## Reliability Diagrams: Qwen-2.5-7B Model Performance Across Context Settings
### Overview
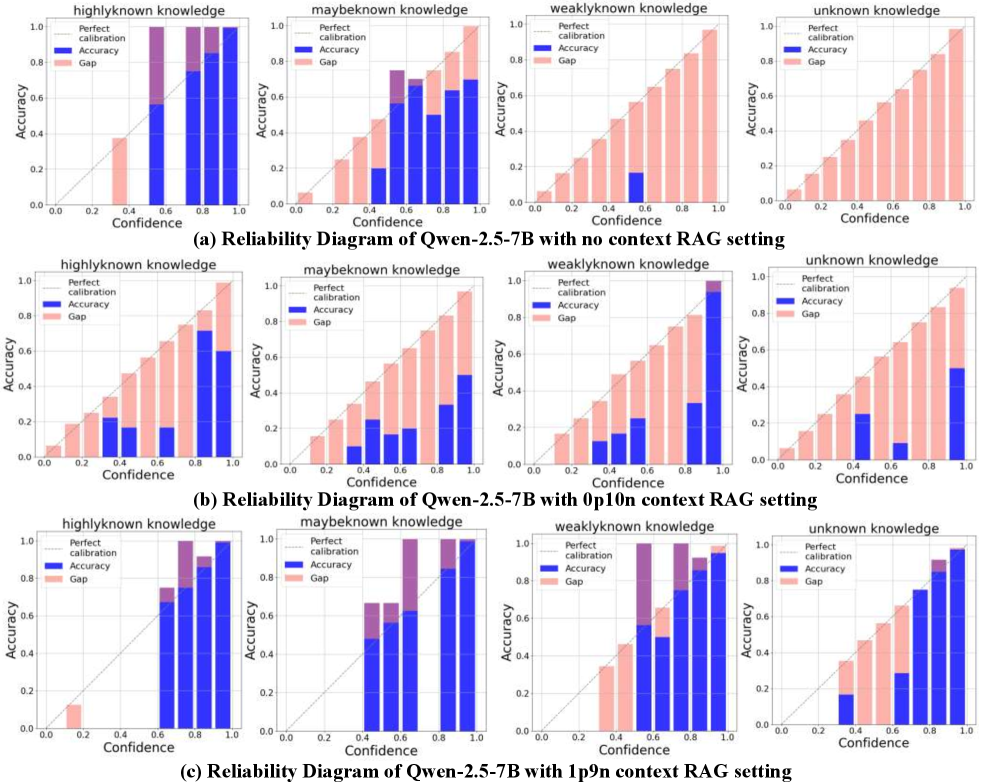
The image presents three reliability diagrams comparing the Qwen-2.5-7B language model's performance under three context RAG settings: (a) no context, (b) 0p10n context, and (c) 1p9n context. Each diagram evaluates calibration across four knowledge categories: highly known, maybe known, weakly known, and unknown knowledge. Bars represent accuracy (blue), gap between accuracy and perfect calibration (pink), and dashed lines indicate perfect calibration thresholds.
### Components/Axes
- **X-axis**: Confidence (0.0–1.0 in 0.2 increments)
- **Y-axis**: Accuracy (0.0–1.0)
- **Legend**:
- Dashed line: Perfect calibration (ideal accuracy = confidence)
- Blue bars: Accuracy
- Pink bars: Gap (perfect calibration - accuracy)
- **Subcategories**: Four knowledge categories per diagram
### Detailed Analysis
#### (a) No Context RAG Setting
- **Highly Known Knowledge**:
- Accuracy peaks at ~0.8 (confidence 0.8–1.0), closely matching perfect calibration.
- Gap minimal (~0.1–0.2) in high-confidence ranges.
- **Maybe Known Knowledge**:
- Accuracy drops to ~0.4–0.6 (confidence 0.4–0.8), with gaps widening to ~0.3–0.5.
- **Weakly Known Knowledge**:
- Accuracy ~0.2–0.4 (confidence 0.2–0.6), gaps ~0.4–0.6.
- **Unknown Knowledge**:
- Accuracy ~0.6–0.8 (confidence 0.6–1.0), gaps ~0.2–0.4.
#### (b) 0p10n Context RAG Setting
- **Highly Known Knowledge**:
- Accuracy declines to ~0.6–0.8 (confidence 0.6–1.0), gaps increase to ~0.2–0.4.
- **Maybe Known Knowledge**:
- Accuracy ~0.2–0.4 (confidence 0.2–0.6), gaps ~0.4–0.6.
- **Weakly Known Knowledge**:
- Accuracy ~0.1–0.3 (confidence 0.1–0.5), gaps ~0.5–0.7.
- **Unknown Knowledge**:
- Accuracy ~0.4–0.6 (confidence 0.4–0.8), gaps ~0.4–0.6.
#### (c) 1p9n Context RAG Setting
- **Highly Known Knowledge**:
- Accuracy ~0.7–0.9 (confidence 0.7–1.0), gaps ~0.1–0.3.
- **Maybe Known Knowledge**:
- Accuracy ~0.5–0.7 (confidence 0.5–0.9), gaps ~0.3–0.5.
- **Weakly Known Knowledge**:
- Accuracy ~0.4–0.6 (confidence 0.4–0.8), gaps ~0.4–0.6.
- **Unknown Knowledge**:
- Accuracy ~0.6–0.8 (confidence 0.6–1.0), gaps ~0.2–0.4.
### Key Observations
1. **Calibration Trends**:
- No context (a): Best calibration for highly known knowledge, overconfidence in unknown.
- 0p10n context (b): Worst calibration across all categories, largest gaps in weakly known.
- 1p9n context (c): Improved calibration, especially in unknown knowledge (gap reduced by ~50% vs. no context).
2. **Outliers**:
- In (b), weakly known knowledge shows extreme overconfidence (gap >0.5 at confidence 0.4–0.6).
- In (c), unknown knowledge achieves near-perfect calibration (gap <0.3 at confidence 0.8–1.0).
### Interpretation
The diagrams reveal that context augmentation significantly impacts calibration:
- **No context**: The model is well-calibrated for highly known knowledge but overconfident in unknown domains.
- **0p10n context**: Introduces noise, degrading calibration for maybe/weakly known knowledge.
- **1p9n context**: Optimal balance, improving calibration across all categories, particularly for unknown knowledge. This suggests that larger context windows (1p9n) help the model better align confidence with accuracy, reducing overconfidence in uncertain scenarios.
The gap metric highlights the model's reliability: smaller gaps indicate trustworthy confidence estimates. The 1p9n context setting demonstrates the most robust performance, aligning with expectations that richer context improves model reasoning.