\n
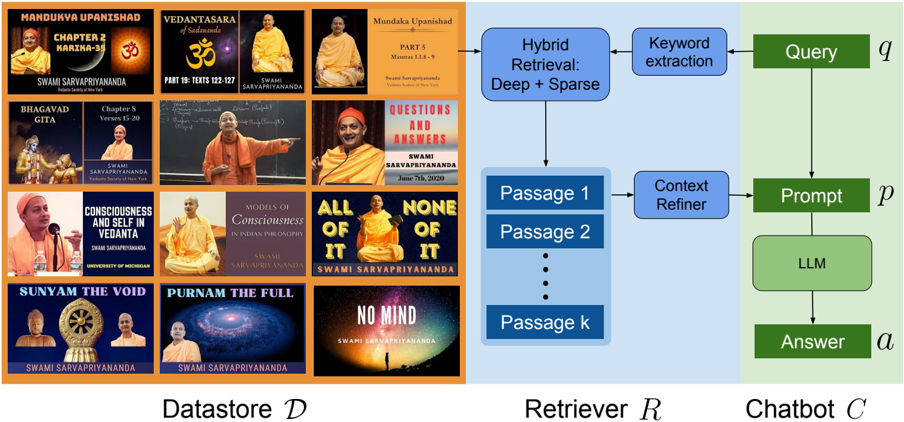
## Diagram: Retrieval Augmented Generation (RAG) System Flow
### Overview
The image depicts a diagram illustrating the flow of information in a Retrieval Augmented Generation (RAG) system. The system consists of three main components: a Datastore (D), a Retriever (R), and a Chatbot. The Datastore contains various images related to Swami Sarvapriyananda's teachings. The Retriever extracts relevant passages from the Datastore based on a user query. The Chatbot then uses these passages to generate an answer.
### Components/Axes
The diagram is divided into three vertical sections labeled:
* **Datastore D**: Located on the left, containing images of book covers and portraits.
* **Retriever R**: Located in the center, showing the process of passage retrieval and context refinement.
* **Chatbot**: Located on the right, illustrating the Large Language Model (LLM) and answer generation.
Key labels and components within each section:
* **Datastore D**: Contains images with titles like "Mandukya Upanishad Chapter 2", "Vedantasara", "Bhagavad Gita", "Consciousness and Self in Vedanta", "Sunyam The Void", "Purnam The Full", "Models of Consciousness in Indian Philosophy", "All of None of It", "Questions and Answers". Each image also includes "Swami Sarvapriyananda" and the University of Michigan logo.
* **Retriever R**: Includes components labeled "Hybrid Retrieval: Deep + Sparse", "Keyword extraction", "Context Refiner", and a list of "Passage 1" through "Passage k".
* **Chatbot**: Includes components labeled "LLM" and "Answer".
* **Flow Arrows**: Arrows indicate the direction of information flow between components.
* **Variables**: "q" represents the Query, "p" represents the Prompt, and "a" represents the Answer.
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. A **Query (q)** is input into the system.
2. **Keyword extraction** is performed on the query.
3. The **Hybrid Retrieval** component (Deep + Sparse) searches the **Datastore (D)** based on the extracted keywords.
4. The Retriever returns **Passage 1** through **Passage k** (a variable number of passages).
5. The **Context Refiner** processes these passages.
6. A **Prompt (p)** is generated using the refined passages.
7. The **LLM** (Large Language Model) receives the prompt.
8. The LLM generates an **Answer (a)**.
The Datastore contains images of the following:
* **Mandukya Upanishad Chapter 2 Karika-38**
* **Vedantasara** Part 3, Mantra 1.14-9
* **Bhagavad Gita** Verses 16-20
* **Consciousness and Self in Vedanta**
* **Sunyam The Void**
* **Purnam The Full**
* **Models of Consciousness in Indian Philosophy**
* **All of None of It**
* **Questions and Answers** June 7th, 2020
Each image in the Datastore is attributed to "Swami Sarvapriyananda" and the University of Michigan.
### Key Observations
The diagram highlights the key steps involved in a RAG system. The use of "Hybrid Retrieval" suggests a combination of semantic and keyword-based search methods. The "Context Refiner" component is crucial for ensuring the LLM receives relevant and concise information. The Datastore is specifically populated with content related to the teachings of Swami Sarvapriyananda.
### Interpretation
This diagram demonstrates a RAG architecture designed to answer questions based on a specific knowledge base – in this case, the teachings of Swami Sarvapriyananda. The system aims to improve the accuracy and relevance of LLM-generated responses by grounding them in factual information retrieved from the Datastore. The hybrid retrieval approach suggests an attempt to balance precision (keyword-based) and recall (semantic-based) in the search process. The Context Refiner is likely used to filter out irrelevant information and format the retrieved passages for optimal LLM consumption. The overall system is designed to provide informed and contextually relevant answers to user queries related to the subject matter contained within the Datastore. The use of a specific teacher's work suggests a focused application of RAG for a specialized domain.