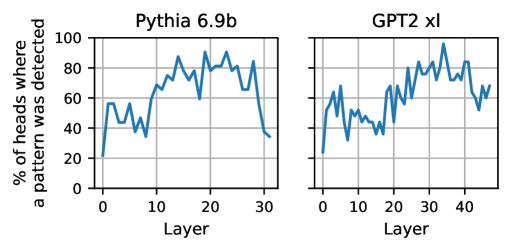
## Line Charts: Pattern Detection Across Neural Network Layers
### Overview
The image displays two side-by-side line charts comparing the percentage of attention heads where a specific pattern was detected across the layers of two different large language models: "Pythia 6.9b" (left) and "GPT2 xl" (right). The charts share a common y-axis label but have independent x-axes representing the layer number for each model.
### Components/Axes
* **Chart Titles:**
* Left Chart: "Pythia 6.9b"
* Right Chart: "GPT2 xl"
* **Y-Axis (Shared):**
* **Label:** "% of heads where a pattern was detected"
* **Scale:** Linear, from 0 to 100.
* **Tick Marks:** 0, 20, 40, 60, 80, 100.
* **X-Axes (Independent):**
* **Label (Both):** "Layer"
* **Pythia 6.9b Scale:** Linear, from 0 to 30. Tick marks at 0, 10, 20, 30.
* **GPT2 xl Scale:** Linear, from 0 to 40. Tick marks at 0, 10, 20, 30, 40.
* **Data Series:** A single blue line in each chart.
* **Grid:** Light gray grid lines are present for both major x and y ticks.
* **Spatial Layout:** The two charts are positioned horizontally adjacent. The shared y-axis label is positioned vertically to the left of both charts.
### Detailed Analysis
**Chart 1: Pythia 6.9b (Left)**
* **Trend:** The line shows a general increase from the first layer to a peak in the middle layers, followed by a sharp decline in the final layers.
* **Data Points (Approximate):**
* Layer 0: ~20%
* Layer 5: ~55% (local peak)
* Layer 10: ~40% (local trough)
* Layer 15: ~85% (high plateau begins)
* Layer 20: ~90% (approximate global peak)
* Layer 25: ~80%
* Layer 30: ~40% (sharp decline)
* Layer 31 (final point): ~35%
**Chart 2: GPT2 xl (Right)**
* **Trend:** The line is more volatile than the Pythia chart. It shows an overall upward trend with significant fluctuations, reaching a peak in the later third of the layers before a moderate decline.
* **Data Points (Approximate):**
* Layer 0: ~20%
* Layer 5: ~65% (early peak)
* Layer 10: ~45% (trough)
* Layer 15: ~50%
* Layer 20: ~70%
* Layer 25: ~80%
* Layer 30: ~85%
* Layer 35: ~95% (approximate global peak)
* Layer 40: ~70%
* Layer 44 (final point): ~70%
### Key Observations
1. **Common Starting Point:** Both models begin with approximately 20% of heads detecting the pattern at Layer 0.
2. **Peak Location:** The peak detection rate occurs at different depths. For Pythia 6.9b, it's around Layer 20 (middle). For GPT2 xl, it's around Layer 35 (later third).
3. **Post-Peak Behavior:** Pythia 6.9b exhibits a dramatic and steep decline after its peak, falling below 40% by its final layer. GPT2 xl's decline is less severe, ending at a higher percentage (~70%).
4. **Volatility:** The GPT2 xl line shows more pronounced ups and downs between layers compared to the relatively smoother ascent and descent of the Pythia line.
5. **Model Depth:** The x-axes indicate the models have different numbers of layers being analyzed (Pythia ~31, GPT2 xl ~44).
### Interpretation
This visualization suggests a fundamental difference in how the two models organize information processing across their layers regarding the specific, unnamed pattern being measured.
* **Pythia 6.9b** demonstrates a "mid-layer specialization" pattern. The pattern is most strongly and consistently detected in the central processing layers (15-25), implying these layers are crucial for the feature or concept the pattern represents. The sharp drop-off in later layers suggests this information is either transformed into a different representation or becomes less uniformly distributed across attention heads as the model prepares its final output.
* **GPT2 xl** shows a "late-layer specialization" with higher volatility. The pattern detection climbs more gradually and erratically, peaking much deeper in the network. This could indicate a more distributed or hierarchical processing where the pattern becomes most salient only after extensive integration of information. The less severe final drop-off might mean the pattern remains more relevant to the model's final output stages.
The stark contrast in the final layers is particularly noteworthy. It raises questions about the models' architectures or training objectives: Does Pythia 6.9b discard this pattern information more aggressively for downstream tasks? Does GPT2 xl retain it as a more persistent feature? Without knowing the specific "pattern" (e.g., a syntactic rule, a semantic concept, a positional bias), the exact implication remains speculative, but the data clearly shows the models have learned fundamentally different internal strategies for handling it.