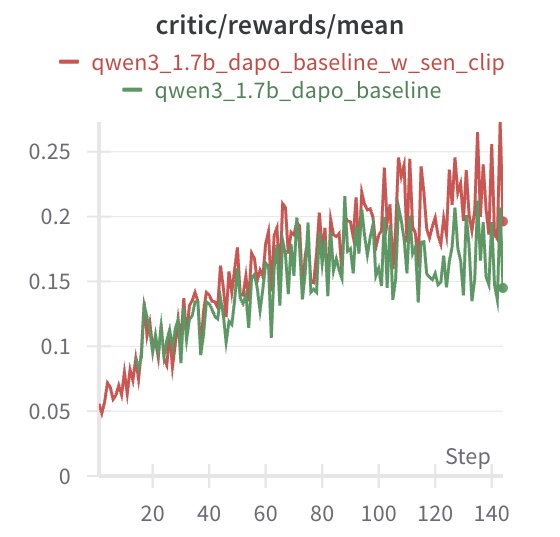
## Line Chart: Critic Rewards Mean
### Overview
The image is a line chart comparing the performance of two models, "qwen3_1.7b_dapo_baseline_w_sen_clip" and "qwen3_1.7b_dapo_baseline", based on the critic/rewards/mean metric over a number of steps. The chart displays the trend of the rewards mean for each model as the steps increase.
### Components/Axes
* **Title:** critic/rewards/mean
* **X-axis:** Step, with markers at 0, 20, 40, 60, 80, 100, 120, and 140.
* **Y-axis:** Numerical values ranging from 0 to 0.25, with markers at 0, 0.05, 0.1, 0.15, 0.2, and 0.25.
* **Legend:** Located at the top-left of the chart.
* Red line: qwen3\_1.7b\_dapo\_baseline\_w\_sen\_clip
* Green line: qwen3\_1.7b\_dapo\_baseline
### Detailed Analysis
* **qwen3\_1.7b\_dapo\_baseline\_w\_sen\_clip (Red Line):**
* The line starts at approximately 0.05 at step 0.
* The line generally slopes upward, indicating an increase in the rewards mean as the steps increase.
* The line reaches approximately 0.2 at step 80.
* The line fluctuates between 0.18 and 0.27 from step 80 to 140.
* The final value at step 140 is approximately 0.2.
* **qwen3\_1.7b\_dapo\_baseline (Green Line):**
* The line starts at approximately 0.06 at step 0.
* The line generally slopes upward, indicating an increase in the rewards mean as the steps increase.
* The line reaches approximately 0.18 at step 80.
* The line fluctuates between 0.15 and 0.22 from step 80 to 140.
* The final value at step 140 is approximately 0.15.
### Key Observations
* Both models show an increasing trend in the rewards mean as the steps increase.
* The "qwen3\_1.7b\_dapo\_baseline\_w\_sen\_clip" model (red line) generally performs better than the "qwen3\_1.7b\_dapo\_baseline" model (green line), especially after step 80.
* Both models exhibit fluctuations in their rewards mean, particularly in the later steps.
### Interpretation
The chart suggests that both models improve their performance (as measured by the critic/rewards/mean metric) as they are trained over more steps. The "qwen3\_1.7b\_dapo\_baseline\_w\_sen\_clip" model appears to be more effective than the "qwen3\_1.7b\_dapo\_baseline" model, achieving higher rewards mean values, especially in the later stages of training. The fluctuations in the rewards mean could be due to the inherent variability in the training process or the exploration-exploitation trade-off in reinforcement learning.