## Bar Chart: LLM Performance Comparison
### Overview
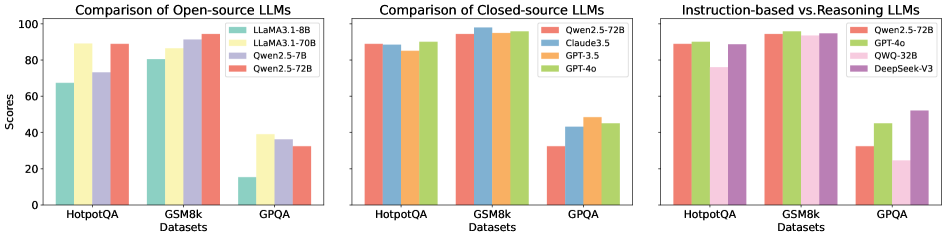
The image presents three bar charts comparing the performance of different Large Language Models (LLMs) on three datasets: HotpotQA, GSM8k, and GPQA. The charts are grouped by LLM type: Open-source, Closed-source, and Instruction-based vs. Reasoning. The y-axis represents scores, presumably accuracy or a similar performance metric.
### Components/Axes
**General Chart Elements:**
* **Title (Left Chart):** Comparison of Open-source LLMs
* **Title (Middle Chart):** Comparison of Closed-source LLMs
* **Title (Right Chart):** Instruction-based vs. Reasoning LLMs
* **Y-axis Label:** Scores
* **Y-axis Scale:** 0 to 100, with tick marks at intervals of 20.
* **X-axis Label:** Datasets
* **X-axis Categories:** HotpotQA, GSM8k, GPQA
**Legend (Left Chart):** Located in the top-right corner of the left chart.
* Light Teal: LLaMA3.1-8B
* Light Yellow: LLaMA3.1-70B
* Light Purple: Qwen2.5-7B
* Light Red: Qwen2.5-72B
**Legend (Middle Chart):** Located in the top-right corner of the middle chart.
* Light Red: Qwen2.5-72B
* Light Blue: Claude3.5
* Light Orange: GPT-3.5
* Light Green: GPT-4o
**Legend (Right Chart):** Located in the top-right corner of the right chart.
* Light Red: Qwen2.5-72B
* Light Green: GPT-4o
* Light Pink: QWQ-32B
* Light Purple: DeepSeek-V3
### Detailed Analysis
**Left Chart: Open-source LLMs**
* **LLaMA3.1-8B (Light Teal):**
* HotpotQA: ~68
* GSM8k: ~81
* GPQA: ~35
* **LLaMA3.1-70B (Light Yellow):**
* HotpotQA: ~89
* GSM8k: ~87
* GPQA: ~38
* **Qwen2.5-7B (Light Purple):**
* HotpotQA: ~73
* GSM8k: ~91
* GPQA: ~36
* **Qwen2.5-72B (Light Red):**
* HotpotQA: ~89
* GSM8k: ~94
* GPQA: ~37
**Middle Chart: Closed-source LLMs**
* **Qwen2.5-72B (Light Red):**
* HotpotQA: ~91
* GSM8k: ~95
* GPQA: ~30
* **Claude3.5 (Light Blue):**
* HotpotQA: ~88
* GSM8k: ~96
* GPQA: ~40
* **GPT-3.5 (Light Orange):**
* HotpotQA: ~90
* GSM8k: ~96
* GPQA: ~44
* **GPT-4o (Light Green):**
* HotpotQA: ~92
* GSM8k: ~97
* GPQA: ~46
**Right Chart: Instruction-based vs. Reasoning LLMs**
* **Qwen2.5-72B (Light Red):**
* HotpotQA: ~91
* GSM8k: ~95
* GPQA: ~24
* **GPT-4o (Light Green):**
* HotpotQA: ~92
* GSM8k: ~97
* GPQA: ~40
* **QWQ-32B (Light Pink):**
* HotpotQA: ~88
* GSM8k: ~95
* GPQA: ~28
* **DeepSeek-V3 (Light Purple):**
* HotpotQA: ~90
* GSM8k: ~95
* GPQA: ~50
### Key Observations
* **Dataset Performance:** All models generally perform better on GSM8k and HotpotQA compared to GPQA.
* **Open-source vs. Closed-source:** Closed-source models (GPT-4o, GPT-3.5, Claude3.5) generally achieve higher scores on HotpotQA and GSM8k than the open-source models.
* **GPQA Challenge:** GPQA appears to be a more challenging dataset for all models, with significantly lower scores across the board.
* **Qwen2.5-72B Consistency:** Qwen2.5-72B is present in all three charts, providing a point of comparison across different model categories.
* **Instruction-based vs. Reasoning:** The right chart highlights the performance difference between models optimized for instruction following versus reasoning tasks, particularly on the GPQA dataset.
### Interpretation
The charts provide a comparative analysis of LLM performance across different model architectures and datasets. The data suggests that:
* Closed-source models generally outperform open-source models on HotpotQA and GSM8k, indicating potential advantages in training data, model size, or architecture.
* The GPQA dataset poses a significant challenge for all models, suggesting it requires more advanced reasoning capabilities or a different type of knowledge.
* The Instruction-based vs. Reasoning chart highlights the trade-offs between models optimized for different tasks. DeepSeek-V3 and GPT-4o show better performance on GPQA compared to Qwen2.5-72B and QWQ-32B, suggesting they may be better suited for reasoning-intensive tasks.
* The consistent presence of Qwen2.5-72B across all charts allows for a direct comparison of its performance relative to different model categories. It performs competitively on HotpotQA and GSM8k but struggles on GPQA, similar to other models.
The data underscores the importance of dataset selection in evaluating LLM performance and highlights the varying strengths and weaknesses of different model architectures. Further investigation into the specific characteristics of the GPQA dataset could provide valuable insights into the limitations of current LLMs and guide future research efforts.