## Diagram: Text-Knowledge Fusion Module
### Overview
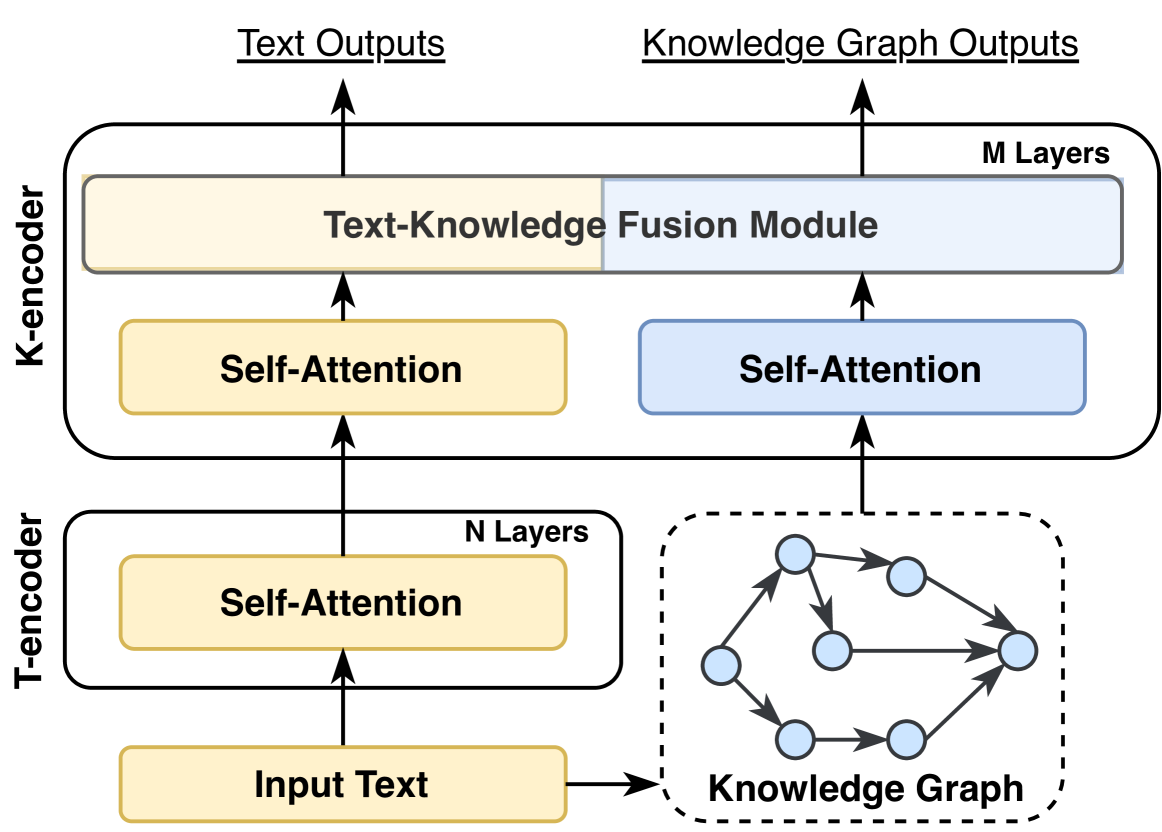
The image is a diagram illustrating a Text-Knowledge Fusion Module, showing the flow of information from input text and a knowledge graph through T-encoders and K-encoders, ultimately producing text outputs and knowledge graph outputs.
### Components/Axes
* **T-encoder:** Located on the left side of the diagram.
* **N Layers:** Indicates the number of layers in the T-encoder.
* **Input Text:** The initial input to the T-encoder.
* **Self-Attention:** A processing block within the T-encoder.
* **K-encoder:** Located on the left side of the diagram.
* **M Layers:** Indicates the number of layers in the K-encoder.
* **Text-Knowledge Fusion Module:** A module that combines information from both the T-encoder and the K-encoder.
* **Self-Attention:** Processing blocks within the K-encoder.
* **Knowledge Graph:** Located on the right side of the diagram.
* A network of nodes and edges representing relationships between concepts.
* **Text Outputs:** The final output derived from the text input. Located at the top-left.
* **Knowledge Graph Outputs:** The final output derived from the knowledge graph. Located at the top-right.
### Detailed Analysis
* **Input Text:** The "Input Text" block feeds into a "Self-Attention" block within the T-encoder.
* **Knowledge Graph:** The "Knowledge Graph" feeds into a "Self-Attention" block within the K-encoder. The knowledge graph is represented by a dashed-line box containing a network of nodes (circles) connected by directed edges (arrows).
* **T-encoder and K-encoder:** The outputs of the "Self-Attention" blocks in both the T-encoder and K-encoder are fed into the "Text-Knowledge Fusion Module".
* **Outputs:** The "Text-Knowledge Fusion Module" produces both "Text Outputs" and "Knowledge Graph Outputs".
### Key Observations
* The diagram highlights the fusion of text and knowledge graph information.
* Self-attention mechanisms are used in both the T-encoder and K-encoder.
* The number of layers in the T-encoder (N) and K-encoder (M) are explicitly noted, suggesting their importance.
### Interpretation
The diagram illustrates a system that leverages both text and a knowledge graph to generate outputs. The T-encoder processes the input text, while the K-encoder processes the knowledge graph. The "Text-Knowledge Fusion Module" combines the information from both encoders, allowing the system to generate outputs that are informed by both textual data and structured knowledge. The use of self-attention mechanisms suggests that the system is designed to capture long-range dependencies within both the text and the knowledge graph. The separation of the encoders into N and M layers suggests that the depth of processing for each input type can be independently configured.