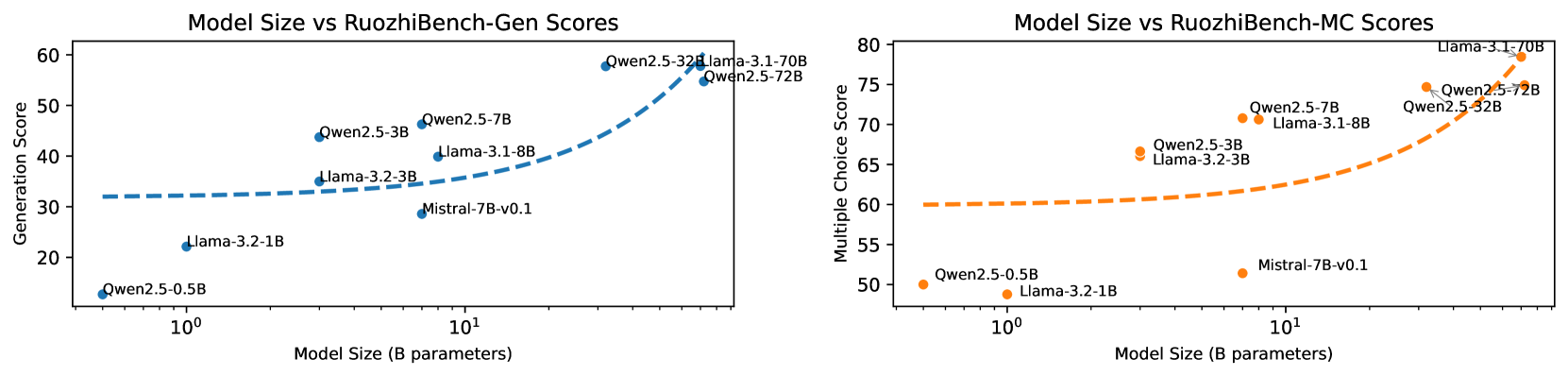
## Scatter Plots: Model Size vs RuozhiBench Scores
### Overview
The image displays two scatter plots side-by-side, illustrating the relationship between "Model Size (B parameters)" on the x-axis and a specific RuozhiBench score on the y-axis. The left plot depicts "Generation Score," and the right plot shows "Multiple Choice Score." Both x-axes utilize a logarithmic scale. Dashed lines are present in both plots, indicating a trend or fitted curve.
### Components/Axes
**Left Plot: Model Size vs RuozhiBench-Gen Scores**
* **Title:** Model Size vs RuozhiBench-Gen Scores
* **X-axis Title:** Model Size (B parameters)
* **Scale:** Logarithmic. Markers at 1, 10.
* **Axis Markers:** 1, 10.
* **Y-axis Title:** Generation Score
* **Scale:** Linear.
* **Axis Markers:** 20, 30, 40, 50, 60.
* **Data Points:** Blue circles, each labeled with a model name.
* **Trend Line:** Dashed blue line, generally increasing.
**Right Plot: Model Size vs RuozhiBench-MC Scores**
* **Title:** Model Size vs RuozhiBench-MC Scores
* **X-axis Title:** Model Size (B parameters)
* **Scale:** Logarithmic. Markers at 1, 10.
* **Axis Markers:** 1, 10.
* **Y-axis Title:** Multiple Choice Score
* **Scale:** Linear.
* **Axis Markers:** 50, 55, 60, 65, 70, 75, 80.
* **Data Points:** Orange circles, each labeled with a model name.
* **Trend Line:** Dashed orange line, generally increasing.
### Detailed Analysis
**Left Plot (Generation Score):**
The blue dashed line generally slopes upward, indicating that as model size increases, the Generation Score tends to increase.
