## Heatmap: Avg JS Divergence vs. Layer for Different Model Components
### Overview
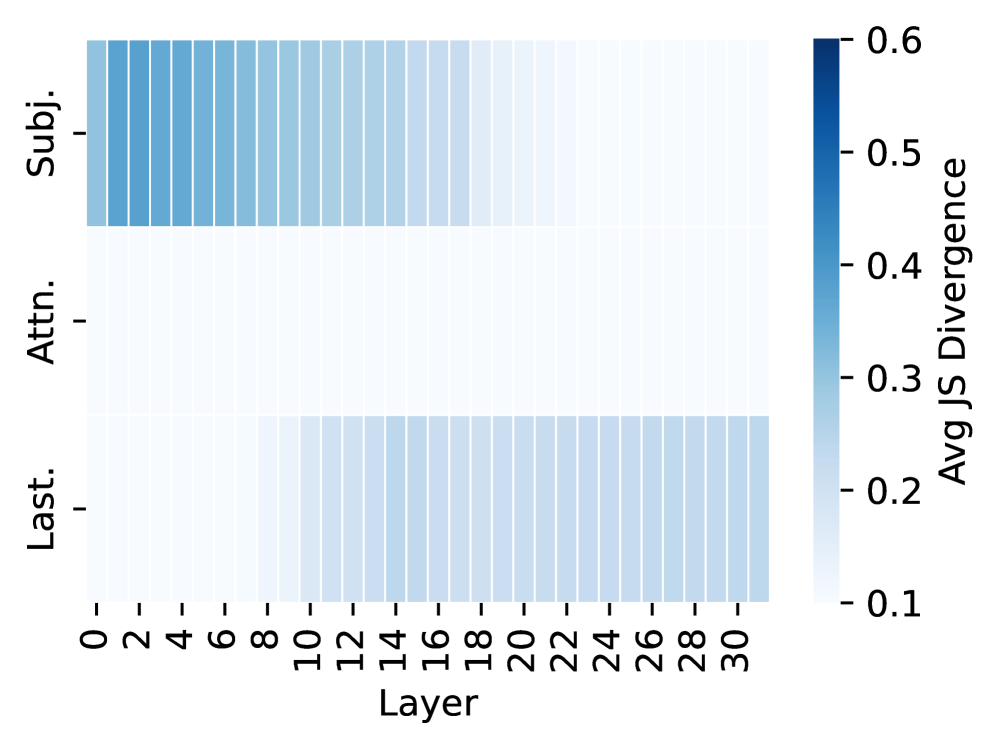
The image is a heatmap visualizing the average Jensen-Shannon (JS) divergence across different layers of a model for three components: Subject (Subj.), Attention (Attn.), and Last. The x-axis represents the layer number, ranging from 0 to 30. The y-axis represents the model component. The color intensity indicates the magnitude of the average JS divergence, with darker blue representing higher divergence and lighter blue representing lower divergence.
### Components/Axes
* **X-axis:** Layer, ranging from 0 to 30 in increments of 2.
* **Y-axis:** Model Component (Subj., Attn., Last.)
* **Color Scale (Legend):** Avg JS Divergence, ranging from 0.1 to 0.6.
* 0.1: Lightest blue
* 0.6: Darkest blue
### Detailed Analysis
* **Subject (Subj.):** The JS divergence is high (dark blue) for layers 0 to approximately 8. From layer 10 onwards, the JS divergence decreases significantly (lighter blue).
* Layers 0-8: Avg JS Divergence ~0.5-0.6
* Layers 10-30: Avg JS Divergence ~0.2
* **Attention (Attn.):** The JS divergence is consistently low (light blue) across all layers (0 to 30).
* Layers 0-30: Avg JS Divergence ~0.1-0.2
* **Last:** The JS divergence is low (light blue) across all layers (0 to 30), with a slight increase compared to the Attention component.
* Layers 0-30: Avg JS Divergence ~0.2
### Key Observations
* The Subject component exhibits a high JS divergence in the initial layers, which then decreases.
* The Attention component consistently shows low JS divergence across all layers.
* The Last component also shows low JS divergence, slightly higher than the Attention component.
### Interpretation
The heatmap suggests that the "Subject" component of the model undergoes significant changes in the initial layers (0-8), as indicated by the high JS divergence. This could imply that the model is actively learning or adapting the representation of the subject in these early layers. The "Attention" component, on the other hand, maintains a relatively stable and low JS divergence across all layers, suggesting that its representation remains consistent throughout the model's processing. The "Last" component's behavior is similar to the "Attention" component, indicating a stable representation. The differences in JS divergence between the components may reflect their roles and the types of information they process within the model. The high initial divergence in the "Subject" component could be due to the model initially struggling to represent the subject effectively, and then converging to a more stable representation as the layers progress.