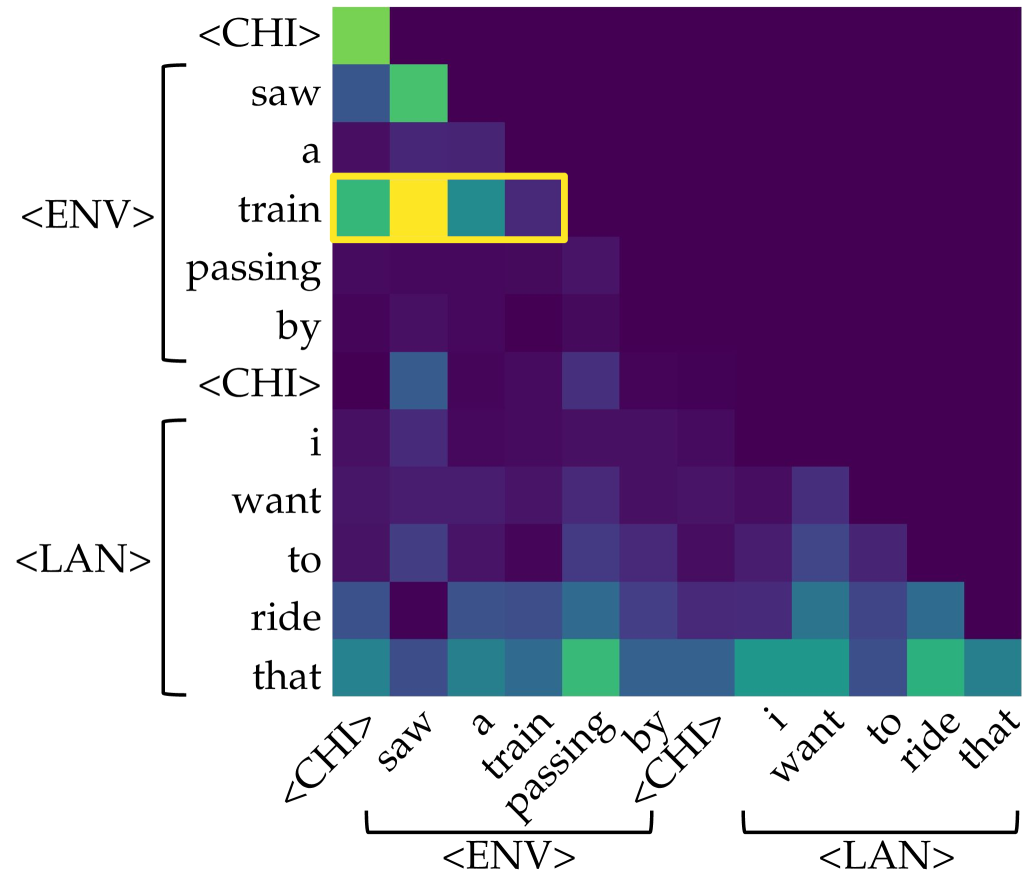
## Attention Heatmap: Token-to-Token Attention Weights
### Overview
The image displays a square attention heatmap, likely visualizing the attention weights between tokens in a sequence processed by a neural network (e.g., a Transformer model). The matrix shows how much each token in the sequence "attends to" or focuses on every other token. The color intensity represents the strength of the attention weight, with darker colors (purple/blue) indicating lower weights and brighter colors (green/yellow) indicating higher weights. A specific row is highlighted with a yellow bounding box.
### Components/Axes
* **Matrix Structure:** A square grid where both the vertical (Y-axis) and horizontal (X-axis) axes represent the same sequence of tokens.
* **Token Sequence (Labels):** The sequence, read from top to bottom on the Y-axis and left to right on the X-axis, is:
1. `<CHI>`
2. `saw`
3. `a`
4. `train`
5. `passing`
6. `by`
7. `<CHI>`
8. `i`
9. `want`
10. `to`
11. `ride`
12. `that`
* **Grouping Annotations:** Brackets on the left (Y-axis) and bottom (X-axis) group the tokens into segments:
* **`<ENV>`:** Encompasses tokens 2-6 (`saw`, `a`, `train`, `passing`, `by`). This likely stands for "Environment" or a contextual segment.
