## Line Chart: Surprisal vs. Training Steps
### Overview
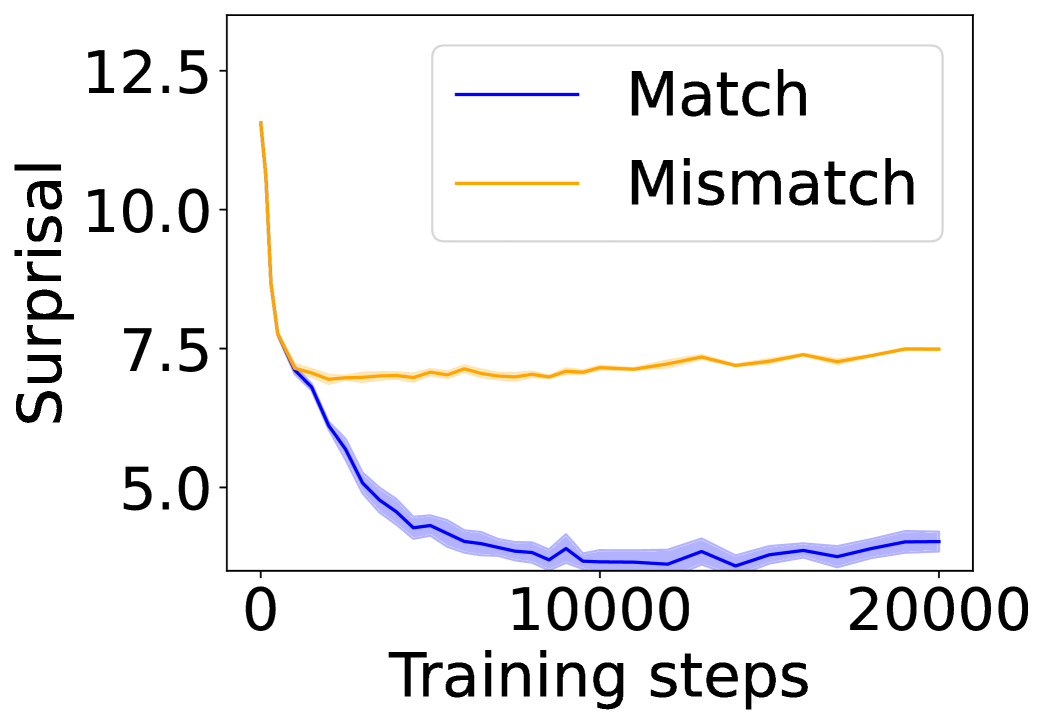
The image is a line chart that plots "Surprisal" on the y-axis against "Training steps" on the x-axis. Two data series are displayed: "Match" (blue) and "Mismatch" (orange). The "Match" series shows a decreasing trend, while the "Mismatch" series shows a slight increase after an initial drop. Shaded regions around each line indicate uncertainty or variability.
### Components/Axes
* **X-axis:** "Training steps" with markers at 0, 10000, and 20000.
* **Y-axis:** "Surprisal" with markers at 5.0, 7.5, 10.0, and 12.5.
* **Legend:** Located at the top-right of the chart.
* "Match": Represented by a blue line with a blue shaded region.
* "Mismatch": Represented by an orange line with an orange shaded region.
### Detailed Analysis
* **Match (Blue):**
* Trend: Decreases rapidly from approximately 7.5 surprisal at 0 training steps to around 4.5 surprisal at 5000 training steps. It then stabilizes and fluctuates slightly around 4.0 surprisal from 10000 to 20000 training steps.
* Data Points:
* 0 training steps: ~7.5 surprisal
* 5000 training steps: ~4.5 surprisal
* 10000 training steps: ~4.0 surprisal
* 20000 training steps: ~4.0 surprisal
* **Mismatch (Orange):**
* Trend: Decreases rapidly from approximately 12.5 surprisal at 0 training steps to around 7.0 surprisal at 2500 training steps. It then increases slightly and fluctuates around 7.25 surprisal from 5000 to 20000 training steps.
* Data Points:
* 0 training steps: ~12.5 surprisal
* 2500 training steps: ~7.0 surprisal
* 5000 training steps: ~7.25 surprisal
* 20000 training steps: ~7.25 surprisal
### Key Observations
* The "Match" series exhibits a significant decrease in surprisal during the initial training steps, indicating that the model learns to better predict matching pairs.
* The "Mismatch" series also shows an initial decrease in surprisal, but to a lesser extent than the "Match" series. It then plateaus and fluctuates slightly, suggesting that the model finds it more challenging to predict mismatched pairs.
* The shaded regions around the lines indicate the variability or uncertainty in the surprisal values. The "Match" series has a narrower shaded region, suggesting less variability compared to the "Mismatch" series.
### Interpretation
The chart illustrates the learning behavior of a model when presented with matching and mismatched pairs. The decreasing surprisal for the "Match" series suggests that the model effectively learns to predict matching pairs as training progresses. The "Mismatch" series, while also showing an initial decrease, plateaus at a higher surprisal level, indicating that predicting mismatched pairs remains more challenging for the model. The variability in the "Mismatch" series further supports this observation. The data suggests that the model is better at identifying and predicting matching pairs than mismatched pairs, which could be due to inherent differences in the complexity or predictability of these two categories.