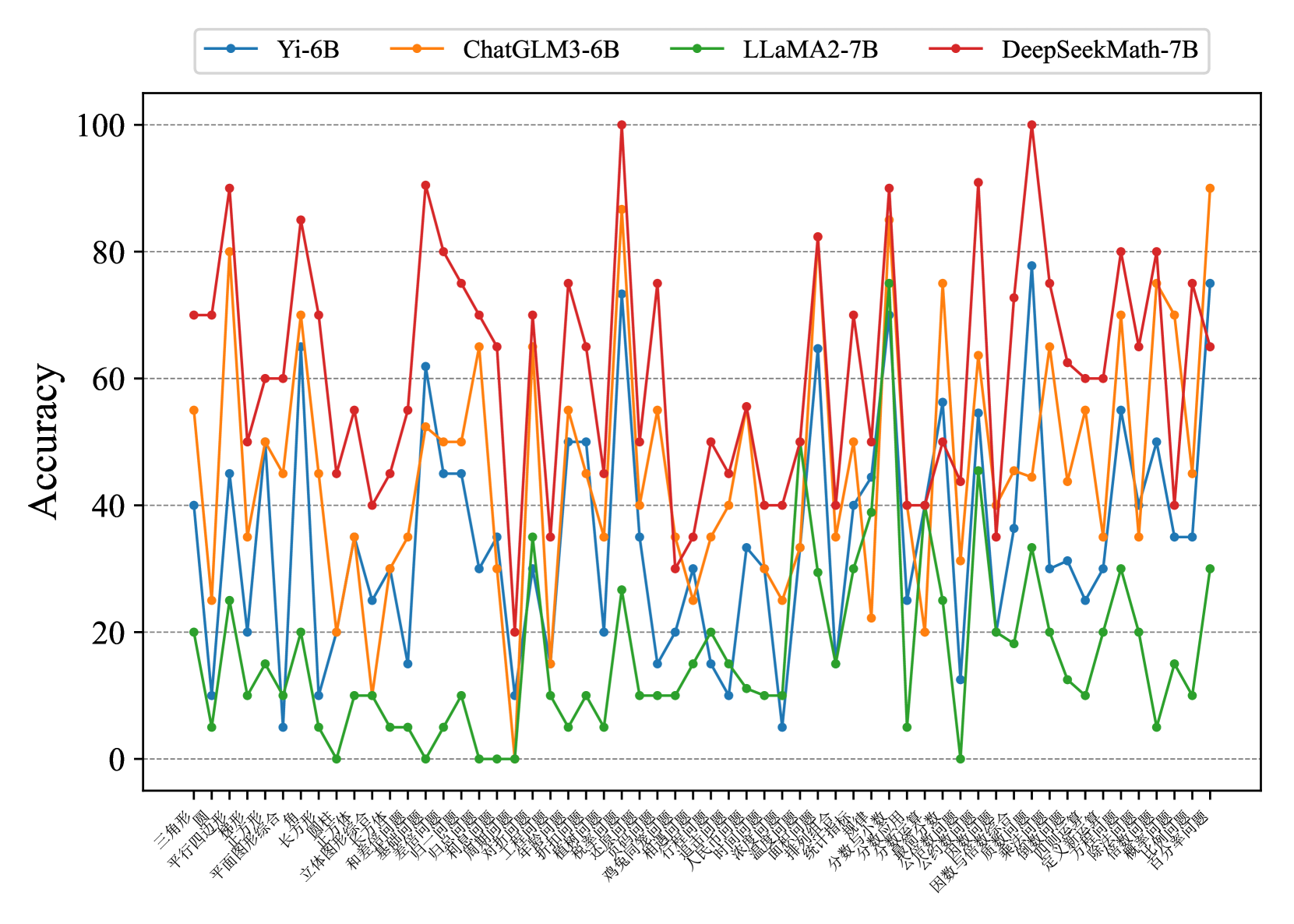
## Line Chart: Model Accuracy Comparison
### Overview
The image is a line chart comparing the accuracy of four different language models (Yi-6B, ChatGLM3-6B, LLaMA2-7B, and DeepSeekMath-7B) across a range of math problem types. The x-axis represents different problem types (in Chinese), and the y-axis represents accuracy, ranging from 0 to 100.
