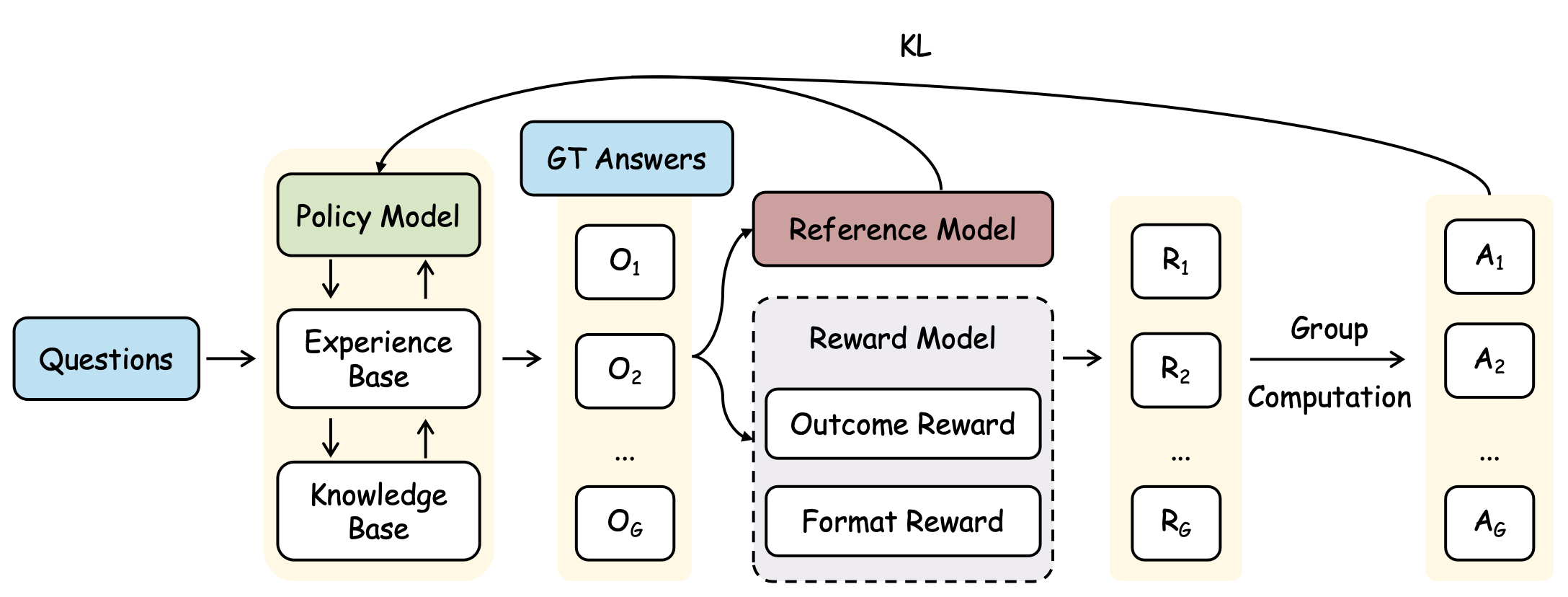
## System Architecture Diagram: Reinforcement Learning with Reward Models
### Overview
The image displays a technical flowchart illustrating a machine learning training pipeline, likely for a reinforcement learning from human feedback (RLHF) or similar alignment process. The diagram shows the flow from input questions to final answers, incorporating a policy model, experience/knowledge bases, ground truth answers, a reference model, and a reward model with outcome and format components. The process involves generating multiple outputs, scoring them, and performing group computation to select or aggregate final answers.
### Components/Axes
The diagram is organized into distinct functional blocks connected by directional arrows indicating data flow. Key components are labeled as follows:
1. **Input (Leftmost):** A blue box labeled `Questions`.
2. **Core Model Block (Left-Center, Yellow Background):** Contains three interconnected components:
* `Policy Model` (Green box)
* `Experience Base` (White box)
* `Knowledge Base` (White box)
* Arrows indicate bidirectional communication between the Policy Model and Experience Base, and between the Experience Base and Knowledge Base.
3. **Ground Truth (Top-Center):** A blue box labeled `GT Answers`.