* **Qwen2.5-0.5B:** Approximately (0.5 B parameters, 12 Generation Score)
* **Llama-3.2-1B:** Approximately (1.2 B parameters, 23 Generation Score)
* **Mistral-7B-v0.1:** Approximately (7 B parameters, 30 Generation Score)
* **Llama-3.2-3B:** Approximately (3 B parameters, 34 Generation Score)
* **Llama-3.1-8B:** Approximately (8 B parameters, 36 Generation Score)
* **Qwen2.5-3B:** Approximately (3 B parameters, 43 Generation Score)
* **Qwen2.5-7B:** Approximately (7 B parameters, 47 Generation Score)
* **Qwen2.5-32B:** Approximately (32 B parameters, 54 Generation Score)
* **Qwen2.5-72B:** Approximately (72 B parameters, 55 Generation Score)
* **Llama-3.1-70B:** Approximately (70 B parameters, 56 Generation Score)
**Right Plot (Multiple Choice Score):**
The orange dashed line generally slopes upward, indicating that as model size increases, the Multiple Choice Score tends to increase.
* **Qwen2.5-0.5B:** Approximately (0.5 B parameters, 50 Multiple Choice Score)
* **Llama-3.2-1B:** Approximately (1.2 B parameters, 51 Multiple Choice Score)
* **Mistral-7B-v0.1:** Approximately (7 B parameters, 57 Multiple Choice Score)
* **Llama-3.2-3B:** Approximately (3 B parameters, 62 Multiple Choice Score)
* **Qwen2.5-3B:** Approximately (3 B parameters, 63 Multiple Choice Score)
* **Qwen2.5-7B:** Approximately (7 B parameters, 70 Multiple Choice Score)
* **Qwen2.5-32B:** Approximately (32 B parameters, 73 Multiple Choice Score)
* **Qwen2.5-72B:** Approximately (72 B parameters, 74 Multiple Choice Score)
* **Llama-3.1-70B:** Approximately (70 B parameters, 77 Multiple Choice Score)
### Key Observations
* **Positive Correlation:** Both plots exhibit a clear positive correlation between model size and performance on both Generation and Multiple Choice tasks. Larger models generally achieve higher scores.
* **Diminishing Returns (Implied):** The dashed trend lines appear to flatten at higher model sizes, suggesting that performance gains from increasing model size may be subject to diminishing returns, particularly for the Generation Score.
* **Performance Differences:** For comparable model sizes, there can be variations in scores between the two tasks. For instance, Llama-3.1-70B and Qwen2.5-72B, with very similar sizes, achieve comparable high scores on both metrics. However, Qwen2.5-3B and Llama-3.2-3B (both around 3B parameters) show a larger disparity in Generation Score (43 vs 34) than in Multiple Choice Score (63 vs 62).
* **Outliers/Anomalies:**
* In the left plot, Qwen2.5-3B (3B parameters) demonstrates a significantly higher Generation Score (43) compared to Llama-3.2-3B (3B parameters, 34) and Llama-3.1-8B (8B parameters, 36).
* In the right plot, Mistral-7B-v0.1 (7B parameters) achieves a relatively high Multiple Choice Score (57) for its model size, notably exceeding Llama-3.2-1B (1.2B parameters, 51) and Qwen2.5-0.5B (0.5B parameters, 50).
### Interpretation
These scatter plots illustrate a fundamental principle in the development of large language models: **model size is a significant determinant of performance**. As the number of parameters (model size) increases, the models' capabilities in tasks such as text generation and multiple-choice question answering generally improve.
The dashed lines, likely representing trend fitting or a generalized performance curve, visually corroborate this relationship. The upward slope signifies that investing in larger models yields better results. However, the apparent flattening of these curves at the higher end of model sizes suggests that simply scaling up models indefinitely may not result in proportional performance enhancements. This could imply that other factors, such as architectural advancements, training data quality, or fine-tuning strategies, become increasingly critical for further performance improvements beyond a certain scale.
The performance variations between models of similar sizes and across the two benchmark tasks highlight the crucial role of model architecture and specific training objectives. For example, the superior Generation Score for Qwen2.5-3B compared to similarly sized models suggests it may be optimized for generative capabilities. Conversely, the relatively strong Multiple Choice Score for Mistral-7B-v0.1 indicates its proficiency in understanding and selecting correct answers.
In essence, the data suggests a trade-off between model size and performance, with larger models generally being more capable but potentially subject to diminishing returns. The specific performance profile of each model also depends on its underlying architecture and training. This information is vital for researchers and developers when determining model architectures, resource allocation, and performance targets for various natural language processing applications.