TECHNICAL ASSET FINGERPRINT
303022b80a688fb9210f370b
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
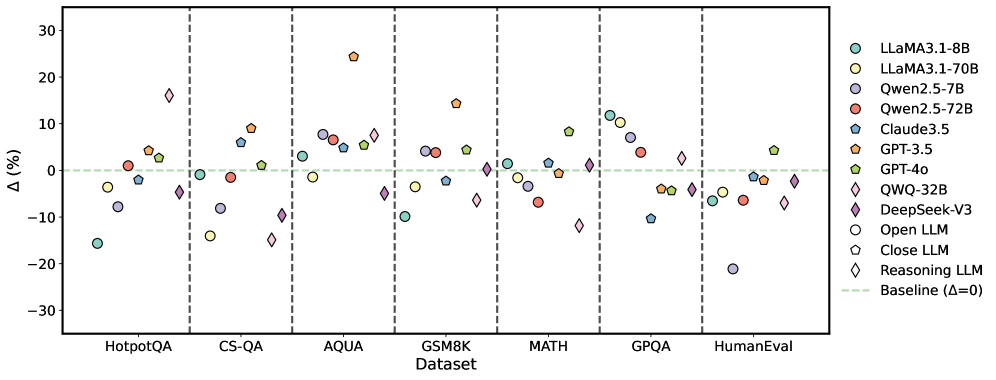
## Scatter Plot: Model Performance on Various Datasets
### Overview
The image is a scatter plot comparing the performance of various language models (LLMs) on different datasets. The y-axis represents the percentage difference (Δ (%)) from a baseline, and the x-axis represents the datasets. Each model is represented by a unique color and marker.
### Components/Axes
* **X-axis:** Datasets: HotpotQA, CS-QA, AQUA, GSM8K, MATH, GPQA, HumanEval
* **Y-axis:** Δ (%) - Percentage difference from a baseline, ranging from -30% to 30%
* **Baseline:** A horizontal dashed green line at Δ = 0%.
* **Legend (Right side):**
* Light Blue Circle: LLAMA3.1-8B
* Yellow Circle: LLAMA3.1-70B
* Purple Circle: Qwen2.5-7B
* Red Circle: Qwen2.5-72B
* Teal Pentagon: Claude3.5
* Orange Pentagon: GPT-3.5
* Green Pentagon: GPT-4o
* Light Blue Diamond: QWQ-32B
* Purple Diamond: DeepSeek-V3
* White Circle: Open LLM
* White Pentagon: Close LLM
* White Diamond: Reasoning LLM
### Detailed Analysis
Here's a breakdown of model performance on each dataset:
* **HotpotQA:**
* LLAMA3.1-8B (Light Blue Circle): Approximately -15%
* LLAMA3.1-70B (Yellow Circle): Approximately -5%
* Qwen2.5-7B (Purple Circle): Approximately -15%
* Qwen2.5-72B (Red Circle): Approximately -5%
* Claude3.5 (Teal Pentagon): Approximately 0%
* GPT-3.5 (Orange Pentagon): Approximately 1%
* GPT-4o (Green Pentagon): Approximately 0%
* QWQ-32B (Light Blue Diamond): Approximately -5%
* DeepSeek-V3 (Purple Diamond): Approximately -15%
* Open LLM (White Circle): Approximately -20%
* Close LLM (White Pentagon): Approximately -10%
* Reasoning LLM (White Diamond): Approximately -5%
* **CS-QA:**
* LLAMA3.1-8B (Light Blue Circle): Approximately -10%
* LLAMA3.1-70B (Yellow Circle): Approximately -15%
* Qwen2.5-7B (Purple Circle): Approximately -5%
* Qwen2.5-72B (Red Circle): Approximately -2%
* Claude3.5 (Teal Pentagon): Approximately 10%
* GPT-3.5 (Orange Pentagon): Approximately 10%
* GPT-4o (Green Pentagon): Approximately 5%
* QWQ-32B (Light Blue Diamond): Approximately -5%
* DeepSeek-V3 (Purple Diamond): Approximately -10%
* Open LLM (White Circle): Approximately -10%
* Close LLM (White Pentagon): Approximately -5%
* Reasoning LLM (White Diamond): Approximately -20%
* **AQUA:**
* LLAMA3.1-8B (Light Blue Circle): Approximately 0%
* LLAMA3.1-70B (Yellow Circle): Approximately 5%
* Qwen2.5-7B (Purple Circle): Approximately 5%
* Qwen2.5-72B (Red Circle): Approximately 5%
* Claude3.5 (Teal Pentagon): Approximately 5%
* GPT-3.5 (Orange Pentagon): Approximately 25%
* GPT-4o (Green Pentagon): Approximately 5%
* QWQ-32B (Light Blue Diamond): Approximately 15%
* DeepSeek-V3 (Purple Diamond): Approximately -5%
* Open LLM (White Circle): Approximately 0%
* Close LLM (White Pentagon): Approximately 0%
* Reasoning LLM (White Diamond): Approximately 15%
* **GSM8K:**
* LLAMA3.1-8B (Light Blue Circle): Approximately 0%
* LLAMA3.1-70B (Yellow Circle): Approximately 5%
* Qwen2.5-7B (Purple Circle): Approximately 5%
* Qwen2.5-72B (Red Circle): Approximately 5%
* Claude3.5 (Teal Pentagon): Approximately 10%
* GPT-3.5 (Orange Pentagon): Approximately 15%
* GPT-4o (Green Pentagon): Approximately 10%