* **`<LAN>`:** Encompasses tokens 8-12 (`i`, `want`, `to`, `ride`, `that`). This likely stands for "Language" or a target utterance segment.
* The special tokens `<CHI>` (likely "Child" or a speaker tag) appear at positions 1 and 7, acting as segment boundaries.
* **Color Scale (Implied):** There is no explicit legend, but the color gradient from dark purple to bright yellow represents the magnitude of the attention weight. The brightest cell (yellow) indicates the maximum attention value in this view.
### Detailed Analysis
* **Highlighted Row:** The row corresponding to the token **`train`** (4th row) is enclosed in a yellow rectangle. This row shows the highest attention weights in the entire matrix.
* The cell at the intersection of row `train` and column `train` (the diagonal) is bright yellow, indicating the token attends very strongly to itself.
* The cell at row `train` and column `saw` is bright green, showing strong attention from "train" back to "saw".
* The cell at row `train` and column `a` is a medium teal/green, indicating moderate attention.
* The cell at row `train` and column `passing` is a darker teal/blue, indicating weaker attention.
* **General Attention Patterns:**
* **Diagonal Bias:** There is a visible, though not perfectly strong, diagonal line of brighter cells from the top-left to bottom-right. This is typical in attention maps, showing tokens often attend to themselves and nearby tokens.
* **`<ENV>` Segment Block:** The 5x5 sub-matrix for tokens `saw` through `by` (rows and columns 2-6) shows a block of relatively higher attention (lighter blues and greens) compared to the rest of the map, suggesting stronger intra-segment attention within the `<ENV>` context.
* **`<LAN>` Segment Block:** Similarly, the 5x5 sub-matrix for tokens `i` through `that` (rows and columns 8-12) shows another block of moderate attention (mostly blues), indicating intra-segment attention within the `<LAN>` utterance.
* **Cross-Segment Attention:** Attention between the `<ENV>` and `<LAN>` segments (the off-diagonal blocks) is generally very low (dark purple), with a few exceptions. Notably, the token `that` (last row) shows moderate attention (teal/green) to several tokens in the `<ENV>` segment, particularly `train` and `passing`.
* **`<CHI>` Tokens:** The special tokens `<CHI>` at positions 1 and 7 show very low attention to all other tokens (dark purple rows) and are attended to weakly by other tokens.
### Key Observations
1. **Dominant Focus on "train":** The token `train` is the clear focal point of this attention map. It has the strongest self-attention and receives significant attention from the preceding verb `saw`.
2. **Segmented Attention:** The model's attention is largely compartmentalized within the defined `<ENV>` and `<LAN>` segments, with limited cross-talk between them.
3. **Anaphoric Reference:** The final token `that` in the `<LAN>` segment (`i want to ride that`) shows a pattern of attending back to key content words in the `<ENV>` segment (`saw a train passing by`), most strongly to `train`. This visually demonstrates the model linking the pronoun "that" to its antecedent "train".
4. **Low Attention to Function Words:** Grammatical words like `a`, `to`, `by`, and the special `<CHI>` tokens generally exhibit and receive low attention weights.
### Interpretation
This heatmap provides a visual explanation of how a language model processes a two-part input: a descriptive statement (`<ENV>: saw a train passing by`) followed by a related desire (`<LAN>: i want to ride that`).
* **The data suggests** the model correctly identifies "train" as the central entity of interest. The strong attention from "saw" to "train" and the self-attention of "train" confirm its role as the primary subject.
* **The elements relate** through a coreference resolution task. The attention pattern from "that" back to "train" is the key mechanistic insight, showing how the model resolves the pronoun "that" to the specific noun "train" mentioned earlier. The segmented attention blocks indicate the model treats the two clauses as distinct but related contexts.
* **Notable patterns** include the stark compartmentalization between segments and the specific, targeted cross-segment attention from the pronoun. This is not random noise; it's a structured, interpretable pattern indicative of a model performing a coherent linguistic operation. The lack of attention to `<CHI>` tokens suggests they may serve purely as structural delimiters without semantic content for this attention head.