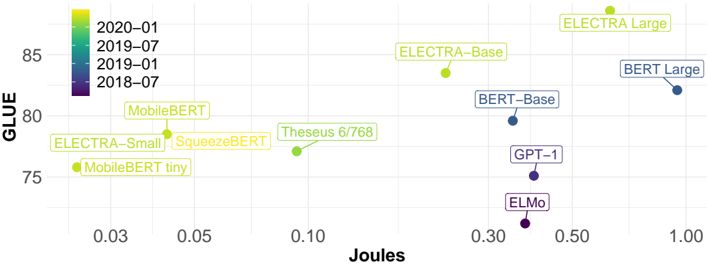
## Scatter Plot: Model Performance (GLUE vs. Joules)
### Overview
This image presents a scatter plot comparing the performance of various language models on the GLUE benchmark against their energy consumption in Joules. Each point represents a different model, and the color of the point indicates the date of the model's release.
### Components/Axes
* **X-axis:** Joules (Energy Consumption). Scale ranges from approximately 0.00 to 1.00, with markers at 0.03, 0.05, 0.10, 0.30, 0.50, and 1.00.
* **Y-axis:** GLUE (General Language Understanding Evaluation) score. Scale ranges from approximately 74 to 86, with markers at 75, 80, 85.
* **Legend:** Located in the top-left corner, the legend maps colors to dates:
* 2020-01 (Light Green)
* 2019-07 (Medium Green)
* 2019-01 (Light Blue)
* 2018-07 (Dark Purple)
* **Data Points:** Each point represents a language model, labeled with its name.
### Detailed Analysis
Here's a breakdown of the data points, their approximate coordinates, and corresponding release dates:
* **ELECTRA Large:** (0.95, 85.5). Color: Light Green (2020-01)
* **BERT Large:** (1.00, 82.5). Color: Light Blue (2019-01)
* **ELECTRA-Base:** (0.85, 84.5). Color: Light Green (2020-01)
* **BERT-Base:** (0.75, 81.5). Color: Light Blue (2019-01)
* **Theseus 6/768:** (0.12, 79.5). Color: Medium Green (2019-07)
* **SqueezeBERT:** (0.07, 77.5). Color: Medium Green (2019-07)
* **MobileBERT:** (0.04, 80.5). Color: Medium Green (2019-07)
* **ELECTRA-Small:** (0.06, 76.5). Color: Light Green (2020-01)
* **MobileBERT tiny:** (0.03, 75.5). Color: Light Green (2020-01)
* **GPT-1:** (0.40, 76.0). Color: Dark Purple (2018-07)
* **ELMo:** (0.30, 74.5). Color: Dark Purple (2018-07)
**Trends:**
* Generally, models released in 2020-01 (light green) tend to have higher GLUE scores for a given energy consumption (Joules) compared to models released earlier.
* There's a positive correlation between energy consumption and GLUE score, but it's not strictly linear. Some models achieve high GLUE scores with relatively low energy consumption.
* The older models (2018-07, dark purple) generally have lower GLUE scores and lower energy consumption.
### Key Observations
* ELECTRA Large achieves the highest GLUE score, but also has the highest energy consumption.
* MobileBERT and MobileBERT tiny are notable for their relatively high GLUE scores given their very low energy consumption.
* GPT-1 and ELMo are the oldest models and have the lowest GLUE scores.
* There is a cluster of models released in 2019-07 (medium green) that occupy a middle ground in terms of both GLUE score and energy consumption.
### Interpretation
The data suggests a trade-off between model performance (as measured by GLUE) and energy consumption. Newer models (2020-01) demonstrate improved efficiency, achieving higher GLUE scores with comparable or even lower energy consumption than older models. This indicates progress in model architecture and training techniques.
The positioning of models like MobileBERT and MobileBERT tiny is particularly interesting. They represent a design choice prioritizing efficiency over absolute performance, making them suitable for resource-constrained environments.
The spread of points indicates that simply increasing model size (and thus energy consumption) doesn't guarantee a proportional increase in GLUE score. There are diminishing returns, and other factors like model architecture and training data play a crucial role.
The color-coding by release date provides a historical perspective, showing how the landscape of language models has evolved over time. The trend towards higher performance and greater efficiency is clearly visible.