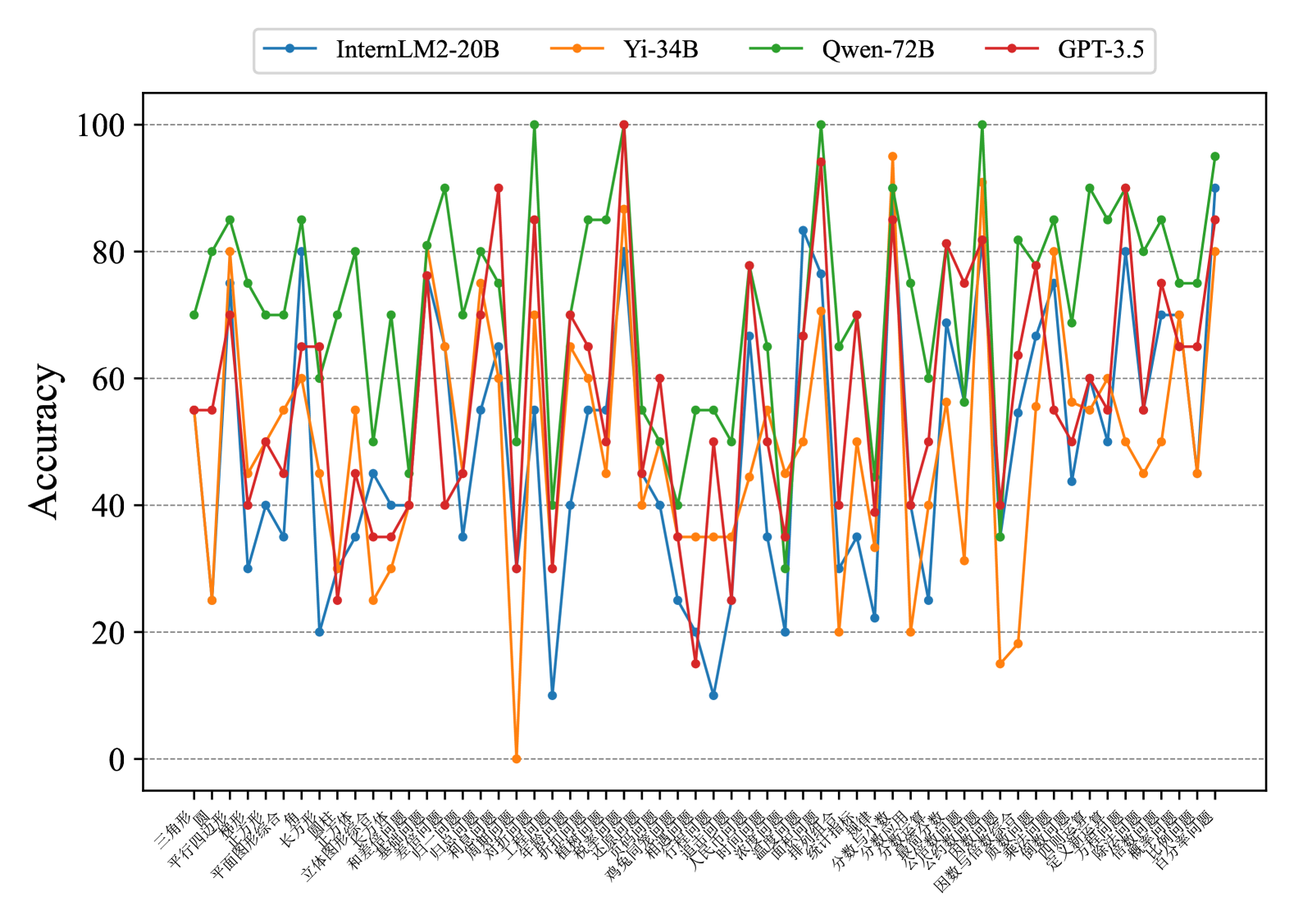
## Line Chart: Model Accuracy Comparison
### Overview
The image is a line chart comparing the accuracy of four different language models (InternLM2-20B, Yi-34B, Qwen-72B, and GPT-3.5) across a range of tasks or questions. The x-axis represents different tasks (labeled in Chinese), and the y-axis represents accuracy, ranging from 0 to 100.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:** Represents different tasks or questions. The labels are in Chinese.
* **Y-axis:** Represents "Accuracy," ranging from 0 to 100 in increments of 20. Horizontal gridlines are present at each increment.
* **Legend:** Located at the top of the chart.
