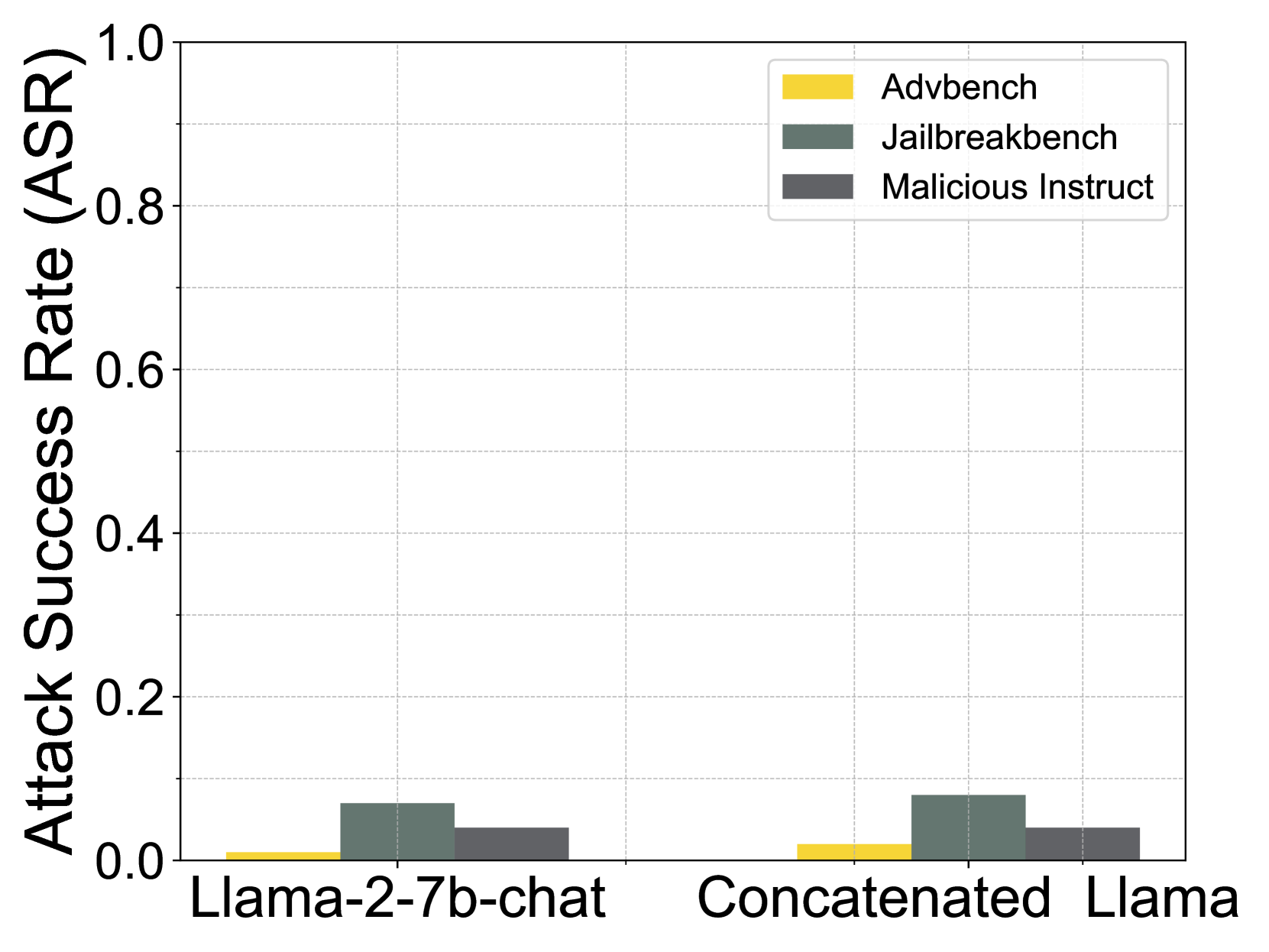
## Bar Chart: Attack Success Rate (ASR)
### Overview
The image is a bar chart comparing the attack success rate (ASR) of different attack methods (Advbench, Jailbreakbench, and Malicious Instruct) on two language models: "Llama-2-7b-chat" and "Concatenated Llama". The y-axis represents the ASR, ranging from 0.0 to 1.0. The x-axis represents the language models being attacked.
### Components/Axes
* **Y-axis:** "Attack Success Rate (ASR)" with a scale from 0.0 to 1.0 in increments of 0.2.
* **X-axis:** Categorical axis with two categories: "Llama-2-7b-chat" and "Concatenated Llama".
* **Legend:** Located in the top-right corner, it identifies the attack methods:
* Yellow: "Advbench"
* Dark Green: "Jailbreakbench"
* Dark Gray: "Malicious Instruct"
* **Gridlines:** Horizontal gridlines are present to aid in reading the ASR values.
### Detailed Analysis
**Llama-2-7b-chat:**
* **Advbench (Yellow):** ASR is approximately 0.01.
* **Jailbreakbench (Dark Green):** ASR is approximately 0.07.
* **Malicious Instruct (Dark Gray):** ASR is approximately 0.04.
**Concatenated Llama:**
* **Advbench (Yellow):** ASR is approximately 0.02.
* **Jailbreakbench (Dark Green):** ASR is approximately 0.08.
* **Malicious Instruct (Dark Gray):** ASR is approximately 0.04.
### Key Observations
* The "Jailbreakbench" attack method (Dark Green) consistently has the highest ASR for both language models.
* The "Advbench" attack method (Yellow) has the lowest ASR for both language models.
* The "Malicious Instruct" attack method (Dark Gray) has a similar ASR for both language models.
* The ASR values are generally low across all attack methods and language models, with none exceeding 0.1.
### Interpretation
The bar chart suggests that the "Llama-2-7b-chat" and "Concatenated Llama" models are relatively robust against the tested attack methods, as indicated by the low ASR values. The "Jailbreakbench" attack appears to be slightly more effective than the other two, but still achieves a low success rate. The similarity in ASR for "Malicious Instruct" across both models suggests a consistent vulnerability or resistance to this type of attack. The "Advbench" attack is the least successful, indicating that the models are relatively resistant to this specific type of adversarial input.