TECHNICAL ASSET FINGERPRINT
3002ccb396c374a17bf41ad4
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
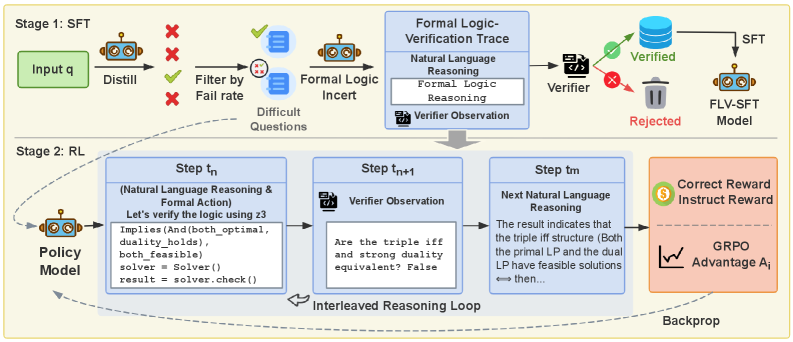
## Diagram: Two-Stage Training Pipeline for a Formal Logic-Verified Reasoning Model
### Overview
The image is a technical flowchart illustrating a two-stage machine learning training pipeline. The process is divided into **Stage 1: SFT (Supervised Fine-Tuning)** and **Stage 2: RL (Reinforcement Learning)**. The pipeline's goal is to train a model (the "FLV-SFT Model" and subsequently a "Policy Model") to perform reasoning that is verified against formal logic, using a combination of distillation, filtering, incentive mechanisms, and an interleaved reasoning loop with a verifier.
### Components/Axes
The diagram is structured as a process flow from left to right, top to bottom. Key visual components include:
* **Process Boxes:** Blue rectangular boxes with rounded corners represent major processing steps or data states.
* **Icons:** Stylized robot icons represent AI models. Other icons include a filter, a document with a checkmark (Verifier), a database, a trash can, a dollar sign (Reward), and a line graph (Advantage).
* **Arrows:** Solid black arrows indicate the primary flow of data and processes. Dashed arrows indicate feedback loops (e.g., "Backprop").
* **Text Labels:** All components are labeled with descriptive text.
* **Color Coding:** Green is used for positive outcomes ("Verified," "Correct Reward"). Red is used for negative outcomes ("Rejected," "X" marks). Blue is the primary color for process boxes. Orange is used for the final reward/advantage block.
### Detailed Analysis
#### **Stage 1: SFT (Top Half)**
This stage focuses on creating a verified dataset to fine-tune a model.
1. **Input & Distillation:** The process begins with an "Input q" (question). This is fed into a "Distill" process, represented by a robot icon.
2. **Filtering:** The output is filtered. Red "X" marks and green checkmarks indicate a selection process. The text "Filter by Fail rate" leads to the creation of a subset labeled "Difficult Questions."
3. **Formal Logic Incentive:** These difficult questions are processed by a "Formal Logic Incent" (likely "Incentive") module, represented by another robot icon.
4. **Formal Logic-Verification Trace:** The core of Stage 1 is a large blue box containing three sub-components:
* `Natural Language Reasoning`
* `Formal Logic Reasoning`
* `Verifier Observation` (accompanied by a document/checkmark icon)
5. **Verification & Model Creation:** The trace is passed to a "Verifier." This leads to two outcomes:
* **Verified:** A green checkmark points to a database icon, which then feeds into the final "SFT" process to create the **"FLV-SFT Model."**
* **Rejected:** A red "X" points to a trash can icon.
#### **Stage 2: RL (Bottom Half)**
This stage uses reinforcement learning to further train a policy model, incorporating the verifier in an online loop.
1. **Policy Model:** The stage begins with a "Policy Model" (robot icon).
2. **Interleaved Reasoning Loop:** The core is a three-step loop contained within a dashed outline:
* **Step tₙ (Natural Language Reasoning & Formal Action):** Contains the text: "Let's verify the logic using z3" followed by formal code-like statements:
```
Implies(And(both_optimal, duality_holds), both_feasible)
solver = Solver()
result = solver.check()
```
* **Step tₙ₊₁ (Verifier Observation):** Contains the question: "Are the triple iff and strong duality equivalent? False"
* **Step tₘ (Next Natural Language Reasoning):** Contains the text: "The result indicates that the triple iff structure (Both the primal LP and the dual LP have feasible solutions) <=> then..."
* These three steps are connected by arrows forming a cycle labeled **"Interleaved Reasoning Loop."**
3. **Reward & Advantage:** The output of the loop feeds into an orange block containing:
* **Correct Reward / Instruct Reward:** Represented by a dollar sign icon.
* **GRPO Advantage Aᵢ:** Represented by a line graph icon. "GRPO" likely stands for a specific reinforcement learning algorithm variant.
4. **Feedback:** A dashed arrow labeled **"Backprop"** leads from the advantage block back to the "Policy Model," completing the reinforcement learning cycle.
### Key Observations
* **Hybrid Reasoning:** The pipeline explicitly combines **Natural Language Reasoning** with **Formal Logic Reasoning** (using tools like Z3, a theorem prover mentioned in the code snippet).
* **Verification-Centric:** A "Verifier" is a central component in both stages, acting as a gatekeeper for data quality (Stage 1) and as an online critic during training (Stage 2).
* **Curriculum Learning:** Stage 1 implements a form of curriculum learning by filtering for "Difficult Questions" based on failure rate.
* **Two-Phase Training:** The model is first trained on a static, verified dataset (SFT), then further refined through dynamic interaction with a verifier in an RL loop.
* **Specific RL Algorithm:** The mention of "GRPO Advantage" suggests the use of a specific policy gradient algorithm, possibly a variant of Proximal Policy Optimization (PPO) or similar.
### Interpretation
This diagram outlines a sophisticated methodology for training AI reasoning models to be more logically rigorous and verifiable. The core innovation is the tight integration of a symbolic logic verifier into both the data curation and the online training process.
* **Purpose:** To move beyond purely statistical language modeling and instill models with the ability to perform and self-verify formal logical deductions. This is crucial for applications requiring high reliability, such as mathematical proof generation, code verification, or complex decision-making.
* **How Elements Relate:** Stage 1 creates a high-quality, verified "textbook" for the model. Stage 2 then puts the model through "interactive tutoring sessions" where it proposes reasoning steps, the verifier checks them, and the model is rewarded for correct, verifiable logic. The "Interleaved Reasoning Loop" is the key mechanism for this interactive learning.
* **Notable Implications:** The pipeline addresses a key weakness of large language models: their tendency to produce plausible-sounding but logically flawed arguments. By grounding the training in formal verification, the resulting model's reasoning should be more trustworthy and less prone to hallucination in logical domains. The use of "Difficult Questions" suggests a focus on pushing the model's capabilities on hard cases rather than easy examples.
DECODING INTELLIGENCE...