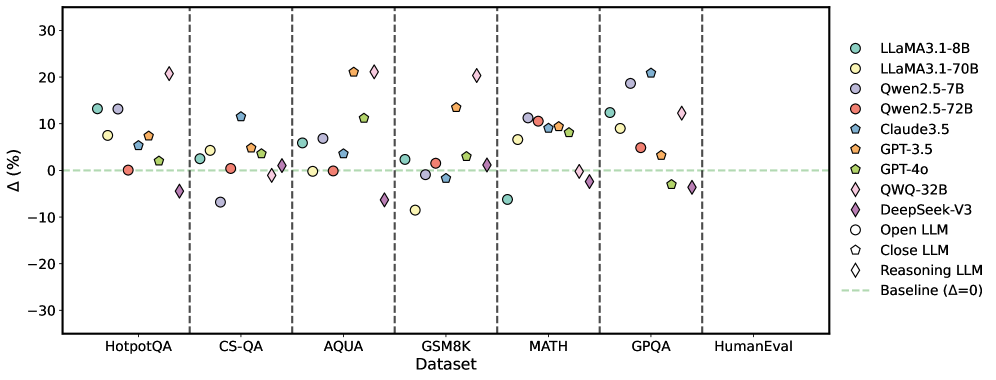
## Scatter Plot: LLM Performance on Various Datasets
### Overview
The image is a scatter plot comparing the performance of various Large Language Models (LLMs) across different datasets. The y-axis represents the percentage difference (Δ) from a baseline, and the x-axis represents the datasets. Each LLM is represented by a unique color and marker.
### Components/Axes
* **X-axis:** Datasets: HotpotQA, CS-QA, AQUA, GSM8K, MATH, GPQA, HumanEval
* **Y-axis:** Δ (%) - Percentage difference, ranging from -30 to 30, with increments of 10.
* **Legend (Right Side):**
* Light Green Circle: LLaMA3.1-8B
* Yellow Circle: LLaMA3.1-70B
* Light Purple Circle: Qwen2.5-7B
* Red Circle: Qwen2.5-72B
* Blue Pentagon: Claude3.5
* Orange Pentagon: GPT-3.5
* Green Pentagon: GPT-4o
* Yellow Diamond: QWQ-32B
* Purple Diamond: DeepSeek-V3
* White Circle: Open LLM
* Black Circle: Close LLM
* White Diamond: Reasoning LLM
* Light Green Dashed Line: Baseline (Δ=0)
* Vertical dashed lines separate the datasets.
### Detailed Analysis
Here's a breakdown of the approximate performance of each LLM on each dataset:
* **Baseline:** Represented by a light green dashed line at Δ = 0.
* **HotpotQA:**
* LLaMA3.1-8B (Light Green Circle): ~7%
* LLaMA3.1-70B (Yellow Circle): ~8%
* Qwen2.5-7B (Light Purple Circle): ~13%
* Qwen2.5-72B (Red Circle): ~1%
* Claude3.5 (Blue Pentagon): ~12%
* GPT-3.5 (Orange Pentagon): ~10%
* GPT-4o (Green Pentagon): ~7%
* QWQ-32B (Yellow Diamond): ~-5%
* DeepSeek-V3 (Purple Diamond): ~-7%
* Open LLM (White Circle): ~-3%
* Close LLM (Black Circle): ~-25%
* Reasoning LLM (White Diamond): ~-2%
* **CS-QA:**
* LLaMA3.1-8B (Light Green Circle): ~-7%
* LLaMA3.1-70B (Yellow Circle): ~-3%
* Qwen2.5-7B (Light Purple Circle): ~-7%
* Qwen2.5-72B (Red Circle): ~-1%
* Claude3.5 (Blue Pentagon): ~3%
* GPT-3.5 (Orange Pentagon): ~1%
* GPT-4o (Green Pentagon): ~-1%
* QWQ-32B (Yellow Diamond): ~-1%
* DeepSeek-V3 (Purple Diamond): ~-7%
* Open LLM (White Circle): ~-1%
* Close LLM (Black Circle): ~-1%
* Reasoning LLM (White Diamond): ~-1%
* **AQUA:**
* LLaMA3.1-8B (Light Green Circle): ~3%
* LLaMA3.1-70B (Yellow Circle): ~3%
* Qwen2.5-7B (Light Purple Circle): ~4%
* Qwen2.5-72B (Red Circle): ~0%
* Claude3.5 (Blue Pentagon): ~4%
* GPT-3.5 (Orange Pentagon): ~2%
* GPT-4o (Green Pentagon): ~3%
* QWQ-32B (Yellow Diamond): ~0%
* DeepSeek-V3 (Purple Diamond): ~-1%
* Open LLM (White Circle): ~0%
* Close LLM (Black Circle): ~0%
* Reasoning LLM (White Diamond): ~0%
* **GSM8K:**
* LLaMA3.1-8B (Light Green Circle): ~3%
* LLaMA3.1-70B (Yellow Circle): ~-7%
* Qwen2.5-7B (Light Purple Circle): ~3%
* Qwen2.5-72B (Red Circle): ~2%
* Claude3.5 (Blue Pentagon): ~5%
