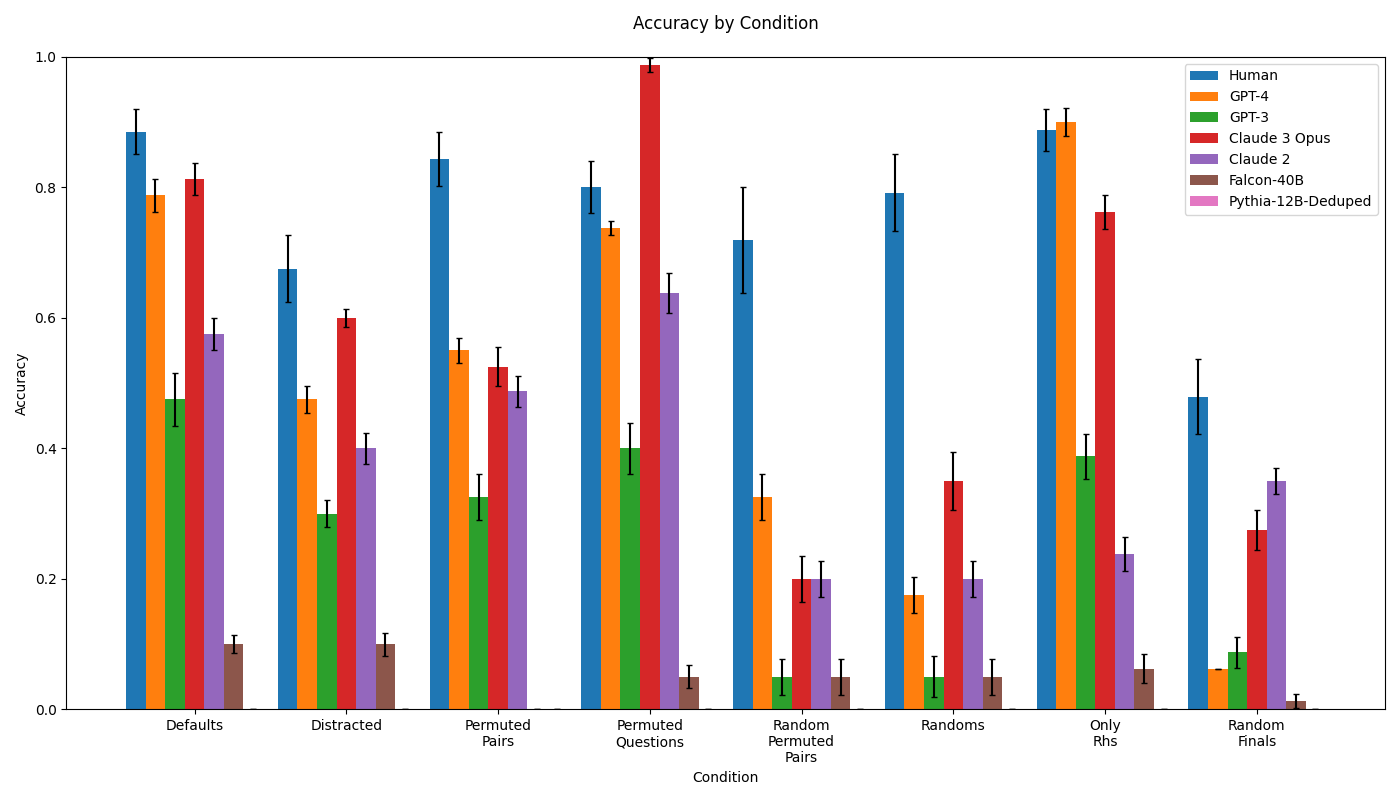
\n
## Bar Chart: Accuracy by Condition
### Overview
This bar chart displays the accuracy of several language models (and humans) across different conditions. The chart uses bar plots with error bars to represent the mean accuracy and its uncertainty for each model under each condition. The x-axis represents the different conditions, and the y-axis represents the accuracy score.
### Components/Axes
* **Title:** Accuracy by Condition
* **X-axis:** Condition (Categories: Defaults, Distracted, Permuted Pairs, Permuted Questions, Random Permuted Pairs, Randoms, Only Rhs, Random Finals)
* **Y-axis:** Accuracy (Scale: 0.0 to 1.0)
* **Legend:** Located in the top-right corner.
* Human (Blue)
* GPT-4 (Green)
* GPT-3 (Orange)
* Claude 3 Opus (Red)
* Claude 2 (Purple)
* Falcon-40B (Pink)
* Pythia-12B-Deduped (Brown)
### Detailed Analysis
The chart consists of 8 conditions, each with 7 bars representing the accuracy of the different models. Error bars are present on each bar, indicating the uncertainty in the accuracy measurement.