4. **Output Generation (Center):** A vertical column of white boxes labeled `O₁`, `O₂`, ..., `O_G`. An arrow from the Core Model Block points to this column.
5. **Evaluation Models (Center-Right):**
* `Reference Model` (Red/Brown box)
* `Reward Model` (Dashed-line box containing two sub-components):
* `Outcome Reward`
* `Format Reward`
* Arrows from the `O₁...O_G` column point to both the Reference Model and the Reward Model.
6. **Reward Scores (Right-Center):** A vertical column of white boxes labeled `R₁`, `R₂`, ..., `R_G`. An arrow from the Reward Model points to this column.
7. **Final Output (Rightmost):** A vertical column of white boxes labeled `A₁`, `A₂`, ..., `A_G`.
8. **Process Labels:**
* `KL`: A curved arrow labeled "KL" originates from the `Policy Model` and points to the final output column (`A₁...A_G`).
* `Group Computation`: Text placed between the `R₁...R_G` column and the `A₁...A_G` column, with an arrow pointing from the former to the latter.
### Detailed Analysis
The diagram details a sequential and parallel processing flow:
1. **Input & Generation:** `Questions` are fed into a system comprising a `Policy Model`, `Experience Base`, and `Knowledge Base`. This system generates a group of `G` outputs, denoted as `O₁` through `O_G`.
2. **Parallel Evaluation:** Each output `O_i` is evaluated in parallel by two entities:
* A `Reference Model` (likely a pre-trained or baseline model).
* A composite `Reward Model` that assesses both the `Outcome Reward` (e.g., correctness, quality) and the `Format Reward` (e.g., adherence to structural guidelines).
3. **Reward Assignment:** The Reward Model produces a corresponding reward score `R_i` for each output `O_i`.
4. **Aggregation & Selection:** The set of reward scores `R₁...R_G` undergoes `Group Computation`. This step likely involves comparing, normalizing, or aggregating the scores (e.g., using a softmax or best-of-n selection) to produce the final answer group `A₁...A_G`.
5. **Regularization:** A `KL` (Kullback-Leibler divergence) constraint is applied, connecting the `Policy Model` to the final answers `A₁...A_G`. This is a common technique in RLHF to prevent the policy from deviating too far from its initial state, ensuring stability.
### Key Observations
* **Group-Based Processing:** The use of subscripts `1` to `G` for outputs (`O`), rewards (`R`), and answers (`A`) indicates the system processes multiple candidates in parallel for each input question.
* **Dual Reward Components:** The explicit separation of `Outcome Reward` and `Format Reward` within the dashed `Reward Model` box highlights a multi-faceted evaluation criterion.
* **Bidirectional Knowledge Flow:** The arrows between `Policy Model`, `Experience Base`, and `Knowledge Base` suggest an iterative or memory-augmented generation process, not a simple feed-forward pass.
* **Architectural Separation:** The `Reference Model` is distinct from the `Reward Model`, suggesting it may serve a different purpose, such as providing a baseline for comparison or being part of the KL divergence calculation.
### Interpretation
This diagram represents a sophisticated training or inference architecture for aligning a language model (`Policy Model`) with human preferences. The process can be interpreted as follows:
1. **Exploration:** For a given question, the policy explores multiple potential answers (`O₁...O_G`) by leveraging its experience and a knowledge base.
2. **Critique:** Each candidate answer is critically evaluated by a specialized `Reward Model` that judges both substantive quality (`Outcome`) and presentation (`Format`). The `Reference Model` likely provides a stability anchor or a baseline score.
3. **Selection & Refinement:** The `Group Computation` step acts as a filter or aggregator, using the reward scores to distill the best answers (`A₁...A_G`). The `KL` penalty ensures this refinement process doesn't cause the policy to become erratic or forget its foundational knowledge.
The overall goal is to produce answers that are not only correct and well-formatted but also aligned with a reward signal derived from human preferences (embodied in the Reward Model), while maintaining training stability via the KL constraint. This is a hallmark of modern RLHF pipelines used to make AI systems more helpful, harmless, and honest. The architecture emphasizes generating and critically evaluating multiple hypotheses before committing to a final response.