### Components/Axes
* **Title:** The chart has no explicit title.
* **X-axis:** Represents different math problem types, labeled in Chinese. The labels are very dense and difficult to read individually.
* **Y-axis:** Represents "Accuracy", ranging from 0 to 100 in increments of 20. Horizontal gridlines are present at each increment.
* **Legend:** Located at the top of the chart.
* Blue line: Yi-6B
* Orange line: ChatGLM3-6B
* Green line: LLaMA2-7B
* Red line: DeepSeekMath-7B
### Detailed Analysis
The chart displays the accuracy of each model across various problem types. Due to the density of the x-axis labels and the overlapping lines, precise data extraction is challenging. However, general trends and relative performance can be observed.
Here's a breakdown of the trends for each model:
* **Yi-6B (Blue):** Generally fluctuates between 20 and 60 accuracy, with some dips below 20 and peaks above 60.
* **ChatGLM3-6B (Orange):** Shows more variability, ranging from below 20 to above 80. Appears to perform better than Yi-6B on some problem types but worse on others.
* **LLaMA2-7B (Green):** Consistently has the lowest accuracy, often below 20, and rarely exceeding 40.
* **DeepSeekMath-7B (Red):** Generally exhibits the highest accuracy, frequently above 60, and reaching 100 on at least one problem type. It shows significant fluctuations, indicating varying performance across different problem types.
Due to the Chinese labels on the x-axis, I will provide a transcription of the labels as best as possible, but without translation.
X-Axis Labels (Left to Right):
1. 三角形 (Triangle)
2. 平行四边形 (Parallelogram)
3. 圆形 (Circle)
4. 平面图形综合 (Planar graphics synthesis)
5. 长方形 (Rectangle)
6. 立方体 (Cube)
7. 立体图形 (Three-dimensional graphics)
8. 和差问题 (Sum and difference problem)
9. 差倍问题 (Difference multiple problem)
10. 几何问题 (Geometric problem)
11. 年龄问题 (Age problem)
12. 归一问题 (Reduction to one problem)
13. 归总问题 (Total return problem)
14. 工程问题 (Engineering problem)
15. 植树问题 (Tree planting problem)
16. 盈亏问题 (Profit and loss problem)
17. 鸡兔同笼 (Chicken and rabbit in the same cage)
18. 浓度问题 (Concentration problem)
19. 行程问题 (Travel problem)
20. 相遇问题 (Meeting problem)
21. 时间问题 (Time problem)
22. 人民币问题 (RMB problem)
23. 浓度问题 (Concentration problem)
24. 面积问题 (Area problem)
25. 统计指标 (Statistical indicators)
26. 分数与小数 (Fractions and decimals)
27. 分数应用 (Fraction application)
28. 公倍数问题 (Common multiple problem)
29. 因数与倍数 (Factors and multiples)
30. 乘法问题 (Multiplication problem)
31. 乘除混合 (Mixed multiplication and division)
32. 定义新运算 (Define new operation)
33. 简便计算 (Simple calculation)
34. 除法问题 (Division problem)
35. 概率问题 (Probability problem)
36. 百分率问题 (Percentage problem)
37. 因数分解 (Factorization)
### Key Observations
* DeepSeekMath-7B generally outperforms the other models.
* LLaMA2-7B generally underperforms the other models.
* The performance of all models varies significantly depending on the problem type.
* The x-axis labels are in Chinese, representing different math problem categories.
### Interpretation
The chart provides a comparative analysis of the accuracy of four language models on a diverse set of math problems. The data suggests that DeepSeekMath-7B is the most accurate model overall, while LLaMA2-7B is the least accurate. The significant performance variation across problem types highlights the strengths and weaknesses of each model in specific mathematical domains. This information is valuable for understanding the capabilities of each model and selecting the most appropriate model for a given task. The performance of ChatGLM3-6B and Yi-6B are similar, with ChatGLM3-6B having slightly higher variance.