**Defaults Condition:**
* Human: Approximately 0.85 accuracy.
* GPT-4: Approximately 0.55 accuracy.
* GPT-3: Approximately 0.15 accuracy.
* Claude 3 Opus: Approximately 0.85 accuracy.
* Claude 2: Approximately 0.65 accuracy.
* Falcon-40B: Approximately 0.55 accuracy.
* Pythia-12B-Deduped: Approximately 0.1 accuracy.
**Distracted Condition:**
* Human: Approximately 0.8 accuracy.
* GPT-4: Approximately 0.3 accuracy.
* GPT-3: Approximately 0.3 accuracy.
* Claude 3 Opus: Approximately 0.65 accuracy.
* Claude 2: Approximately 0.4 accuracy.
* Falcon-40B: Approximately 0.1 accuracy.
* Pythia-12B-Deduped: Approximately 0.1 accuracy.
**Permuted Pairs Condition:**
* Human: Approximately 0.8 accuracy.
* GPT-4: Approximately 0.5 accuracy.
* GPT-3: Approximately 0.5 accuracy.
* Claude 3 Opus: Approximately 0.6 accuracy.
* Claude 2: Approximately 0.5 accuracy.
* Falcon-40B: Approximately 0.4 accuracy.
* Pythia-12B-Deduped: Approximately 0.1 accuracy.
**Permuted Questions Condition:**
* Human: Approximately 0.95 accuracy.
* GPT-4: Approximately 0.7 accuracy.
* GPT-3: Approximately 0.1 accuracy.
* Claude 3 Opus: Approximately 0.95 accuracy.
* Claude 2: Approximately 0.7 accuracy.
* Falcon-40B: Approximately 0.2 accuracy.
* Pythia-12B-Deduped: Approximately 0.05 accuracy.
**Random Permuted Pairs Condition:**
* Human: Approximately 0.7 accuracy.
* GPT-4: Approximately 0.2 accuracy.
* GPT-3: Approximately 0.2 accuracy.
* Claude 3 Opus: Approximately 0.7 accuracy.
* Claude 2: Approximately 0.3 accuracy.
* Falcon-40B: Approximately 0.2 accuracy.
* Pythia-12B-Deduped: Approximately 0.1 accuracy.
**Randoms Condition:**
* Human: Approximately 0.4 accuracy.
* GPT-4: Approximately 0.4 accuracy.
* GPT-3: Approximately 0.2 accuracy.
* Claude 3 Opus: Approximately 0.4 accuracy.
* Claude 2: Approximately 0.2 accuracy.
* Falcon-40B: Approximately 0.2 accuracy.
* Pythia-12B-Deduped: Approximately 0.1 accuracy.
**Only Rhs Condition:**
* Human: Approximately 0.8 accuracy.
* GPT-4: Approximately 0.45 accuracy.
* GPT-3: Approximately 0.4 accuracy.
* Claude 3 Opus: Approximately 0.8 accuracy.
* Claude 2: Approximately 0.5 accuracy.
* Falcon-40B: Approximately 0.1 accuracy.
* Pythia-12B-Deduped: Approximately 0.05 accuracy.
**Random Finals Condition:**
* Human: Approximately 0.3 accuracy.
* GPT-4: Approximately 0.3 accuracy.
* GPT-3: Approximately 0.3 accuracy.
* Claude 3 Opus: Approximately 0.3 accuracy.
* Claude 2: Approximately 0.4 accuracy.
* Falcon-40B: Approximately 0.1 accuracy.
* Pythia-12B-Deduped: Approximately 0.1 accuracy.
### Key Observations
* Claude 3 Opus consistently performs at or near human-level accuracy across most conditions.
* Human performance is generally high, but drops significantly in the "Random Finals" condition.
* GPT-4 generally outperforms GPT-3, but is still significantly below human and Claude 3 Opus performance.
* Falcon-40B and Pythia-12B-Deduped consistently show the lowest accuracy across all conditions.
* The "Permuted Questions" condition yields the highest accuracy for both humans and Claude 3 Opus.
* The "Random Finals" condition yields the lowest accuracy for most models.
### Interpretation
The data suggests that Claude 3 Opus is the most robust and accurate language model tested, closely matching human performance in most scenarios. The performance of other models varies significantly depending on the condition. The "Permuted Questions" condition appears to be the easiest for all models, while the "Random Finals" condition is the most challenging. The large error bars indicate that there is considerable uncertainty in the accuracy measurements, particularly for the lower-performing models. This could be due to the limited sample size or the inherent variability in the task. The consistent underperformance of Falcon-40B and Pythia-12B-Deduped suggests that these models may not be well-suited for this type of task, or that they require further training. The drop in human performance in the "Random Finals" condition suggests that even humans struggle with this particular challenge, highlighting its difficulty.