TECHNICAL ASSET FINGERPRINT
35ab8fcb86fb5d95fcbceba3
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
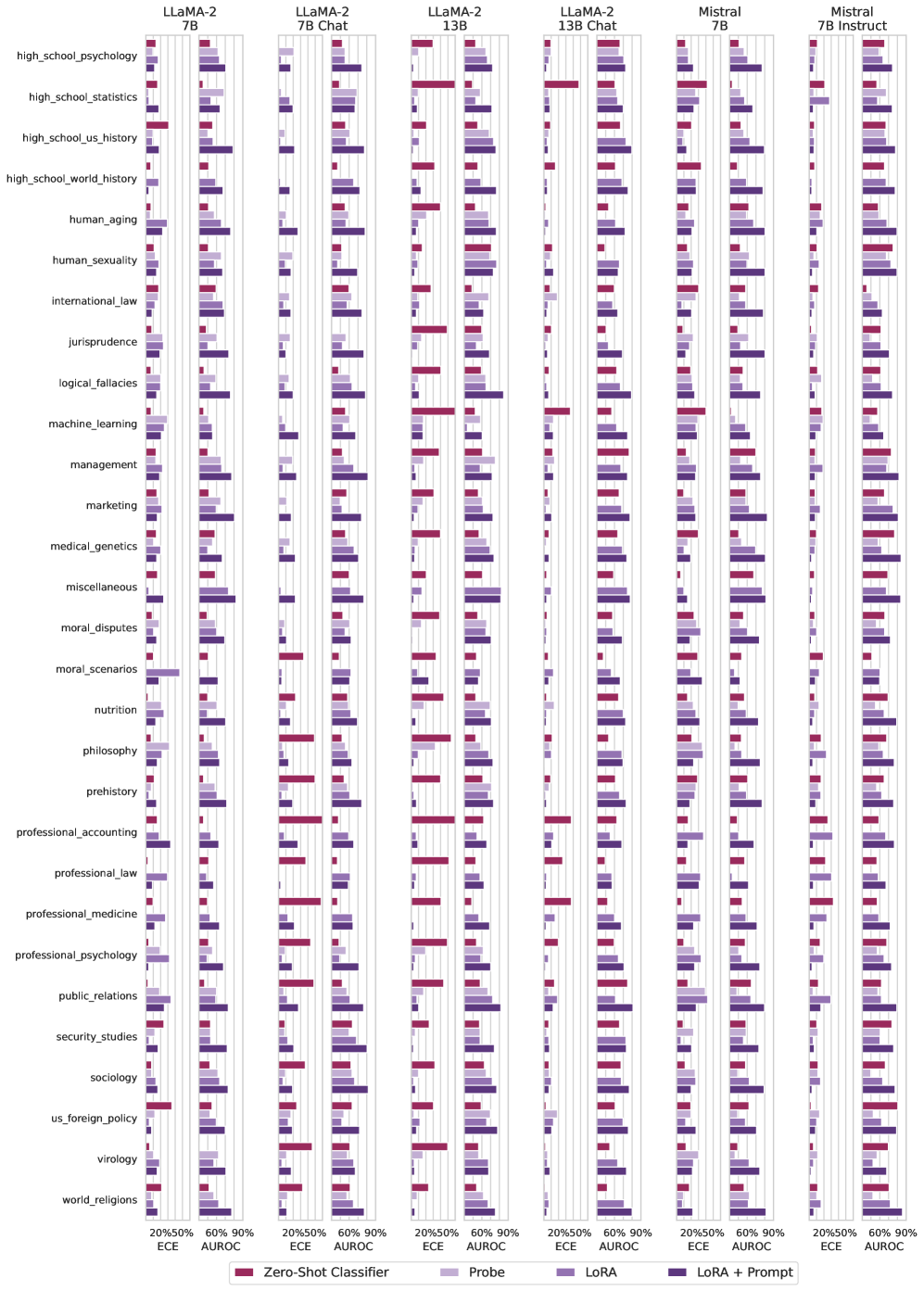
## Heatmap: Model Performance Across Topics
### Overview
This image presents a heatmap comparing the performance of several Large Language Models (LLMs) – LLaMA-2 7B, LLaMA-2 7B Chat, LLaMA-2 13B, LLaMA-2 13B Chat, Mistral 7B, and Mistral 7B Instruct – across 22 different topics. Performance is measured using four metrics: Zero-Shot Classifier, Probe, LoRA, and LoRA + Prompt. The heatmap uses color intensity to represent performance levels, ranging from approximately 20% to 90%.
