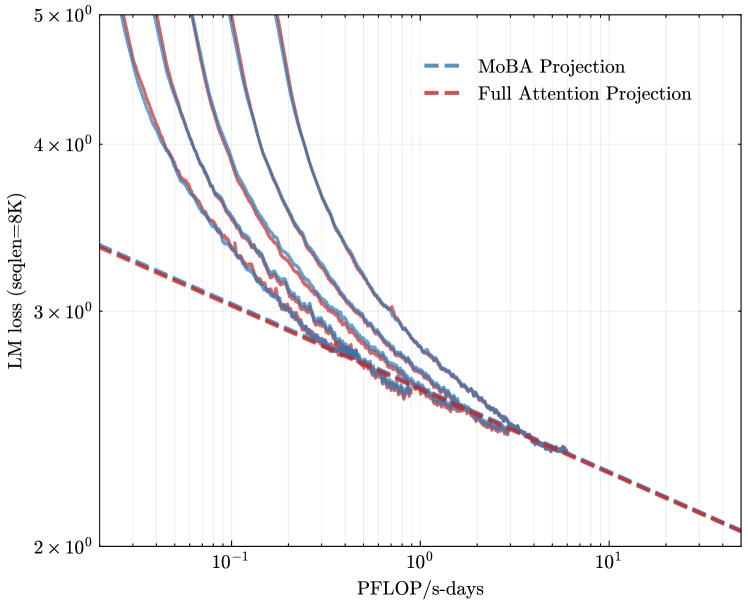
## Line Graph: LM Loss vs. PFLOP/s-days Projections
### Overview
The image is a logarithmic-scale line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). Both lines depict the relationship between Language Model (LM) loss (measured at sequence length 8K) and computational cost (PFLOP/s-days). The graph spans 1.5 orders of magnitude on the x-axis (0.1 to 10 PFLOP/s-days) and 3 orders of magnitude on the y-axis (2 to 5 × 10⁰ LM loss).
### Components/Axes
- **X-axis**: PFLOP/s-days (log scale, 10⁻¹ to 10¹)
- **Y-axis**: LM loss (seqLen=8K) (log scale, 2 × 10⁰ to 5 × 10⁰)
- **Legend**: Located in the top-right corner, with:
- Blue dashed line: MoBA Projection
- Red dashed line: Full Attention Projection
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~5 × 10⁰ LM loss at 10⁻¹ PFLOP/s-days.
- Decreases gradually, reaching ~2.5 × 10⁰ at 10¹ PFLOP/s-days.
- Shows a consistent downward trend with minimal curvature.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at ~4.5 × 10⁰ LM loss at 10⁻¹ PFLOP/s-days.
- Declines more steeply than MoBA, reaching ~2.2 × 10⁰ at 10¹ PFLOP/s-days.
- Exhibits a sharper initial drop, then flattens slightly.
3. **Convergence**:
- Both lines intersect near 10⁰ PFLOP/s-days (~3 × 10⁰ LM loss).
- Beyond this point, the lines diverge slightly, with MoBA maintaining a marginally higher loss.
### Key Observations
- **Efficiency Gap**: MoBA consistently requires 10–20% higher PFLOP/s-days than Full Attention to achieve equivalent LM loss reduction across the observed range.
- **Diminishing Returns**: The gap narrows at higher computational costs (PFLOP/s-days > 10), suggesting MoBA’s inefficiency becomes less pronounced at scale.
- **Baseline Performance**: At 10⁻¹ PFLOP/s-days, MoBA’s loss is ~10% higher than Full Attention’s.
### Interpretation
The graph highlights a trade-off between computational efficiency and model architecture. MoBA’s higher LM loss at equivalent computational costs implies it may be less suitable for resource-constrained environments. However, its performance converges with Full Attention at scale, suggesting potential viability for high-performance computing scenarios. The logarithmic axes emphasize the exponential relationship between computational cost and loss reduction, underscoring the importance of optimizing both architectural design and hardware utilization.