with its own title and y-axis scale. The x-axis within each section lists the specific benchmark names.
1. **GENERAL (Top Left):**
* **Benchmarks:** MMMU (val), MMBench-EN-v1.1
* **Y-Axis:** Linear scale from 40 to 60 for MMMU (val); from 60 to 90 for MMBench-EN-v1.1.
2. **OCR (Top Center):**
* **Benchmark:** InfoVQA
* **Y-Axis:** Linear scale from 30 to 90.
3. **MULTI-IMAGE (Top Right):**
* **Benchmark:** BLINK
* **Y-Axis:** Linear scale from 38 to 62.
4. **LONG VIDEO (Bottom Left):**
* **Benchmarks:** LongVideoBench, Video-MME (w/o sub)
* **Y-Axis:** Linear scale from 40 to 72 for LongVideoBench; from 40 to 72 for Video-MME (w/o sub).
5. **LONG DOC (Bottom Center):**
* **Benchmark:** MMLongBench-Doc
* **Y-Axis:** Linear scale from 8 to 40.
6. **AGENT (Bottom Right):**
* **Benchmarks:** ScreenSpot-Pro, OSWorld (Pass@1)
* **Y-Axis:** Linear scale from 0 to 40 for ScreenSpot-Pro; from 0 to 10 for OSWorld (Pass@1).
### Detailed Analysis
**1. GENERAL Benchmarks:**
* **MMMU (val):**
* **Trend:** Kimi-VL-A3B and Qwen2.5-VL-7B lead, followed by GPT-4o-mini, then DeepSeek-VL2, with Llama-3.2-11B-Inst. and Gemma-3-12B-IT trailing.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 57
* Qwen2.5-VL-7B (Dark Gray): 58.6
* DeepSeek-VL2 (Light Gray): 51.1
* GPT-4o-mini (Very Light Gray): 60
* Llama-3.2-11B-Inst. (Light Brown): 48
* Gemma-3-12B-IT (Beige): 59.6
* **MMBench-EN-v1.1:**
* **Trend:** Kimi-VL-A3B leads, followed closely by Qwen2.5-VL-7B and DeepSeek-VL2. GPT-4o-mini and Gemma-3-12B-IT are in the next tier, with Llama-3.2-11B-Inst. significantly lower.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 83.1
* Qwen2.5-VL-7B (Dark Gray): 82.6
* DeepSeek-VL2 (Light Gray): 79.6
* GPT-4o-mini (Very Light Gray): 77.1
* Llama-3.2-11B-Inst. (Light Brown): 65.8
* Gemma-3-12B-IT (Beige): 74.6
**2. OCR Benchmark:**
* **InfoVQA:**
* **Trend:** Kimi-VL-A3B and Qwen2.5-VL-7B are the top performers, with DeepSeek-VL2 close behind. GPT-4o-mini is in the middle tier, while Llama-3.2-11B-Inst. and Gemma-3-12B-IT score notably lower.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 83.2
* Qwen2.5-VL-7B (Dark Gray): 82.6
* DeepSeek-VL2 (Light Gray): 78.1
* GPT-4o-mini (Very Light Gray): 57.9
* Llama-3.2-11B-Inst. (Light Brown): 34.6
* Gemma-3-12B-IT (Beige): 43.8
**3. MULTI-IMAGE Benchmark:**
* **BLINK:**
* **Trend:** Kimi-VL-A3B leads, followed by Qwen2.5-VL-7B and DeepSeek-VL2. Gemma-3-12B-IT is in the next tier, with Llama-3.2-11B-Inst. scoring the lowest.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 57.3
* Qwen2.5-VL-7B (Dark Gray): 56.4
* DeepSeek-VL2 (Light Gray): 53.6
* Llama-3.2-11B-Inst. (Light Brown): 39.8
* Gemma-3-12B-IT (Beige): 50.3
**4. LONG VIDEO Benchmarks:**
* **LongVideoBench:**
* **Trend:** Kimi-VL-A3B leads, followed by DeepSeek-VL2 and Qwen2.5-VL-7B. Gemma-3-12B-IT is next, with Llama-3.2-11B-Inst. scoring the lowest.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 64.5
* Qwen2.5-VL-7B (Dark Gray): 56
* DeepSeek-VL2 (Light Gray): 58.2
* Llama-3.2-11B-Inst. (Light Brown): 45.5
* Gemma-3-12B-IT (Beige): 51.5
* **Video-MME (w/o sub):**
* **Trend:** Kimi-VL-A3B leads, followed closely by Qwen2.5-VL-7B and DeepSeek-VL2. Gemma-3-12B-IT is in the next tier, with Llama-3.2-11B-Inst. scoring the lowest.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 67.8
