\n
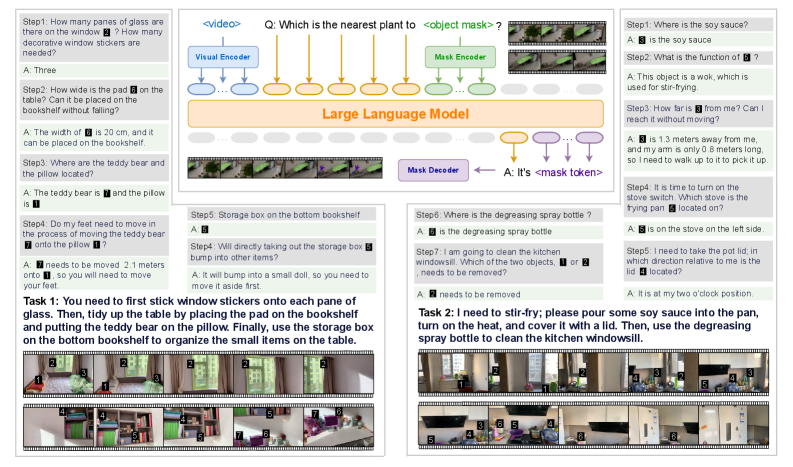
## Diagram: Robotic Task Planning & Visual Question Answering
### Overview
The image depicts a diagram illustrating a robotic task planning and visual question answering system. It showcases a Large Language Model (LLM) integrating visual information from a "Visual Encoder" and "Mask Encoder" to respond to questions about a scene. The scene appears to be a kitchen setting with various objects like a window, a pan, a teddy bear, a pillow, and cleaning supplies. The diagram is structured around a series of steps (Step 1-Step 10) representing questions posed to the system, along with the system's responses. A heatmap at the bottom visualizes attention weights.
### Components/Axes
The diagram consists of the following key components:
* **Visual Encoder:** Processes visual information from the scene.
* **Mask Encoder:** Processes mask information (object segmentation) from the scene.
* **Large Language Model (LLM):** Integrates visual and mask information to generate responses.
* **Mask Decoder:** Decodes the mask token.
* **Question Prompts (Step 1-Step 10):** Textual questions posed to the system.
* **System Responses (A):** The LLM's answers to the questions.
* **Heatmap:** A 10x10 grid visualizing attention weights, with color intensity indicating the strength of attention. The axes are not explicitly labeled, but represent the spatial dimensions of the scene being analyzed.
* **Scene Image:** A photograph of a kitchen scene with various objects.
### Detailed Analysis or Content Details
**Question & Answer Pairs:**
* **Step 1:** "How many panes of glass are there on the window?" A: "Three"
* **Step 2:** "How wide is the pad on the table? Can it be placed on the bookshelf without falling?" A: "The width of is 20 cm, and it can be placed on the bookshelf."
* **Step 3:** "Where are the teddy bear and the pillow located?" A: "The teddy bear is and the pillow is"
* **Step 4:** "Do my feet need to move in the process of moving the teddy bear onto the pillow?" A: "needs to be moved 2.1 meters onto"
* **Step 5:** "Storage box on the bottom bookshelf?" A: ""
* **Step 6:** "Where is the degreasing spray bottle?" A: "is the degreasing spray bottle"
* **Step 7:** "I am going to clean the kitchen windowsill. Which of the two objects, or needs to be removed?" A: "needs to be removed"
* **Step 8:** "Where is the soy sauce?" A: "is the soy sauce"
* **Step 9:** "What is the function of ?" A: "This object is a wok, which is used for stir-frying."
* **Step 10:** "How far is from me? Can I reach it without moving?" A: "is 1.3 meters away from me, and my arm is only 0.8 meters long, so I need to walk up to it to pick it up."
**Heatmap Analysis:**
The heatmap displays attention weights. The color scale ranges from dark blue (low attention) to red (high attention). The heatmap appears to be centered around the objects in the scene.
* **Row 1:** Weights are highest in columns 1-3, then decrease.
* **Row 2:** Weights are highest in columns 2-4, then decrease.
* **Row 3:** Weights are highest in columns 3-5, then decrease.
* **Row 4:** Weights are highest in columns 4-6, then decrease.
* **Row 5:** Weights are highest in columns 5-7, then decrease.
* **Row 6:** Weights are highest in columns 6-8, then decrease.
* **Row 7:** Weights are highest in columns 7-9, then decrease.
* **Row 8:** Weights are highest in columns 8-10, then decrease.
* **Row 9:** Weights are highest in columns 9-1, then decrease.
* **Row 10:** Weights are highest in columns 10-2, then decrease.
**Task Descriptions:**
* **Task 1:** "You need to first stick window stickers onto each pane of glass. Then, tidy up the table by placing the pad on the bookshelf and putting the teddy bear on the pillow. Finally, use the storage box on the bottom bookshelf to organize the smaller items on the table."
* **Task 2:** "I need to stir-fry; please pour some soy sauce into the pan, turn on the heat, and cover it with a lid. Then, use the degreasing spray bottle to clean the kitchen windowsill."
### Key Observations
* The system demonstrates the ability to answer questions about object locations, quantities, and functions within a visual scene.
* The heatmap suggests a sequential attention pattern, moving across the scene from left to right, then right to left.
* The system can reason about distances and reachability for robotic manipulation.
* The responses are not always complete, with some answers being truncated ("" in Step 5).
* The system can generate multi-step task instructions.
### Interpretation
This diagram illustrates a sophisticated robotic system capable of integrating visual perception with natural language understanding. The LLM acts as a central reasoning engine, leveraging information from both the visual and mask encoders to answer questions and plan tasks. The heatmap provides insight into the system's attention mechanism, revealing how it focuses on different parts of the scene to extract relevant information. The sequential attention pattern observed in the heatmap suggests the system may be scanning the scene in a systematic manner. The ability to reason about distances and reachability is crucial for robotic manipulation tasks. The incomplete responses highlight potential limitations of the system, possibly related to the complexity of the scene or the ambiguity of the questions. Overall, the diagram demonstrates a promising approach to building intelligent robots that can interact with the world in a more natural and intuitive way. The system is likely being used for research into embodied AI, where robots learn to perform tasks by interacting with their environment and responding to human instructions. The use of both visual and mask information suggests the system is capable of not only recognizing objects but also understanding their spatial relationships and boundaries.