\n
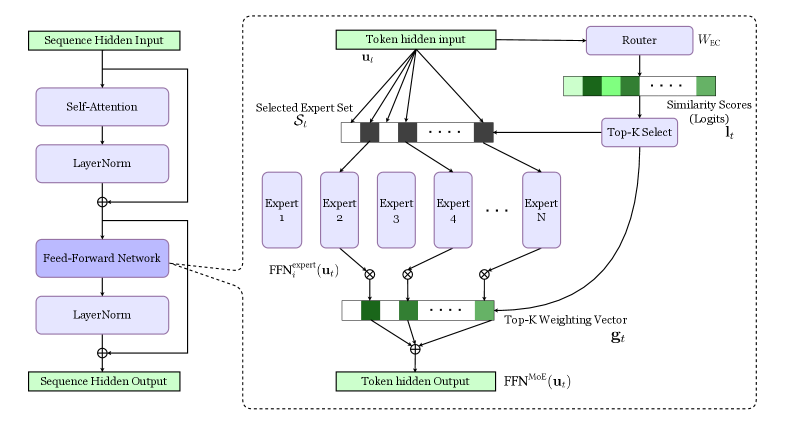
## Diagram: Mixture of Experts (MoE) Layer Architecture
### Overview
The image depicts the architecture of a Mixture of Experts (MoE) layer within a neural network. It illustrates how a token hidden input is routed to a selected set of experts, processed by those experts, and then combined to produce a token hidden output. The diagram highlights the key components involved in this process, including the router, experts, and weighting mechanism.
### Components/Axes
The diagram can be divided into three main sections:
1. **Left Side:** Standard Feed-Forward Network block. Includes "Sequence Hidden Input", "Self-Attention", "LayerNorm", "Feed-Forward", "LayerNorm", and "Sequence Hidden Output".
2. **Right Side (within dashed box):** MoE Layer. Contains "Token hidden input u<sub>t</sub>", "Router", "Selected Expert Set S<sub>t</sub>", "Expert 1" through "Expert N", "FFN<sup>expert</sup>(u<sub>t</sub>)", "Top-K Weighting Vector g<sub>t</sub>", and "Token hidden Output FFN<sup>MoE</sup>(u<sub>t</sub>)".
3. **Connections:** Arrows indicating the flow of data between components.
Key labels include:
* **Sequence Hidden Input:** The input to the initial feed-forward network.
* **Self-Attention:** A component within the feed-forward network.
* **LayerNorm:** Layer Normalization, used in both the standard and MoE blocks.
* **Feed-Forward:** A standard feed-forward network.
* **Token hidden input u<sub>t</sub>:** The input to the MoE layer.
* **Router:** The component responsible for routing the input to the experts.
* **W<sub>EC</sub>:** Weight matrix for the router.
* **Similarity Scores (Logits) l<sub>t</sub>:** The scores produced by the router, indicating the relevance of each expert.
* **Top-K Select:** The selection of the top K experts based on the similarity scores.
* **Selected Expert Set S<sub>t</sub>:** The set of experts selected by the router.
* **Expert 1…Expert N:** The individual expert networks.
* **FFN<sup>expert</sup>(u<sub>t</sub>):** The output of each expert network.
* **Top-K Weighting Vector g<sub>t</sub>:** The weights assigned to each selected expert.
* **Token hidden Output FFN<sup>MoE</sup>(u<sub>t</sub>):** The final output of the MoE layer.
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. A "Sequence Hidden Input" passes through a standard feed-forward network consisting of "Self-Attention", "LayerNorm", "Feed-Forward", and another "LayerNorm" to produce a "Sequence Hidden Output".
2. The "Token hidden input u<sub>t</sub>" enters the MoE layer.
3. The "Router" processes the input and generates "Similarity Scores (Logits) l<sub>t</sub>" for each expert.
4. "Top-K Select" chooses the top K experts based on these scores, forming the "Selected Expert Set S<sub>t</sub>".
5. The input "u<sub>t</sub>" is fed to each expert in the selected set, resulting in "FFN<sup>expert</sup>(u<sub>t</sub>)" outputs.
6. A "Top-K Weighting Vector g<sub>t</sub>" is calculated, assigning weights to each expert's output.
7. The weighted outputs of the experts are combined to produce the final "Token hidden Output FFN<sup>MoE</sup>(u<sub>t</sub>)".
8. The "Token hidden Output" is then added to the "Sequence Hidden Output" from the left side of the diagram.
The diagram uses circular nodes to represent operations and rectangular blocks to represent data or sets of data. The plus signs (+) indicate element-wise addition. The connections between components are represented by arrows.
### Key Observations
The MoE layer introduces sparsity by only activating a subset of experts for each input token. The router plays a crucial role in determining which experts are most relevant. The weighting vector allows for a soft combination of the experts' outputs, rather than a hard selection. The diagram clearly shows the parallel processing of the input by multiple experts.
### Interpretation
This diagram demonstrates a key architectural component in scaling large language models – the Mixture of Experts layer. By distributing the computational load across multiple experts, MoE layers enable models to increase their capacity without a proportional increase in computational cost during inference. The router acts as a dynamic load balancer, directing each input to the most appropriate experts. This approach allows the model to specialize in different aspects of the data, leading to improved performance. The use of a weighting vector suggests that the model can leverage the knowledge of multiple experts simultaneously, rather than relying on a single best expert. The diagram highlights the modularity and scalability of this architecture, making it well-suited for handling complex and diverse datasets. The addition operation at the end suggests a residual connection, a common technique for improving training stability and performance in deep neural networks.