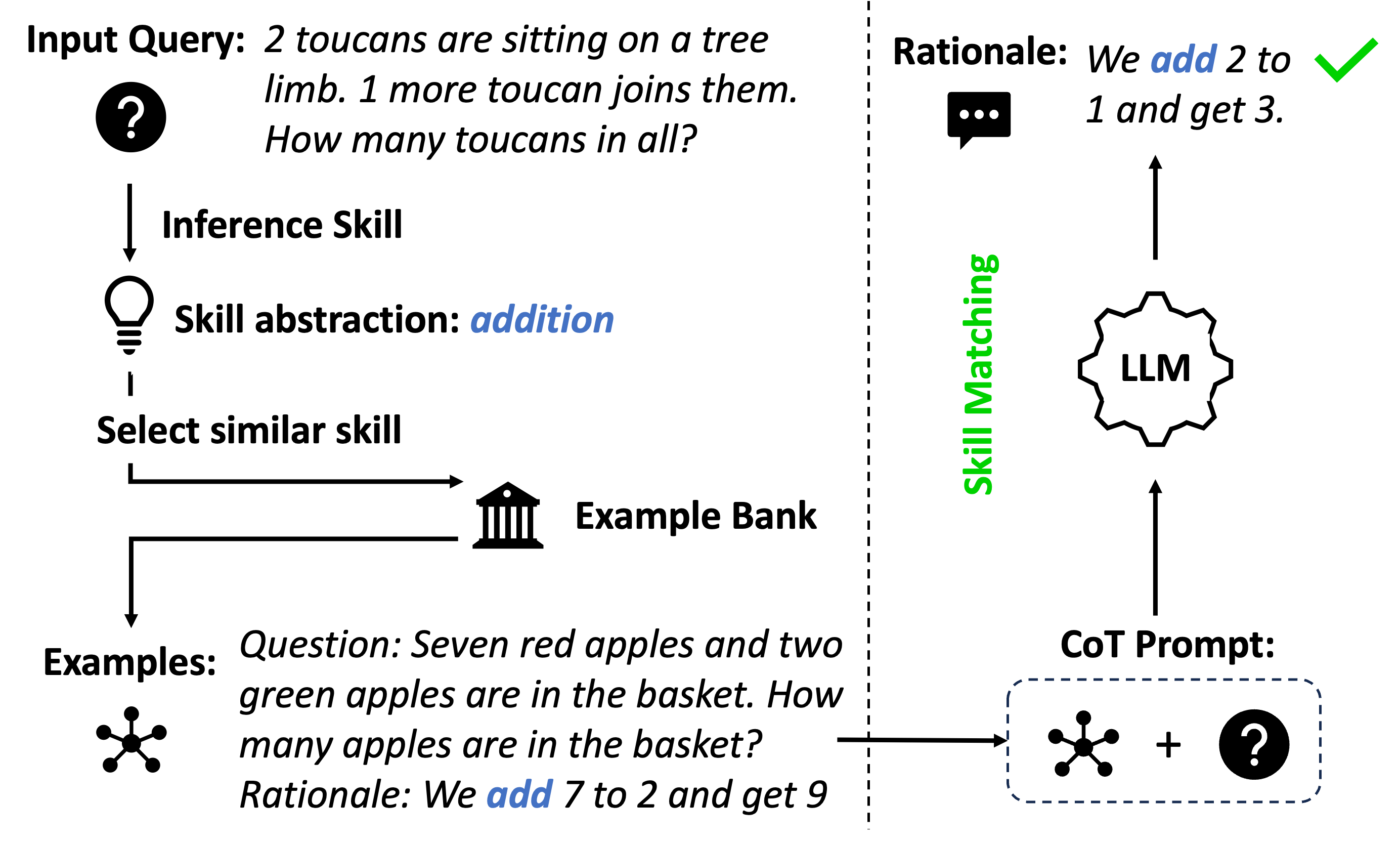
## Diagram: Skill Matching Process
### Overview
The image illustrates a skill matching process, likely within a machine learning or AI context. It shows how an input query is processed to identify a relevant skill, find similar examples, and generate a Chain-of-Thought (CoT) prompt for a Large Language Model (LLM).
### Components/Axes
* **Input Query:** "2 toucans are sitting on a tree limb. 1 more toucan joins them. How many toucans in all?"
* **Inference Skill:**
* Skill abstraction: addition
* **Select similar skill**
* **Example Bank:** Represented by a building icon.
* **Examples:**
* Question: "Seven red apples and two green apples are in the basket. How many apples are in the basket?"
* Rationale: "We add 7 to 2 and get 9"
* **CoT Prompt:** Represented by a dashed blue rounded rectangle containing an apple icon, a plus sign, and a question mark icon.
* **LLM:** Represented by a gear-like icon with "LLM" written inside.
* **Rationale:** "We add 2 to 1 and get 3."
* **Skill Matching:** Text is oriented vertically.
### Detailed Analysis or ### Content Details
1. **Input Query:** The process begins with an input query: "2 toucans are sitting on a tree limb. 1 more toucan joins them. How many toucans in all?". A question mark icon is placed next to the text.
2. **Inference Skill:** The system infers the required skill, which is "addition". This is represented by a lightbulb icon.
3. **Select similar skill:** The system selects a similar skill.
4. **Example Bank:** The system accesses an example bank, represented by a building icon.
5. **Examples:** An example question and rationale are retrieved:
* Question: "Seven red apples and two green apples are in the basket. How many apples are in the basket?"
* Rationale: "We add 7 to 2 and get 9"
6. **CoT Prompt:** A Chain-of-Thought (CoT) prompt is generated, represented by a dashed blue rounded rectangle containing an apple icon, a plus sign, and a question mark icon.
7. **LLM:** The CoT prompt is fed into a Large Language Model (LLM), represented by a gear-like icon with "LLM" written inside.
8. **Rationale:** The LLM generates a rationale: "We add 2 to 1 and get 3." A green checkmark is placed next to the text.
9. **Skill Matching:** The process of skill matching is highlighted vertically.
### Key Observations
* The diagram illustrates a process of skill matching and reasoning using an LLM.
* The process involves identifying the required skill from an input query, finding similar examples, and generating a CoT prompt.
* The LLM uses the CoT prompt to generate a rationale for the answer.
### Interpretation
The diagram demonstrates a method for solving problems by leveraging the capabilities of a Large Language Model. By identifying the underlying skill required to solve a problem and providing relevant examples, the LLM can generate a step-by-step rationale leading to the correct answer. This approach is particularly useful for tasks that require reasoning and problem-solving skills. The use of a CoT prompt helps the LLM to break down the problem into smaller, more manageable steps, leading to a more accurate and reliable solution.