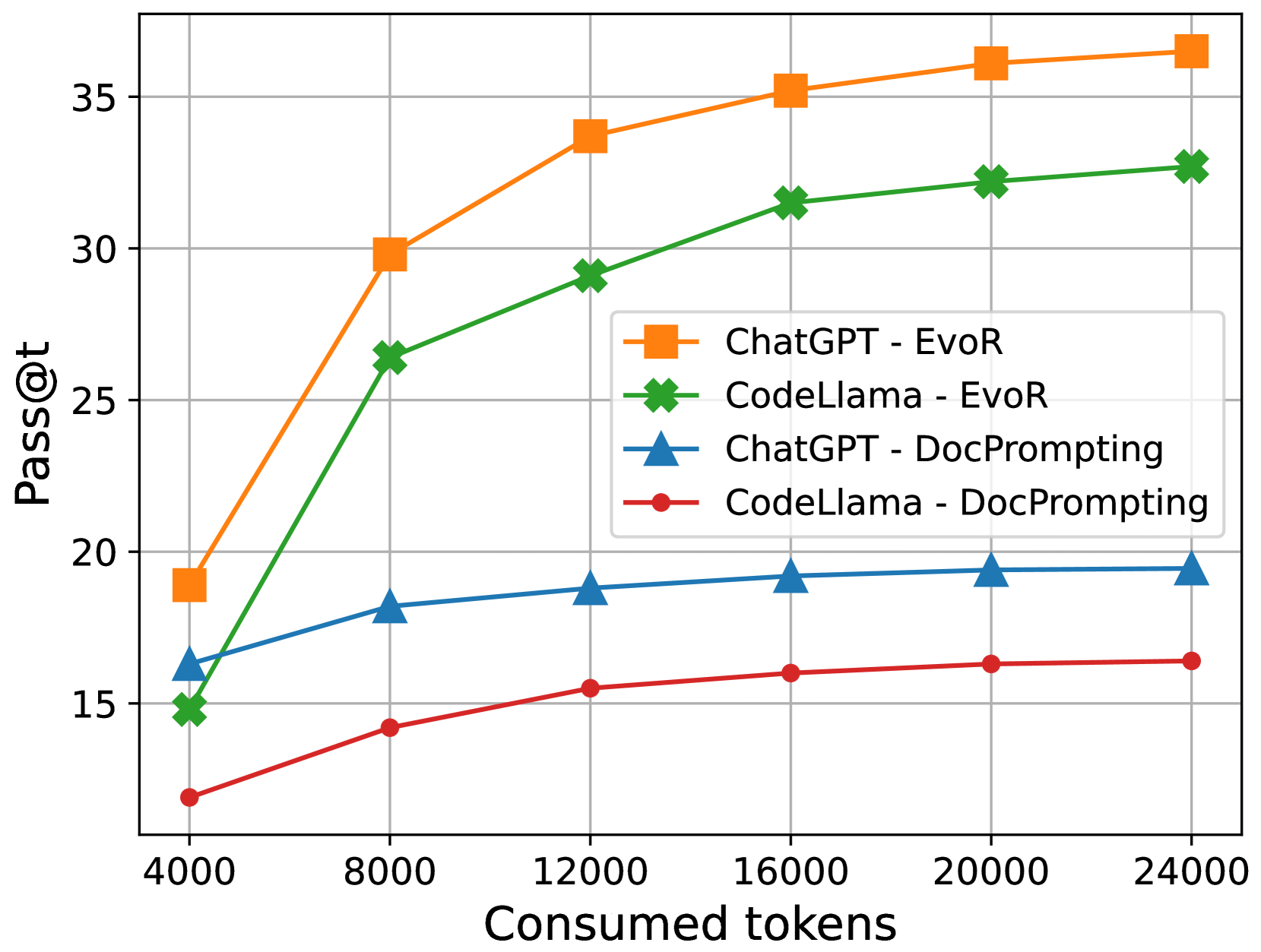
## Performance Comparison Line Chart: Pass@t vs. Consumed Tokens
### Overview
This image is a line chart comparing the performance of two large language models (ChatGPT and CodeLlama) using two different prompting methods (EvoR and DocPrompting). Performance is measured by the "Pass@t" metric as a function of the number of "Consumed tokens."
