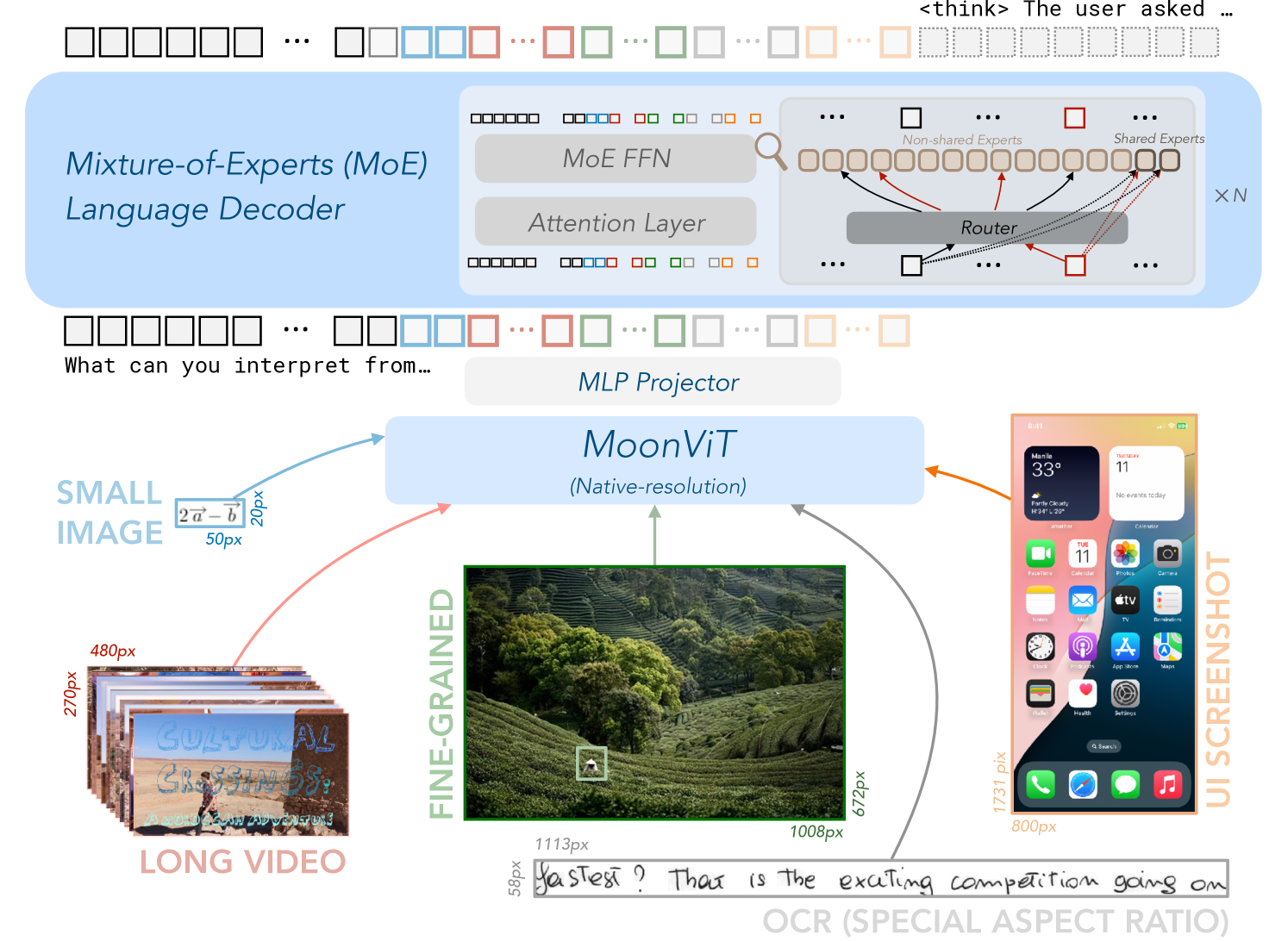
## Diagram: MoonViT Architecture
### Overview
The image presents a diagram illustrating the architecture of MoonViT, a system that processes various types of input data, including small images, long videos, fine-grained images, and UI screenshots. The system uses a Mixture-of-Experts (MoE) Language Decoder and an MLP Projector to interpret the input.
### Components/Axes
* **Input Types:**
* SMALL IMAGE: A small image with dimensions indicated as 20px and 50px. The image itself is not visible.
* LONG VIDEO: A stack of video frames labeled "CULTURAL CROSSINGS: A MOROCCAN ADVENTURE". The dimensions of the frames are approximately 270px in height and 480px in width.
* FINE-GRAINED: A landscape image of a tea plantation, with dimensions of 672px in height and 1008px in width. A small white square is visible within the image.
* UI SCREENSHOT: A screenshot of an iPhone's home screen, displaying various app icons and widgets. The dimensions are approximately 1731px in height and 800px in width.
* OCR (SPECIAL ASPECT RATIO): Handwritten text that reads "fastest? That is the exciting competition going on". The dimensions are approximately 58px in height and 1113px in width.
* **Processing Modules:**
* Mixture-of-Experts (MoE) Language Decoder: A module consisting of MoE FFN (Feed Forward Network) and an Attention Layer. It includes "Non-shared Experts" and "Shared Experts" connected by a "Router". The output is multiplied by "XN".
* MLP Projector: A module that projects the input data.
* MoonViT (Native-resolution): The core module that processes the input data.
* **Textual Elements:**
* "<think> The user asked ...": Text indicating a user query.
* "What can you interpret from...": Text indicating the system's task.
### Detailed Analysis
* **Input Data Flow:**
* The SMALL IMAGE is fed into the MLP Projector.
* The LONG VIDEO is fed into the MLP Projector.
* The FINE-GRAINED image is fed directly into MoonViT.
* The UI SCREENSHOT is fed into the MLP Projector.
* The OCR text is fed directly into MoonViT.
* **MoE Language Decoder:**
* The MoE Language Decoder consists of an MoE FFN and an Attention Layer.
* The "Router" connects "Non-shared Experts" and "Shared Experts".
### Key Observations
* The diagram illustrates a multi-modal input processing system.
* MoonViT appears to be the central processing unit, handling both fine-grained images and OCR text directly.
* The MLP Projector seems to be used for processing SMALL IMAGES, LONG VIDEOS, and UI SCREENSHOTS before they are fed into MoonViT.
* The MoE Language Decoder is used to interpret the processed data.
### Interpretation
The diagram depicts the architecture of MoonViT, a system designed to handle various types of input data, including images, videos, and text. The system uses a Mixture-of-Experts (MoE) Language Decoder to interpret the input, suggesting that it leverages multiple specialized models to understand different aspects of the data. The MLP Projector likely serves as a pre-processing step to transform the input data into a suitable format for MoonViT. The system's ability to handle native-resolution images and OCR text directly indicates its focus on preserving detail and extracting textual information from visual sources. The overall architecture suggests a sophisticated approach to multi-modal data processing, potentially enabling MoonViT to perform complex tasks such as image captioning, video understanding, and UI analysis.