* Blue: InternLM2-20B
* Orange: Yi-34B
* Green: Qwen-72B
* Red: GPT-3.5
### Detailed Analysis
The x-axis labels are in Chinese. Here are the labels, along with their approximate English translations:
1. 三角形 (sān jiǎo xíng): Triangle
2. 平面图形 (píng miàn tú xíng): Plane figure
3. 平行四边形 (píng xíng sì biān xíng): Parallelogram
4. 梯形 (tī xíng): Trapezoid
5. 平面图形综合 (píng miàn tú xíng zōng hé): Plane figure comprehensive
6. 长方形 (cháng fāng xíng): Rectangle
7. 正方形 (zhèng fāng xíng): Square
8. 立方体 (lì fāng tǐ): Cube
9. 圆柱 (yuán zhù): Cylinder
10. 立体图形综合 (lì tǐ tú xíng zōng hé): Solid figure comprehensive
11. 和差倍问题 (hé chā bèi wèn tí): Sum difference multiple problem
12. 基础应用题 (jī chǔ yìng yòng tí): Basic application problem
13. 差倍问题 (chā bèi wèn tí): Difference multiple problem
14. 归一问题 (guī yī wèn tí): Return to one problem
15. 高和矮问题 (gāo hé ǎi wèn tí): Tall and short problem
16. 对比问题 (duì bǐ wèn tí): Comparison problem
17. 工程问题 (gōng chéng wèn tí): Engineering problem
18. 折扣问题 (zhé kòu wèn tí): Discount problem
19. 植树问题 (zhí shù wèn tí): Tree planting problem
20. 税收问题 (shuì shōu wèn tí): Tax problem
21. 鸡兔同笼 (jī tù tóng lóng): Chicken and rabbit in the same cage
22. 相遇问题 (xiāng yù wèn tí): Meeting problem
23. 追及问题 (zhuī jí wèn tí): Catch-up problem
24. 人民币问题 (rén mín bì wèn tí): RMB problem
25. 浓度问题 (nóng dù wèn tí): Concentration problem
26. 盈亏问题 (yíng kuī wèn tí): Profit and loss problem
27. 面积和组合 (miàn jī hé zǔ hé): Area and combination
28. 排序问题 (pái xù wèn tí): Sorting problem
29. 统筹规划 (tǒng chóu guī huà): Overall planning
30. 分数应用 (fēn shù yìng yòng): Fraction application
31. 公因数问题 (gōng yīn shù wèn tí): Common factor problem
32. 因数分解 (yīn shù fēn jiě): Factor decomposition
33. 因数与倍数 (yīn shù yǔ bèi shù): Factors and multiples
34. 定义新运算 (dìng yì xīn yùn suàn): Define new operation
35. 定义新运算 (dìng yì xīn yùn suàn): Define new operation
36. 几何问题 (jǐ hé wèn tí): Geometric problem
37. 除法问题 (chú fǎ wèn tí): Division problem
38. 百分数问题 (bǎi fēn shù wèn tí): Percentage problem
**InternLM2-20B (Blue):** This model generally shows lower accuracy compared to the other models, with significant fluctuations across different tasks. It has some very low points, dipping near 0 accuracy on certain tasks.
**Yi-34B (Orange):** This model's accuracy fluctuates considerably, sometimes performing better than InternLM2-20B but generally lower than Qwen-72B and GPT-3.5. It also has some very low accuracy scores on certain tasks.
**Qwen-72B (Green):** This model generally exhibits higher accuracy than InternLM2-20B and Yi-34B, often reaching accuracy levels above 80%. It shows less extreme dips in performance compared to the other two.
**GPT-3.5 (Red):** This model's performance is generally competitive with Qwen-72B, showing high accuracy across many tasks. It also experiences fluctuations, but its lows are generally higher than those of InternLM2-20B and Yi-34B.
### Key Observations
* The accuracy of all models varies significantly depending on the task.
* Qwen-72B and GPT-3.5 generally outperform InternLM2-20B and Yi-34B.
* InternLM2-20B and Yi-34B have instances of very low accuracy, indicating potential weaknesses in specific areas.
* There are specific tasks where all models struggle, suggesting inherent difficulty in those tasks.
### Interpretation
The chart provides a comparative analysis of the accuracy of four language models across a diverse set of tasks. The fluctuations in accuracy highlight the varying strengths and weaknesses of each model. Qwen-72B and GPT-3.5 appear to be more robust overall, while InternLM2-20B and Yi-34B may require further refinement to improve their consistency across different problem types. The specific tasks where all models perform poorly could indicate areas where more advanced techniques or specialized training data are needed. The data suggests that model selection should be task-dependent, as no single model consistently outperforms the others across all categories.