TECHNICAL ASSET FINGERPRINT
4062084420a5e52a27a43465
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
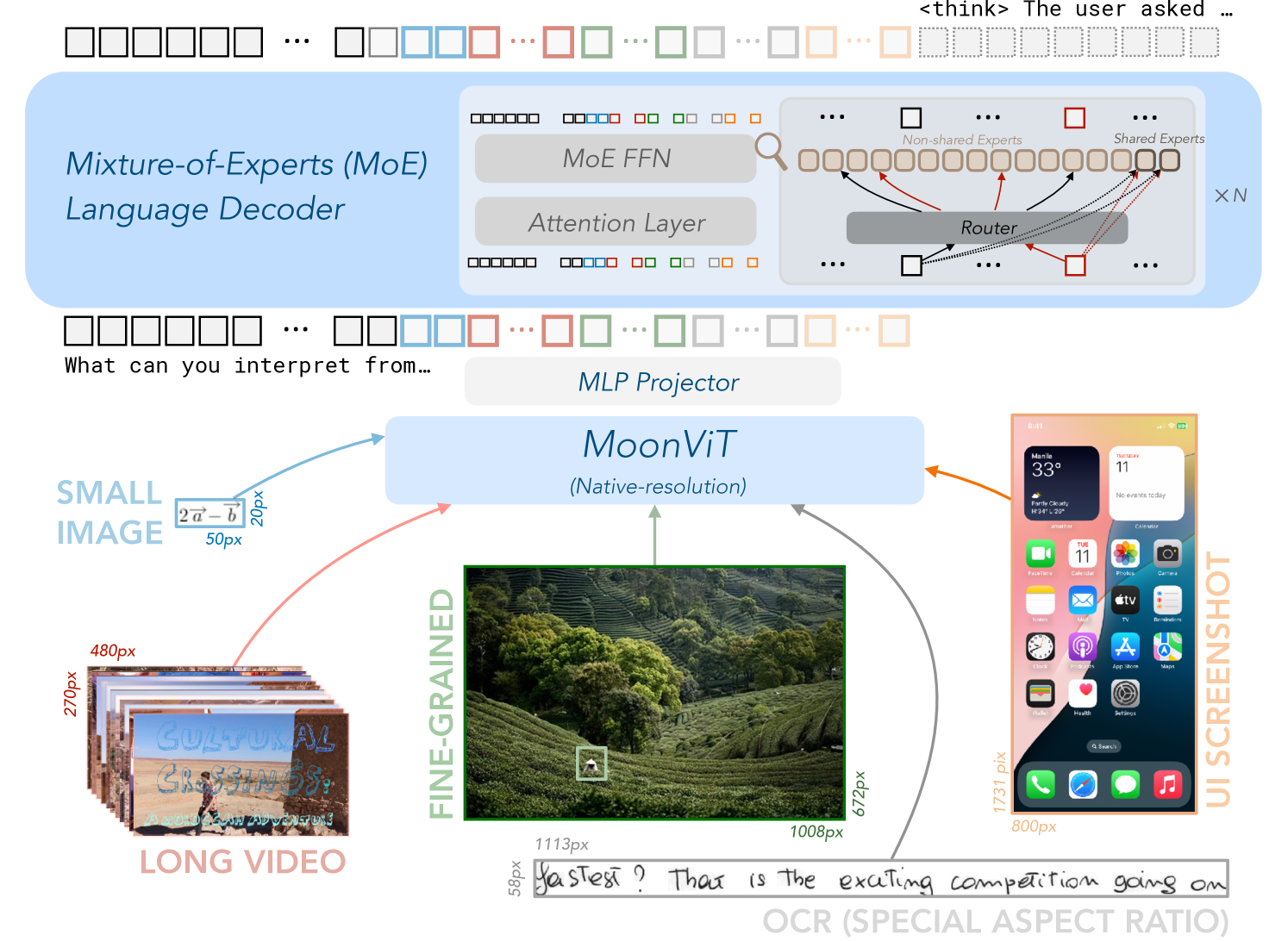
## Technical Diagram: Multimodal AI System Architecture
### Overview
This image is a technical diagram illustrating the architecture of a multimodal AI system. It depicts how various input types (text, images, video, UI screenshots, OCR text) are processed through a central vision transformer ("MoonViT") and then fed into a Mixture-of-Experts (MoE) language decoder. The diagram emphasizes native-resolution processing and the integration of diverse data modalities.
### Components/Axes
The diagram is organized into three primary regions:
1. **Top Region (Blue Background): Mixture-of-Experts (MoE) Language Decoder**
* **Main Label:** "Mixture-of-Experts (MoE) Language Decoder"
* **Sub-components:**
* "MoE FFN" (Feed-Forward Network)
* "Attention Layer"
* A detailed breakout box showing the MoE routing mechanism:
* "Router"
* "Non-shared Experts" (represented by a row of outlined squares)
* "Shared Experts" (represented by a row of filled squares)
* The notation "× N" indicates this block is repeated N times.