* Qwen2.5-VL-7B (Dark Gray): 65.1
* DeepSeek-VL2 (Light Gray): 64.8
* Llama-3.2-11B-Inst. (Light Brown): 46
* Gemma-3-12B-IT (Beige): 58.2
**5. LONG DOC Benchmark:**
* **MMLongBench-Doc:**
* **Trend:** Kimi-VL-A3B leads significantly. Qwen2.5-VL-7B and DeepSeek-VL2 are in the next tier, followed by Gemma-3-12B-IT and Llama-3.2-11B-Inst.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 35.1
* Qwen2.5-VL-7B (Dark Gray): 29.6
* DeepSeek-VL2 (Light Gray): 29
* Llama-3.2-11B-Inst. (Light Brown): 13.8
* Gemma-3-12B-IT (Beige): 21.3
**6. AGENT Benchmarks:**
* **ScreenSpot-Pro:**
* **Trend:** Kimi-VL-A3B leads, followed by Qwen2.5-VL-7B. GPT-4o-mini scores very low.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 34.5
* Qwen2.5-VL-7B (Dark Gray): 29
* GPT-4o-mini (Very Light Gray): 0.8
* **OSWorld (Pass@1):**
* **Trend:** Kimi-VL-A3B leads, followed by GPT-4o and Qwen2.5-VL-7B.
* **Data Points (Approximate):**
* Kimi-VL-A3B (Blue): 8.2
* Qwen2.5-VL-7B (Dark Gray): 2.5
* GPT-4o (Very Dark Gray): 5
### Key Observations
1. **Consistent Leader:** The Kimi-VL-A3B model (blue bars) achieves the highest or near-highest score in every single benchmark presented.
2. **Strong Competitors:** Qwen2.5-VL-7B (dark gray) and DeepSeek-VL2 (light gray) are consistently in the top tier, often swapping second and third place.
3. **Variable Performance of Other Models:** GPT-4o-mini, Llama-3.2-11B-Inst., and Gemma-3-12B-IT show more variable performance. They are competitive in some benchmarks (e.g., Gemma-3-12B-IT in MMMU val) but fall significantly behind in others (e.g., Llama-3.2-11B-Inst. in InfoVQA and MMLongBench-Doc).
4. **Missing Data:** The GPT-4o model (very dark gray) only appears in the OSWorld (Pass@1) benchmark, suggesting it was not evaluated on the other tasks shown here.
5. **Task-Specific Gaps:** The performance gap between the leading models and the lower-performing ones is most pronounced in the OCR (InfoVQA) and LONG DOC (MMLongBench-Doc) benchmarks.
### Interpretation
This chart serves as a comparative performance report for visual-language AI models. The data strongly suggests that **Kimi-VL-A3B is a state-of-the-art model across a wide spectrum of visual-language tasks**, excelling in general understanding, OCR, multi-image reasoning, long video comprehension, long document processing, and agent-based interaction.
The consistent high ranking of Qwen2.5-VL-7B and DeepSeek-VL2 indicates they are also top-tier models, forming a leading group with Kimi-VL-A3B. The variability in the performance of models like Llama-3.2-11B-Inst. highlights that model capabilities are highly task-dependent; a model strong in one area (e.g., general benchmarks) may be weak in another (e.g., OCR or long-document understanding).
The chart is likely intended for a technical audience (researchers, engineers) to quickly assess model strengths and inform decisions about which model to use for specific applications. The emphasis on Kimi-VL-A3B, through its distinctive color and consistent top placement, suggests the chart may be part of a promotional or technical report highlighting its capabilities. The absence of GPT-4o from most benchmarks is a notable data gap, limiting a full comparison with that specific model.
DECODING INTELLIGENCE...