## Chart: Accuracy vs. Thinking Compute
### Overview
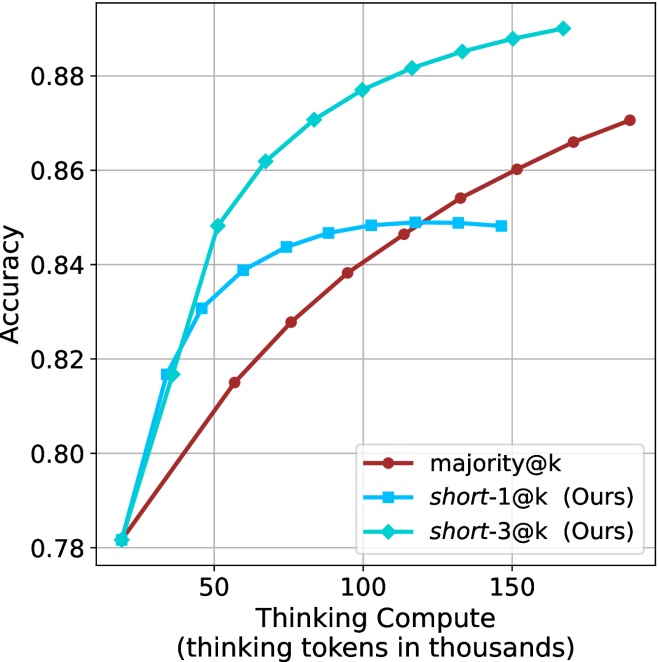
The image is a line chart comparing the accuracy of three different methods ("majority@k", "short-1@k (Ours)", and "short-3@k (Ours)") as a function of "Thinking Compute" (measured in thousands of thinking tokens). The chart shows how accuracy changes as the computational resources increase for each method.
### Components/Axes
* **X-axis:** "Thinking Compute" (thinking tokens in thousands). Scale ranges from 0 to 150, with tick marks at 50, 100, and 150.
* **Y-axis:** "Accuracy". Scale ranges from 0.78 to 0.88, with tick marks at 0.78, 0.80, 0.82, 0.84, 0.86, and 0.88.
* **Legend:** Located in the bottom-right corner of the chart.
* Brown line with circle markers: "majority@k"
* Blue line with square markers: "short-1@k (Ours)"
* Teal line with diamond markers: "short-3@k (Ours)"
### Detailed Analysis
* **majority@k (Brown line with circle markers):** The accuracy starts at approximately 0.78 at 20k thinking tokens and increases steadily, reaching approximately 0.87 at 160k thinking tokens.
* (20, 0.78)
* (50, 0.815)
* (100, 0.84)
* (160, 0.87)
* **short-1@k (Ours) (Blue line with square markers):** The accuracy increases rapidly initially, then plateaus.
* (20, 0.78)
* (50, 0.84)
* (80, 0.85)
* (120, 0.85)
* (140, 0.85)
* **short-3@k (Ours) (Teal line with diamond markers):** The accuracy increases rapidly and then slows down, but remains the highest among the three methods.
* (20, 0.78)
* (50, 0.85)
* (80, 0.87)
* (120, 0.88)
* (160, 0.89)
### Key Observations
* "short-3@k (Ours)" consistently outperforms the other two methods across all levels of "Thinking Compute".
* "short-1@k (Ours)" shows diminishing returns as "Thinking Compute" increases, plateauing at a lower accuracy than "short-3@k (Ours)".
* "majority@k" shows a steady increase in accuracy with increasing "Thinking Compute", but remains below "short-3@k (Ours)".
### Interpretation
The chart suggests that the "short-3@k (Ours)" method is the most effective in terms of accuracy for a given amount of "Thinking Compute". The "short-1@k (Ours)" method provides a good initial boost in accuracy but quickly plateaus, indicating that it may not scale as well as the other methods. The "majority@k" method shows a consistent improvement with increased compute, but its overall performance is lower than "short-3@k (Ours)". The data implies that the "short-3@k" method is the most efficient use of computational resources for achieving higher accuracy in this context.