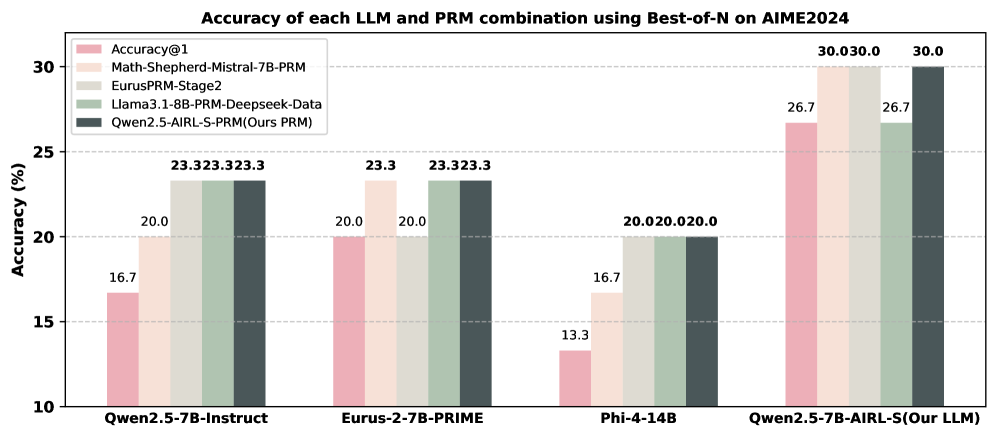
## Bar Chart: Accuracy of LLM and PRM Combinations on AIME2024
### Overview
This bar chart displays the accuracy of different Large Language Model (LLM) and Program-aided Reasoning Model (PRM) combinations when evaluated on the AIME2024 dataset, using a Best-of-N approach. Accuracy is measured as a percentage. The chart compares four different LLM/PRM combinations.
### Components/Axes
* **Title:** "Accuracy of each LLM and PRM combination using Best-of-N on AIME2024" (positioned at the top-center)
* **X-axis:** LLM/PRM combinations: "Qwen2.5-7B-Instruct", "Eurus-2-7B-PRIME", "Phi-4-14B", "Qwen2.5-7B-AIRL-S(Our LLM)" (positioned at the bottom)
* **Y-axis:** Accuracy (%) - Scale ranges from 10 to 30, with increments of 5. (positioned on the left)
* **Legend:** Located in the top-left corner, identifying the color-coded LLM/PRM combinations:
* "Accuracy@1" (light red)
* "Math-Shepherd-Mistral-7B-PRM" (light green)
* "EurusPRM-Stage2" (light blue)
* "Llama3.1-8B-PRM-Deepseek-Data" (medium green)
* "Qwen2.5-AIRL-S-PRM(Ours PRM)" (dark grey)
### Detailed Analysis
The chart consists of four groups of bars, one for each LLM/PRM combination on the x-axis. Each group contains five bars, representing the accuracy of each of the five LLM/PRM combinations.
* **Qwen2.5-7B-Instruct:**
* Accuracy@1: Approximately 16.7%
* Math-Shepherd-Mistral-7B-PRM: Approximately 20.0%
* EurusPRM-Stage2: Approximately 20.0%
* Llama3.1-8B-PRM-Deepseek-Data: Approximately 23.3%
* Qwen2.5-AIRL-S-PRM(Ours PRM): Approximately 23.3%
* **Eurus-2-7B-PRIME:**
* Accuracy@1: Approximately 20.0%
* Math-Shepherd-Mistral-7B-PRM: Approximately 23.3%
* EurusPRM-Stage2: Approximately 23.3%
* Llama3.1-8B-PRM-Deepseek-Data: Approximately 23.3%
* Qwen2.5-AIRL-S-PRM(Ours PRM): Approximately 20.0%
* **Phi-4-14B:**
* Accuracy@1: Approximately 13.3%
* Math-Shepherd-Mistral-7B-PRM: Approximately 16.7%
* EurusPRM-Stage2: Approximately 20.0%
* Llama3.1-8B-PRM-Deepseek-Data: Approximately 20.0%
* Qwen2.5-AIRL-S-PRM(Ours PRM): Approximately 20.0%
* **Qwen2.5-7B-AIRL-S(Our LLM):**
* Accuracy@1: Approximately 26.7%
* Math-Shepherd-Mistral-7B-PRM: Approximately 30.0%
* EurusPRM-Stage2: Approximately 30.0%
* Llama3.1-8B-PRM-Deepseek-Data: Approximately 26.7%
* Qwen2.5-AIRL-S-PRM(Ours PRM): Approximately 26.7%
### Key Observations
* The "Qwen2.5-7B-AIRL-S(Our LLM)" combination consistently achieves the highest accuracy across all PRM models, particularly with "Math-Shepherd-Mistral-7B-PRM" and "EurusPRM-Stage2", reaching 30.0%.
* "Phi-4-14B" consistently shows the lowest accuracy across all PRM models.
* The "Llama3.1-8B-PRM-Deepseek-Data" and "Qwen2.5-AIRL-S-PRM(Ours PRM)" combinations often yield similar accuracy scores.
* The "Accuracy@1" baseline is consistently lower than the accuracy achieved when combined with any of the PRM models.
### Interpretation
The data suggests that combining LLMs with PRM models significantly improves accuracy on the AIME2024 dataset. The "Qwen2.5-7B-AIRL-S" LLM, when paired with "Math-Shepherd-Mistral-7B-PRM" or "EurusPRM-Stage2", demonstrates the highest performance, indicating a strong synergy between these models. The consistently low performance of "Phi-4-14B" suggests it may not be as well-suited for this particular task or dataset. The improvement observed when using PRM models compared to the "Accuracy@1" baseline highlights the benefit of program-aided reasoning in enhancing LLM capabilities. The fact that the "Qwen2.5-AIRL-S-PRM(Ours PRM)" performs well, but not always the best, suggests that while the team's PRM is effective, other PRM models like "Math-Shepherd-Mistral-7B-PRM" and "EurusPRM-Stage2" may offer further improvements when combined with their LLM.