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis (Horizontal):**
* **Label:** "Consumed tokens"
* **Scale:** Linear scale.
* **Markers/Ticks:** 4000, 8000, 12000, 16000, 20000, 24000.
* **Y-Axis (Vertical):**
* **Label:** "Pass@t"
* **Scale:** Linear scale.
* **Markers/Ticks:** 15, 20, 25, 30, 35.
* **Legend (Positioned center-right):**
* **Orange Square (■):** "ChatGPT - EvoR"
* **Green Cross (✖):** "CodeLlama - EvoR"
* **Blue Triangle (▲):** "ChatGPT - DocPrompting"
* **Red Circle (●):** "CodeLlama - DocPrompting"
### Detailed Analysis
The chart plots four distinct data series. The trend for each is described below, followed by approximate data points extracted from the visual markers.
**1. ChatGPT - EvoR (Orange line with square markers)**
* **Trend:** Shows the steepest initial increase and achieves the highest overall performance. The curve rises sharply from 4000 to 12000 tokens and then continues to increase at a slower, diminishing rate.
* **Approximate Data Points:**
* 4000 tokens: ~19
* 8000 tokens: ~30
* 12000 tokens: ~34
* 16000 tokens: ~35.5
* 20000 tokens: ~36.5
* 24000 tokens: ~37
**2. CodeLlama - EvoR (Green line with cross markers)**
* **Trend:** Follows a similar shape to ChatGPT-EvoR but consistently performs at a lower level. It also shows strong initial growth that tapers off.
* **Approximate Data Points:**
* 4000 tokens: ~15
* 8000 tokens: ~26.5
* 12000 tokens: ~29
* 16000 tokens: ~31.5
* 20000 tokens: ~32.5
* 24000 tokens: ~33
**3. ChatGPT - DocPrompting (Blue line with triangle markers)**
* **Trend:** Shows a moderate, steady increase that plateaus early. Performance is significantly lower than both EvoR methods.
* **Approximate Data Points:**
* 4000 tokens: ~16.5
* 8000 tokens: ~18
* 12000 tokens: ~19
* 16000 tokens: ~19.5
* 20000 tokens: ~19.5
* 24000 tokens: ~19.5
**4. CodeLlama - DocPrompting (Red line with circle markers)**
* **Trend:** Exhibits the lowest performance and the flattest growth curve. It increases slightly and then plateaus.
* **Approximate Data Points:**
* 4000 tokens: ~12
* 8000 tokens: ~14.5
* 12000 tokens: ~15.5
* 16000 tokens: ~16
* 20000 tokens: ~16.5
* 24000 tokens: ~16.5
### Key Observations
1. **Method Dominance:** The "EvoR" prompting method (orange and green lines) dramatically outperforms the "DocPrompting" method (blue and red lines) for both models across all token counts.
2. **Model Comparison:** When using the same prompting method, ChatGPT consistently outperforms CodeLlama. The performance gap is larger with EvoR than with DocPrompting.
3. **Diminishing Returns:** All four curves show diminishing returns. The most significant performance gains occur between 4000 and 12000 consumed tokens. After approximately 16000 tokens, the rate of improvement slows considerably for all series.
4. **Performance Hierarchy:** The final performance ranking at 24000 tokens is clear: 1) ChatGPT-EvoR, 2) CodeLlama-EvoR, 3) ChatGPT-DocPrompting, 4) CodeLlama-DocPrompting.
### Interpretation
The data suggests that the choice of prompting strategy (EvoR vs. DocPrompting) has a more significant impact on the Pass@t performance metric than the choice of base model (ChatGPT vs. CodeLlama) within this test. EvoR appears to be a far more effective technique for scaling performance with increased token consumption.
The chart demonstrates a clear positive correlation between consumed tokens and Pass@t score, but with a logarithmic-like curve, indicating that simply adding more tokens yields progressively smaller benefits. This implies there is an optimal token budget range (around 12000-16000 in this context) where performance is maximized relative to resource expenditure.
The consistent performance gap between models using the same method suggests underlying differences in model capability or how they interact with the specific prompting techniques. The fact that the gap between ChatGPT and CodeLlama is wider with EvoR might indicate that EvoR is better at leveraging the strengths of a more capable model like ChatGPT.