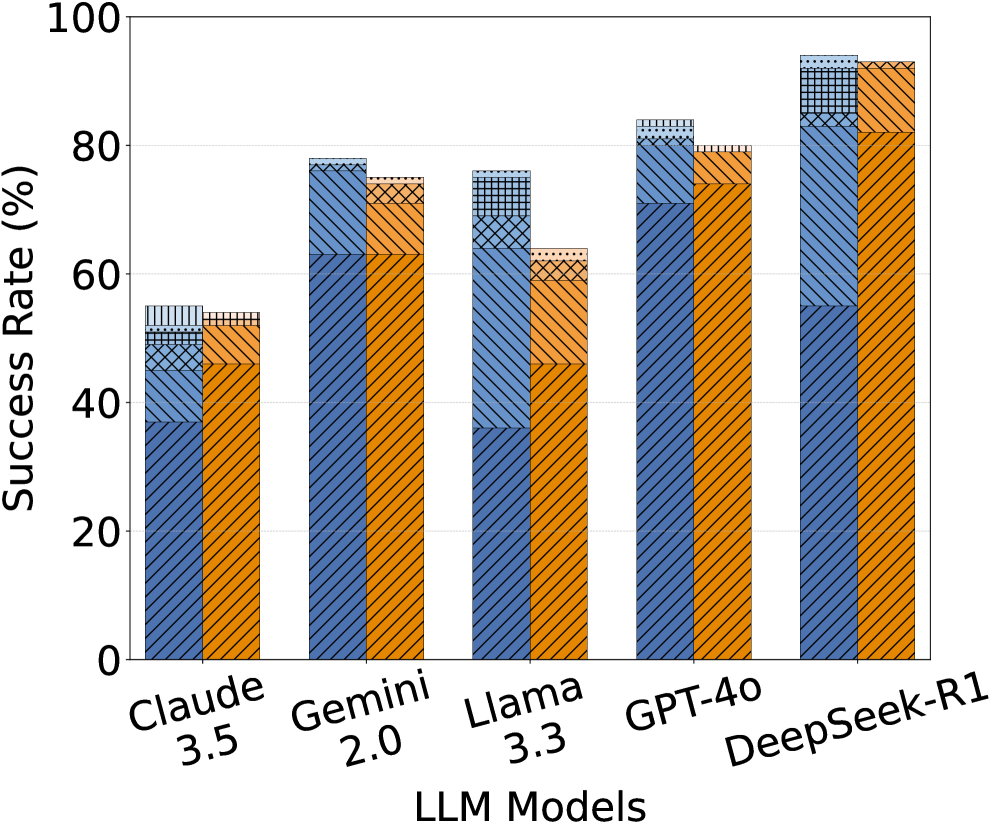
## Bar Chart: LLM Model Success Rate Comparison
### Overview
The chart compares the success rates of five large language models (LLMs) across four performance categories: Correct, Incorrect, Uncertain, and Ambiguous. Each model's performance is visualized as a stacked bar, with segmented patterns and colors representing the contribution of each category to the total success rate.
### Components/Axes
- **X-Axis (LLM Models)**: Labeled with model names and versions:
- Claude 3.5
- Gemini 2.0
- Llama 3.3
- GPT-40
- DeepSeek-R1
- **Y-Axis (Success Rate)**: Scaled from 0% to 100% in 20% increments.
- **Legend**: Located on the right, mapping colors/patterns to categories:
- **Blue (Diagonal Lines)**: Correct (正确)
- **Orange (Diagonal Lines)**: Incorrect (错误)
- **Gray (Dotted Lines)**: Uncertain (不确定)
- **Light Blue (Checkered)**: Ambiguous (模糊)
### Detailed Analysis
1. **Claude 3.5**:
- Total Success Rate: ~60%
- Breakdown:
- Correct: ~35% (blue)
- Incorrect: ~15% (orange)
- Uncertain: ~5% (gray)
- Ambiguous: ~5% (light blue)
2. **Gemini 2.0**:
- Total Success Rate: ~85%
- Breakdown:
- Correct: ~60% (blue)
- Incorrect: ~10% (orange)
- Uncertain: ~5% (gray)
- Ambiguous: ~10% (light blue)
3. **Llama 3.3**:
- Total Success Rate: ~60%
- Breakdown:
- Correct: ~35% (blue)
- Incorrect: ~10% (orange)
- Uncertain: ~10% (gray)
- Ambiguous: ~5% (light blue)
4. **GPT-40**:
- Total Success Rate: ~90%
- Breakdown:
- Correct: ~70% (blue)
- Incorrect: ~10% (orange)
- Uncertain: ~5% (gray)
- Ambiguous: ~5% (light blue)
5. **DeepSeek-R1**:
- Total Success Rate: ~100%
- Breakdown:
- Correct: ~55% (blue)
- Incorrect: ~30% (orange)
- Uncertain: ~10% (gray)
- Ambiguous: ~5% (light blue)
### Key Observations
- **DeepSeek-R1** achieves the highest total success rate (100%) but relies heavily on **Incorrect** answers (~30%), suggesting potential overconfidence or flawed evaluation metrics.
- **GPT-40** excels in **Correct** answers (~70%), driving its high total success rate (~90%).
- **Gemini 2.0** balances **Correct** answers (~60%) with moderate **Ambiguous** (~10%) and **Uncertain** (~5%) rates.
- **Claude 3.5** and **Llama 3.3** show similar total success rates (~60%), but Llama has higher **Uncertain** (~10%) and lower **Incorrect** (~10%) rates.
### Interpretation
The data highlights trade-offs in LLM performance:
- **DeepSeek-R1**'s 100% success rate is anomalous, as its **Incorrect** category dominates, raising questions about evaluation criteria or data labeling.
- **GPT-40** demonstrates reliability through high **Correct** answers, making it the most consistent performer.
- Models with higher **Uncertain**/**Ambiguous** rates (e.g., Llama 3.3) may prioritize caution over speed, impacting total success.
- The chart underscores that "success rate" is context-dependent, influenced by how models handle errors, uncertainty, and ambiguity.