* **Input/Output:** A sequence of colored squares (representing tokens) flows into and out of this decoder block.
2. **Central Region: Core Processing Module**
* **Primary Module:** "MoonViT" with the subtitle "(Native-resolution)". This is the central vision transformer.
* **Bridge Component:** "MLP Projector" (Multi-Layer Perceptron), positioned between the MoE decoder and MoonViT, likely for feature projection.
3. **Bottom Region: Input Modalities**
Five distinct input types are shown, all feeding into the MoonViT module via colored arrows:
* **Left (Light Blue Arrow):** "SMALL IMAGE"
* Contains a mathematical notation: `2a - b`
* Dimension labels: "50px" (width), "20px" (height).
* **Bottom Left (Red Arrow):** "LONG VIDEO"
* Depicted as a stack of video frames.
* Dimension labels: "480px" (width), "270px" (height).
* Text visible on the video frames: "CULTURAL CROSSINGS: A JOURNEY OF DISCOVERY".
* **Bottom Center (Green Arrow):** "FINE-GRAINED"
* A high-resolution photograph of a terraced tea plantation.
* Dimension labels: "1113px" (width), "1008px" (height).
* A small white bounding box is drawn on the image, highlighting a specific detail.
* **Bottom Right (Gray Arrow):** "OCR (SPECIAL ASPECT RATIO)"
* A handwritten text snippet: "fastest? That is the exciting competition going on".
* Dimension label: "58px" (height).
* **Right (Orange Arrow):** "UI SCREENSHOT"
* A screenshot of a smartphone home screen (iOS-style).
* Dimension labels: "800px" (width), "1731px" (height).
* Visible UI elements include app icons (FaceTime, Calendar, Photos, Camera, Mail, Clock, Maps, Weather, Notes, etc.), widgets (calendar, weather), and status bar icons.
### Detailed Analysis
* **Data Flow:** The flow is bottom-up and then top-down. Raw multimodal inputs (image, video, UI, text) are first processed by the MoonViT vision encoder. The encoded visual features are then passed through the MLP Projector to the MoE Language Decoder, which generates the final textual output (represented by the token sequence at the very top).
* **Key Architectural Features:**
* **Native-Resolution Processing:** The "MoonViT" label explicitly states it operates on native-resolution inputs, avoiding resizing or padding that could distort information, especially critical for the "FINE-GRAINED" image and "UI SCREENSHOT".
* **Mixture-of-Experts (MoE):** The language decoder uses an MoE architecture. The "Router" dynamically directs input tokens to a subset of "Non-shared Experts" while also utilizing "Shared Experts". This design aims for computational efficiency and model specialization.
* **Diverse Input Handling:** The system is designed to handle a wide range of aspect ratios and content types, from small mathematical images (50x20px) to tall UI screenshots (800x1731px) and long video sequences.
### Key Observations
1. **Input Diversity:** The diagram explicitly showcases five fundamentally different input types, highlighting the system's multimodal capability.
2. **Resolution Emphasis:** Pixel dimensions are provided for every input, underscoring the importance of resolution and aspect ratio in the system's design.
3. **Specialized OCR Input:** The "OCR (SPECIAL ASPECT RATIO)" input suggests the system has a dedicated pathway or training for recognizing text in unusual layouts or handwritten forms.
4. **Visual Detail Focus:** The "FINE-GRAINED" input with its bounding box implies the system can process and reason about specific regions within a high-resolution image.
5. **MoE Complexity:** The detailed breakout of the MoE block indicates that the language generation component is a significant and complex part of the architecture.
### Interpretation
This diagram represents a sophisticated, unified multimodal AI architecture. The core innovation appears to be the **MoonViT** module, which acts as a universal visual encoder capable of ingesting images, video frames, and screenshots at their native resolutions. This preserves critical spatial and textual details that would be lost with standard resizing.
The encoded visual information is then translated (via the MLP Projector) into a format that the powerful **MoE Language Decoder** can understand. The MoE decoder, with its router and mix of shared/specialized experts, is designed to efficiently generate coherent and contextually appropriate language based on the complex visual input.
The system's purpose is likely **visual question answering, document understanding, or detailed image/video captioning**. It can take a complex scene (like a UI screenshot or a detailed landscape) and answer questions about it, describe it, or extract information from it (as hinted by the OCR input and the "What can you interpret from..." text fragment near the top). The inclusion of "LONG VIDEO" suggests it may also handle temporal reasoning across frames.
**Notable Anomaly/Challenge:** The vast difference in input dimensions (from 20px height to 1731px height) presents a significant technical challenge for consistent feature extraction, which the "native-resolution" claim of MoonViT aims to address. The architecture suggests a move away from traditional, rigid vision encoders towards more flexible, resolution-agnostic models.
DECODING INTELLIGENCE...