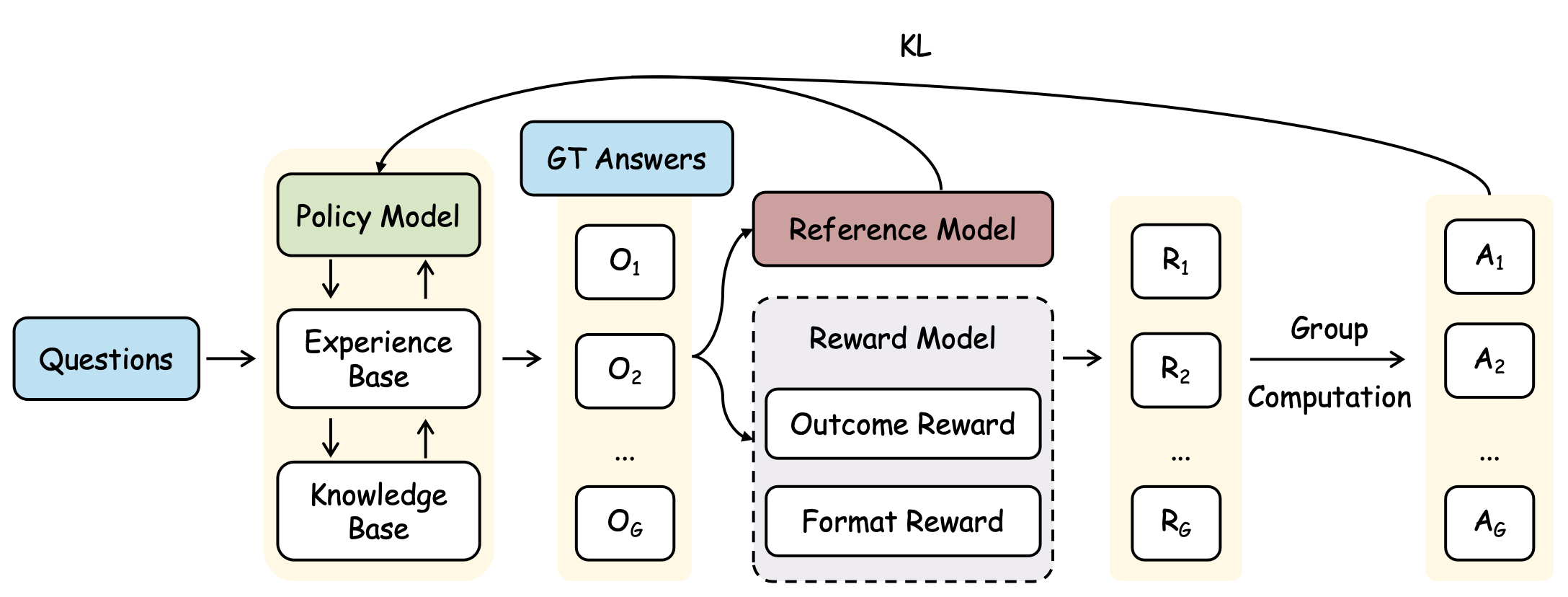
## Flow Diagram: Model Training Process
### Overview
The image is a flow diagram illustrating a model training process. It depicts the flow of information and computation between different components, including input questions, knowledge bases, policy models, reward models, and reference models, ultimately leading to a set of answers. The diagram also shows the use of KL divergence as a feedback mechanism.
### Components/Axes
* **Input:**
* `Questions` (light blue rounded rectangle)
* **Main Components (beige background):**
* `Policy Model` (green rounded rectangle)
* `Experience Base` (white rounded rectangle)
* `Knowledge Base` (white rounded rectangle)
* `O1`, `O2`, ..., `OG` (white rounded rectangles)
* `R1`, `R2`, ..., `RG` (white rounded rectangles)
* `A1`, `A2`, ..., `AG` (white rounded rectangles)
* **Reference and Reward:**
* `GT Answers` (light blue rounded rectangle)
* `Reference Model` (light brown rounded rectangle)
* `Reward Model` (dashed border, light gray rounded rectangle)
* `Outcome Reward` (white rounded rectangle)
* `Format Reward` (white rounded rectangle)
* **Process Labels:**
* `Group Computation`
* **Feedback:**
* `KL` (Kullback-Leibler divergence)
### Detailed Analysis
1. **Input:** The process begins with `Questions` (light blue) which are fed into a system with a `Policy Model` (green), `Experience Base` (white), and `Knowledge Base` (white).
2. **Policy Model Interaction:** The `Policy Model` interacts with both the `Experience Base` and the `Knowledge Base`, indicated by two-way arrows.
3. **Output Generation:** The output from the `Experience Base` is a series of elements `O1`, `O2`, ..., `OG`.
4. **Reward Mechanism:**
* The `Reference Model` (light brown) receives input from `O1`, `O2`, ..., `OG`.
* The `Reward Model` (light gray, dashed border) consists of `Outcome Reward` and `Format Reward`. It receives input from `O1`, `O2`, ..., `OG`.
* The output of the `Reward Model` is a series of elements `R1`, `R2`, ..., `RG`.
5. **Group Computation:** The elements `R1`, `R2`, ..., `RG` undergo `Group Computation` to produce the final answers `A1`, `A2`, ..., `AG`.
6. **Feedback Loop:**
* The `GT Answers` (light blue) and the `Reference Model` (light brown) provide feedback to the `Policy Model` (green) via `KL` divergence.
* The `GT Answers` (light blue) also provide feedback to the `Reward Model` (light gray, dashed border) via `KL` divergence.
* The `GT Answers` (light blue) also provide feedback to the `Group Computation` via `KL` divergence.
### Key Observations
* The diagram illustrates a closed-loop system where the `Policy Model` is continuously refined based on feedback from the `Reference Model`, `Reward Model`, and `GT Answers`.
* The `Reward Model` is composed of two distinct reward types: `Outcome Reward` and `Format Reward`, suggesting a multi-faceted evaluation of the generated outputs.
* The use of `KL` divergence indicates a method for comparing probability distributions, likely between the generated outputs and the ground truth answers.
### Interpretation
The diagram represents a reinforcement learning or imitation learning framework for training a model to answer questions. The `Policy Model` generates answers based on its current state, informed by the `Experience Base` and `Knowledge Base`. The `Reference Model` and `Reward Model` evaluate these answers, providing feedback to refine the `Policy Model`. The `GT Answers` serve as the gold standard for evaluation. The `KL` divergence is used to quantify the difference between the model's output distribution and the ground truth distribution, guiding the learning process. The `Group Computation` step suggests that the final answers are generated by aggregating or processing the individual rewards. This setup allows the model to learn both the content and the format of the answers, improving its overall performance.