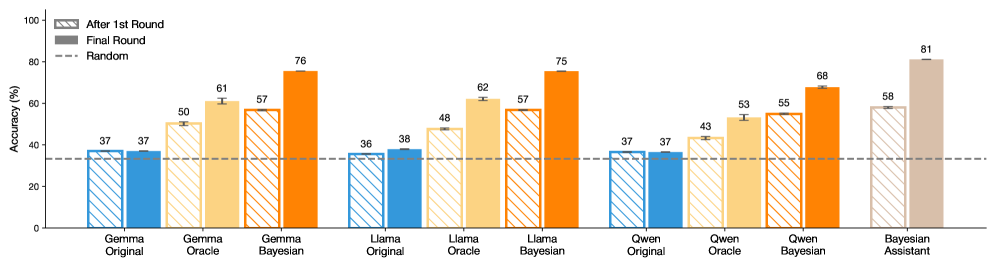
## Grouped Bar Chart: Accuracy Comparison of AI Models Across Different Methods
### Overview
This image is a grouped bar chart comparing the accuracy percentages of three large language models (Gemma, Llama, Qwen) under three different methods (Original, Oracle, Bayesian), alongside a standalone "Bayesian Assistant" model. Performance is measured across two evaluation stages: "After 1st Round" and "Final Round." A dashed line indicates a "Random" baseline performance.
### Components/Axes
* **Chart Type:** Grouped bar chart with error bars.
* **Y-Axis:** Labeled "Accuracy (%)". Scale runs from 0 to 100 in increments of 20.
* **X-Axis:** Categorical, listing the model-method combinations. From left to right:
* Gemma Original, Gemma Oracle, Gemma Bayesian
* Llama Original, Llama Oracle, Llama Bayesian
* Qwen Original, Qwen Oracle, Qwen Bayesian
* Bayesian Assistant
* **Legend:** Positioned in the top-left corner of the chart area.
* **After 1st Round:** Represented by bars with diagonal hatching (\\).
* **Final Round:** Represented by solid-colored bars.
* **Random:** Represented by a horizontal dashed line.
* **Data Series Colors (by model group):**
* **Gemma Group:** Blue (Original), Light Orange (Oracle), Dark Orange (Bayesian).
* **Llama Group:** Blue (Original), Light Orange (Oracle), Dark Orange (Bayesian).
* **Qwen Group:** Blue (Original), Light Orange (Oracle), Dark Orange (Bayesian).
* **Bayesian Assistant:** A single tan/beige color.
### Detailed Analysis
The chart presents paired bars for each model-method combination, showing the progression from the 1st Round to the Final Round. Error bars are visible on the "After 1st Round" bars for the Oracle and Bayesian methods.
**1. Gemma Model Group:**
* **Trend:** Accuracy increases consistently from Original to Oracle to Bayesian methods. The Final Round shows a significant improvement over the 1st Round for Oracle and Bayesian.
* **Data Points:**
* Gemma Original: After 1st Round = 37%, Final Round = 37% (no change).
* Gemma Oracle: After 1st Round ≈ 50%, Final Round = 61%.
* Gemma Bayesian: After 1st Round ≈ 57%, Final Round = 76%.
**2. Llama Model Group:**
* **Trend:** Similar upward trend from Original to Oracle to Bayesian. The Final Round improvement is most pronounced for the Bayesian method.
* **Data Points:**
* Llama Original: After 1st Round = 36%, Final Round = 38%.
* Llama Oracle: After 1st Round ≈ 48%, Final Round = 62%.
* Llama Bayesian: After 1st Round ≈ 57%, Final Round = 75%.
**3. Qwen Model Group:**
* **Trend:** Again, accuracy improves from Original to Oracle to Bayesian. The Final Round shows gains across all methods.
* **Data Points:**
* Qwen Original: After 1st Round = 37%, Final Round = 37% (no change).
* Qwen Oracle: After 1st Round ≈ 43%, Final Round = 53%.
* Qwen Bayesian: After 1st Round ≈ 55%, Final Round = 68%.
**4. Bayesian Assistant:**
* **Trend:** This is a single model, not a group. It shows the highest performance on the chart.
* **Data Points:** After 1st Round ≈ 58%, Final Round = 81%.
**5. Random Baseline:**
* The dashed "Random" line is positioned at approximately 33% accuracy, serving as a lower-bound reference.
### Key Observations
1. **Method Superiority:** The Bayesian method consistently yields the highest accuracy within each model family (Gemma, Llama, Qwen), followed by Oracle, with Original performing the worst.
2. **Round Improvement:** For all Oracle and Bayesian methods, the "Final Round" accuracy is substantially higher than the "After 1st Round" accuracy. The "Original" methods show minimal to no improvement between rounds.
3. **Top Performer:** The standalone "Bayesian Assistant" achieves the highest overall accuracy (81% Final Round), outperforming the Bayesian variants of the individual models.
4. **Consistency:** The pattern of improvement (Original < Oracle < Bayesian) is consistent across all three base model families.
5. **Baseline Comparison:** All methods, except the "Original" variants which are near the baseline, perform significantly better than the ~33% random chance level.
### Interpretation
This chart demonstrates the effectiveness of advanced inference or training methods (Oracle and especially Bayesian) over a base ("Original") model in a multi-round evaluation setting. The data suggests that:
* **Bayesian methods are highly effective:** They provide the largest accuracy boost within each model family and show the most significant gain from the first to the final round, indicating they benefit greatly from iterative refinement or additional data.
* **The "Original" models plateau:** Their lack of improvement between rounds suggests they may lack the mechanism to leverage additional interactions or information presented in the later round.
* **The "Bayesian Assistant" is a distinct, high-performing system:** Its superior performance implies it may be a specialized model or ensemble designed specifically for the task, rather than just a Bayesian version of Gemma, Llama, or Qwen.
* **The task is non-trivial:** The random baseline is ~33%, suggesting a multi-class classification problem with roughly three choices. The best models achieve over 80% accuracy, showing substantial learning beyond random guessing.
The consistent trends across different base models (Gemma, Llama, Qwen) strengthen the conclusion that the observed benefits are due to the methods (Oracle, Bayesian) themselves, not quirks of a single model architecture.