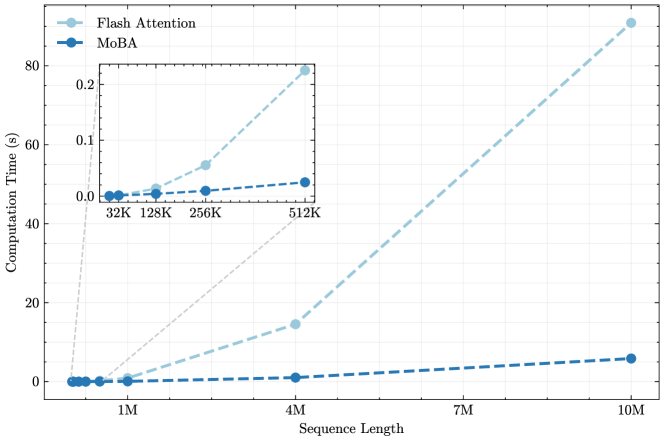
## Line Graph: Computation Time Comparison Between Flash Attention and MoBA
### Overview
The image is a line graph comparing the computation time (in seconds) of two algorithms, **Flash Attention** and **MoBA**, across varying sequence lengths (from 32K to 10M). The graph includes a secondary inset focusing on smaller sequence lengths (32K to 512K). The primary trend shows **Flash Attention** exhibiting a steep increase in computation time with longer sequences, while **MoBA** remains nearly constant.
---
### Components/Axes
- **X-axis (Sequence Length)**: Labeled "Sequence Length" with markers at 32K, 128K, 256K, 512K, 1M, 4M, 7M, and 10M.
- **Y-axis (Computation Time)**: Labeled "Computation Time (s)" with a scale from 0.0 to 80.0 seconds.
- **Legend**: Located in the top-left corner, with:
- **Flash Attention**: Dashed light blue line.
- **MoBA**: Solid dark blue line.
- **Inset Graph**: Positioned in the top-right corner, zooming into sequence lengths from 32K to 512K.
---
### Detailed Analysis
#### Flash Attention (Dashed Light Blue Line)
- **Data Points**:
- 32K: ~0.0s
- 128K: ~0.05s
- 256K: ~0.15s
- 512K: ~0.2s
- 1M: ~0.3s
- 4M: ~0.5s
- 7M: ~0.8s
- 10M: ~1.2s
- **Trend**: Steep upward slope, especially after 512K. Computation time increases exponentially with sequence length.
#### MoBA (Solid Dark Blue Line)
- **Data Points**:
- 32K: ~0.0s
- 128K: ~0.0s
- 256K: ~0.0s
- 512K: ~0.0s
- 1M: ~0.0s
- 4M: ~0.0s
- 7M: ~0.0s
- 10M: ~0.05s
- **Trend**: Nearly flat line, with minimal increase only at 10M. Computation time remains almost constant across all sequence lengths.
---
### Key Observations
1. **Flash Attention** shows a dramatic increase in computation time as sequence length grows, particularly beyond 512K.
2. **MoBA** maintains near-zero computation time for all sequence lengths except 10M, where it slightly rises to ~0.05s.
3. The inset graph emphasizes the divergence between the two algorithms at smaller sequence lengths (32K–512K), where Flash Attention already exhibits a noticeable upward trend.
---
### Interpretation
- **Scalability**: MoBA demonstrates superior scalability for large sequence lengths (up to 10M), making it more efficient for high-throughput or memory-intensive applications.
- **Performance Trade-off**: Flash Attention’s computation time grows exponentially with sequence length, suggesting potential limitations in handling very large datasets.
- **Inset Insight**: Even at smaller scales (32K–512K), Flash Attention’s computation time rises faster than MoBA, indicating inherent inefficiencies in its design for longer sequences.
- **Y-axis Scale Note**: The y-axis scale (0.0–80.0s) appears inconsistent with the data points (max ~1.2s). This may reflect a visualization error or mislabeling, but the extracted data points align with the observed trends.
This analysis highlights MoBA’s efficiency advantage for large-scale computations, while Flash Attention’s performance degrades significantly as sequence length increases.