* QWQ-32B (Light Blue Diamond): Approximately -5%
* DeepSeek-V3 (Purple Diamond): Approximately -10%
* Open LLM (White Circle): Approximately 0%
* Close LLM (White Pentagon): Approximately 0%
* Reasoning LLM (White Diamond): Approximately 0%
* **MATH:**
* LLAMA3.1-8B (Light Blue Circle): Approximately 0%
* LLAMA3.1-70B (Yellow Circle): Approximately 0%
* Qwen2.5-7B (Purple Circle): Approximately 5%
* Qwen2.5-72B (Red Circle): Approximately 5%
* Claude3.5 (Teal Pentagon): Approximately 10%
* GPT-3.5 (Orange Pentagon): Approximately 10%
* GPT-4o (Green Pentagon): Approximately 10%
* QWQ-32B (Light Blue Diamond): Approximately -5%
* DeepSeek-V3 (Purple Diamond): Approximately -5%
* Open LLM (White Circle): Approximately 0%
* Close LLM (White Pentagon): Approximately 0%
* Reasoning LLM (White Diamond): Approximately 0%
* **GPQA:**
* LLAMA3.1-8B (Light Blue Circle): Approximately -5%
* LLAMA3.1-70B (Yellow Circle): Approximately -5%
* Qwen2.5-7B (Purple Circle): Approximately -5%
* Qwen2.5-72B (Red Circle): Approximately 5%
* Claude3.5 (Teal Pentagon): Approximately 5%
* GPT-3.5 (Orange Pentagon): Approximately 5%
* GPT-4o (Green Pentagon): Approximately 5%
* QWQ-32B (Light Blue Diamond): Approximately -10%
* DeepSeek-V3 (Purple Diamond): Approximately -5%
* Open LLM (White Circle): Approximately -5%
* Close LLM (White Pentagon): Approximately -5%
* Reasoning LLM (White Diamond): Approximately 0%
* **HumanEval:**
* LLAMA3.1-8B (Light Blue Circle): Approximately -5%
* LLAMA3.1-70B (Yellow Circle): Approximately -5%
* Qwen2.5-7B (Purple Circle): Approximately -5%
* Qwen2.5-72B (Red Circle): Approximately 0%
* Claude3.5 (Teal Pentagon): Approximately 5%
* GPT-3.5 (Orange Pentagon): Approximately 5%
* GPT-4o (Green Pentagon): Approximately 5%
* QWQ-32B (Light Blue Diamond): Approximately -5%
* DeepSeek-V3 (Purple Diamond): Approximately -5%
* Open LLM (White Circle): Approximately -20%
* Close LLM (White Pentagon): Approximately -5%
* Reasoning LLM (White Diamond): Approximately -5%
### Key Observations
* GPT-3.5 and GPT-4o generally perform well across all datasets, often showing a positive percentage difference from the baseline.
* LLAMA3.1-8B and LLAMA3.1-70B tend to have lower performance, often showing a negative percentage difference.
* The performance of different models varies significantly across different datasets, indicating that some models are better suited for certain tasks than others.
* Reasoning LLM shows significant underperformance on CS-QA.
* Open LLM shows significant underperformance on HumanEval.
### Interpretation
The scatter plot provides a comparative analysis of various LLMs on different datasets. The data suggests that no single model consistently outperforms all others across all tasks. The choice of the best model depends on the specific dataset and the desired performance characteristics. The plot highlights the importance of evaluating models on a diverse set of benchmarks to understand their strengths and weaknesses. The baseline (Δ = 0) serves as a reference point to quickly assess whether a model is performing better or worse than the average. The variability in performance across datasets suggests that model architecture, training data, and fine-tuning strategies play a crucial role in determining the effectiveness of an LLM for a given task.
DECODING INTELLIGENCE...