### Components/Axes
* **Y-axis (Vertical):** Lists 22 topics: high_school_psychology, high_school_statistics, high_school_us_history, high_school_world_history, human_aging, human_sexuality, international_law, jurisprudence, logical_fallacies, machine_learning, management, marketing, medical_genetics, miscellaneous, moral_disputes, moral_scenarios, nutrition, philosophy, prehistory, professional_accounting, professional_law, professional_medicine, professional_psychology, public_relations, native_studies, sociology, us_foreign_policy, virology, world_religions.
* **X-axis (Horizontal):** Represents the six LLMs being compared: LLaMA-2 7B, LLaMA-2 7B Chat, LLaMA-2 13B, LLaMA-2 13B Chat, Mistral 7B, Mistral 7B Instruct.
* **Color Scale (Bottom):** Indicates performance levels. The scale ranges from approximately 20% to 90%, with darker shades of purple representing higher performance. The scale is segmented into ECE and AUROC.
* **Legend (Bottom-Center):** Defines the color coding for the four performance metrics:
* Zero-Shot Classifier (Dark Purple)
* Probe (Purple)
* LoRA (Medium Purple)
* LoRA + Prompt (Light Purple)
### Detailed Analysis
The heatmap is structured as a grid, with each cell representing the performance of a specific model on a specific topic using a specific metric. I will analyze each model and metric individually, noting trends. All values are approximate due to the visual nature of the data.
**LLaMA-2 7B:**
* **Zero-Shot Classifier:** Generally performs in the 20%-50% range across most topics, with a slight peak around 60% for high_school_us_history.
* **Probe:** Shows slightly better performance, generally between 40%-70%, peaking around 70% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 60%-85%, with peaks around 80-85% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**LLaMA-2 7B Chat:**
* **Zero-Shot Classifier:** Similar to LLaMA-2 7B, generally 20%-50%, with some peaks around 60%.
* **Probe:** Slightly better, 40%-70%, with peaks around 70% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves to 60%-85%, peaking around 80-85% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, 70%-90%, peaking around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**LLaMA-2 13B:**
* **Zero-Shot Classifier:** Generally performs better than the 7B models, ranging from 30%-60% across most topics.
* **Probe:** Shows improvement, generally 50%-80%, peaking around 80% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 80%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**LLaMA-2 13B Chat:**
* **Zero-Shot Classifier:** Similar to LLaMA-2 13B, generally 30%-60% across most topics.
* **Probe:** Shows improvement, generally 50%-80%, peaking around 80% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 80%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**Mistral 7B:**
* **Zero-Shot Classifier:** Generally performs in the 30%-60% range.
* **Probe:** Shows improvement, generally 50%-80%, peaking around 80% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 80%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**Mistral 7B Instruct:**
* **Zero-Shot Classifier:** Generally performs in the 30%-60% range.
* **Probe:** Shows improvement, generally 50%-80%, peaking around 80% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 80%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**General Trends:**
* Performance consistently improves as you move from Zero-Shot Classifier to Probe, LoRA, and finally LoRA + Prompt.
* The 13B models generally outperform the 7B models.
* High school history topics (US and World) consistently show the highest performance across all models and metrics.
* Topics like human sexuality, jurisprudence, and prehistory tend to have lower performance scores.
### Key Observations
* The addition of LoRA and especially LoRA + Prompt significantly boosts performance across all models and topics.
* The difference in performance between the 7B and 13B models is noticeable, particularly with the more advanced training methods (LoRA and LoRA + Prompt).
* There is considerable variation in performance across different topics, suggesting that some topics are inherently more challenging for these models.
* Mistral models perform comparably to the LLaMA-2 models.
### Interpretation
This heatmap demonstrates the impact of different training techniques (Zero-Shot, Probe, LoRA, LoRA + Prompt) on the performance of various LLMs across a diverse set of topics. The consistent improvement with each successive training method highlights the effectiveness of fine-tuning and prompt engineering. The superior performance of the 13B models suggests that model size plays a crucial role in achieving higher accuracy. The topic-specific variations indicate that the models' knowledge and reasoning abilities are not uniform across all domains. The strong performance on high school history topics could be attributed to the abundance of readily available and well-structured information on these subjects. Conversely, lower performance on topics like human sexuality and jurisprudence might reflect the complexity, nuance, and potential biases associated with these areas. The data suggests that while LLMs are becoming increasingly capable, they still require significant fine-tuning and careful prompt design to achieve optimal performance, and their performance is heavily influenced by the nature of the task and the available training data. The heatmap provides a valuable comparative analysis for selecting the most appropriate model and training strategy for a given application.
DECODING INTELLIGENCE...