* GPT-3.5 (Orange Pentagon): ~15%
* GPT-4o (Green Pentagon): ~2%
* QWQ-32B (Yellow Diamond): ~-8%
* DeepSeek-V3 (Purple Diamond): ~-1%
* Open LLM (White Circle): ~-1%
* Close LLM (Black Circle): ~-1%
* Reasoning LLM (White Diamond): ~-1%
* **MATH:**
* LLaMA3.1-8B (Light Green Circle): ~9%
* LLaMA3.1-70B (Yellow Circle): ~10%
* Qwen2.5-7B (Light Purple Circle): ~10%
* Qwen2.5-72B (Red Circle): ~1%
* Claude3.5 (Blue Pentagon): ~9%
* GPT-3.5 (Orange Pentagon): ~10%
* GPT-4o (Green Pentagon): ~10%
* QWQ-32B (Yellow Diamond): ~-1%
* DeepSeek-V3 (Purple Diamond): ~-5%
* Open LLM (White Circle): ~-1%
* Close LLM (Black Circle): ~-1%
* Reasoning LLM (White Diamond): ~-1%
* **GPQA:**
* LLaMA3.1-8B (Light Green Circle): ~20%
* LLaMA3.1-70B (Yellow Circle): ~5%
* Qwen2.5-7B (Light Purple Circle): ~21%
* Qwen2.5-72B (Red Circle): ~0%
* Claude3.5 (Blue Pentagon): ~11%
* GPT-3.5 (Orange Pentagon): ~5%
* GPT-4o (Green Pentagon): ~2%
* QWQ-32B (Yellow Diamond): ~-1%
* DeepSeek-V3 (Purple Diamond): ~-4%
* Open LLM (White Circle): ~-1%
* Close LLM (Black Circle): ~-1%
* Reasoning LLM (White Diamond): ~-1%
* **HumanEval:**
* LLaMA3.1-8B (Light Green Circle): ~10%
* LLaMA3.1-70B (Yellow Circle): ~10%
* Qwen2.5-7B (Light Purple Circle): ~10%
* Qwen2.5-72B (Red Circle): ~0%
* Claude3.5 (Blue Pentagon): ~10%
* GPT-3.5 (Orange Pentagon): ~10%
* GPT-4o (Green Pentagon): ~10%
* QWQ-32B (Yellow Diamond): ~-1%
* DeepSeek-V3 (Purple Diamond): ~-1%
* Open LLM (White Circle): ~-1%
* Close LLM (Black Circle): ~-1%
* Reasoning LLM (White Diamond): ~-1%
### Key Observations
* The performance of different LLMs varies significantly across different datasets.
* Some models (e.g., QWQ-32B, DeepSeek-V3, Open LLM, Close LLM, Reasoning LLM) consistently underperform compared to others.
* LLaMA3.1-8B, LLaMA3.1-70B, Qwen2.5-7B, Claude3.5, GPT-3.5, and GPT-4o generally perform better, with variations depending on the dataset.
* Close LLM has a very low score on HotpotQA.
### Interpretation
The scatter plot visualizes the relative performance of various LLMs on different benchmark datasets. The percentage difference from the baseline (Δ) allows for a direct comparison of how much better or worse each model performs. The plot highlights the strengths and weaknesses of each model across different types of tasks represented by the datasets. For example, some models excel in mathematical reasoning (MATH dataset) while others perform better on question answering tasks (HotpotQA). The consistent underperformance of certain models suggests potential areas for improvement in their architecture or training data. The plot provides valuable insights for model selection and further research in the field of natural language processing.