\n
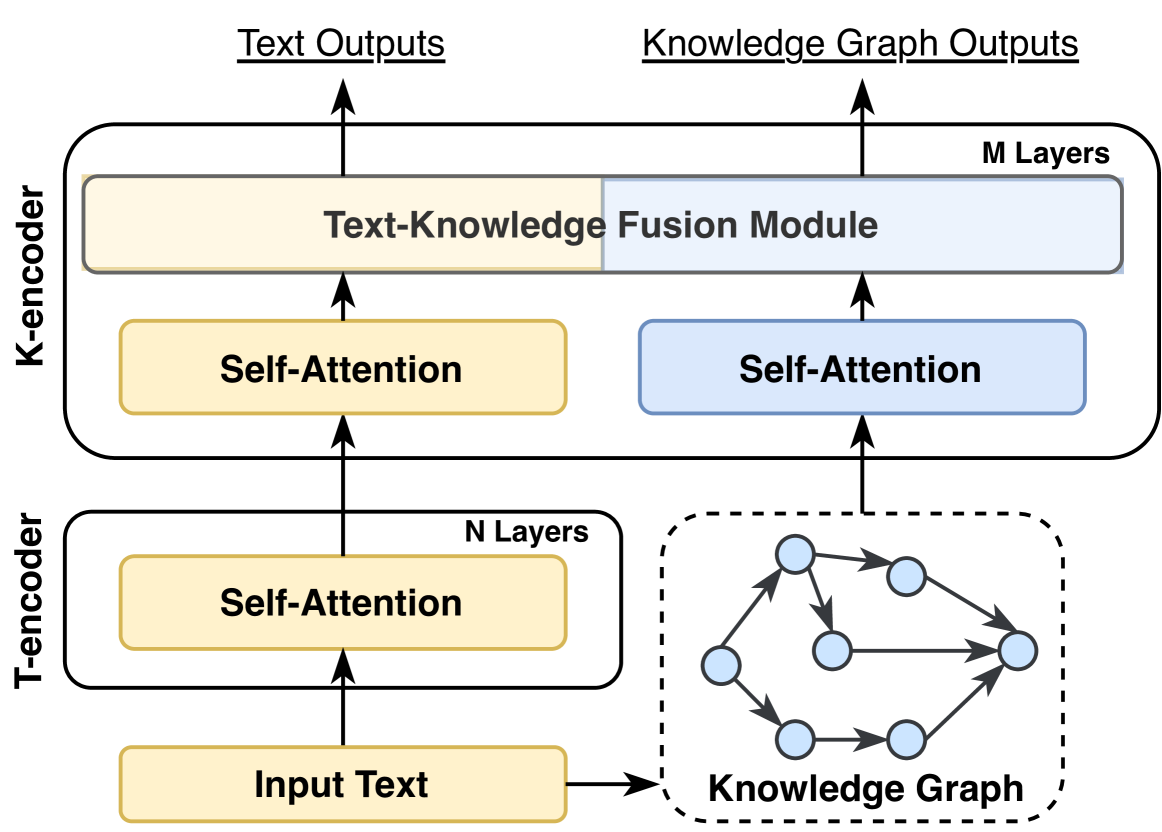
## Diagram: Text-to-Knowledge Graph Architecture
### Overview
The image depicts a diagram of a text-to-knowledge graph architecture, illustrating the flow of information from input text to both text and knowledge graph outputs. The architecture consists of two main encoders (T-encoder and K-encoder) and a fusion module.
### Components/Axes
The diagram includes the following components:
* **Input Text:** The initial input to the system.
* **Knowledge Graph:** A representation of structured knowledge.
* **T-encoder:** Processes the input text. Contains "N Layers" and a "Self-Attention" module.
* **K-encoder:** Processes the knowledge graph. Contains "M Layers" and two "Self-Attention" modules.
* **Text-Knowledge Fusion Module:** Combines information from both encoders.
* **Text Outputs:** The final text-based output of the system.
* **Knowledge Graph Outputs:** The final knowledge graph-based output of the system.
The diagram also labels the number of layers in each encoder: "N Layers" for the T-encoder and "M Layers" for the K-encoder.
### Detailed Analysis or Content Details
The diagram shows a clear flow of information:
1. **Input:** "Input Text" and "Knowledge Graph" are fed into the T-encoder and K-encoder respectively.
2. **T-encoder Processing:** The "Input Text" is processed by a "Self-Attention" module within the T-encoder, which has "N Layers". The output of the T-encoder is then fed into the "Text-Knowledge Fusion Module".
3. **K-encoder Processing:** The "Knowledge Graph" is processed by two "Self-Attention" modules within the K-encoder, which has "M Layers". The output of the K-encoder is also fed into the "Text-Knowledge Fusion Module".
4. **Fusion & Output:** The "Text-Knowledge Fusion Module" combines the outputs from both encoders and generates two outputs: "Text Outputs" and "Knowledge Graph Outputs".
The Knowledge Graph is visually represented as a network of nodes (circles) connected by edges (lines). There are approximately 7 nodes visible, with connections forming a complex network. The Knowledge Graph is enclosed in a dashed-line box.
### Key Observations
* The architecture utilizes self-attention mechanisms in both encoders.
* The fusion module is a central component, integrating information from both text and knowledge sources.
* The diagram does not specify the exact values of "N" and "M" (number of layers).
* The Knowledge Graph is represented as a simple network, suggesting a focus on relationships between entities.
### Interpretation
This diagram illustrates a neural network architecture designed to bridge the gap between natural language text and structured knowledge representations (knowledge graphs). The T-encoder likely transforms the input text into a vector representation, while the K-encoder does the same for the knowledge graph. The self-attention mechanisms allow the model to focus on the most relevant parts of the input text and knowledge graph when making predictions. The fusion module is crucial for combining these representations, enabling the model to generate outputs that leverage both textual and knowledge-based information. The outputs suggest the model can perform tasks that require both understanding of text and reasoning over knowledge graphs, such as question answering, knowledge base completion, or text summarization. The lack of specific layer numbers ("N" and "M") suggests these are hyperparameters that can be tuned for optimal performance. The diagram is a high-level overview and doesn't detail the specific implementation of the self-attention modules or the fusion mechanism.