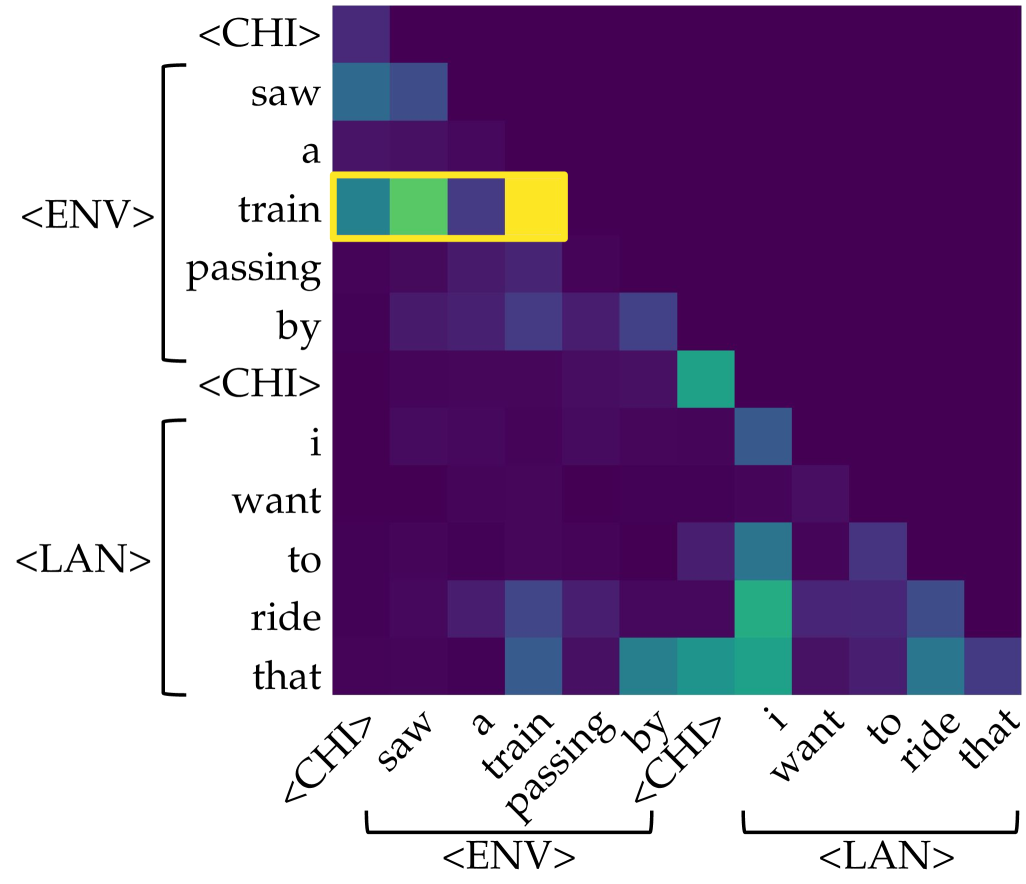
## Heatmap: Attention Weights Between Sentence Tokens
### Overview
The image displays a triangular heatmap visualizing attention weights (or similar similarity scores) between tokens from two sequential sentences. The heatmap uses a color gradient from dark purple (low value) to bright yellow (high value) to represent the strength of association or attention between each pair of tokens. A specific row is highlighted with a yellow bounding box.
### Components/Axes
* **Chart Type:** Triangular heatmap (lower-left triangle filled).
* **Y-Axis (Left):** Lists tokens from two sentences, grouped by special tokens.
* **Group 1 (Bracketed as `<ENV>`):** `<CHI>`, `saw`, `a`, `train`, `passing`, `by`
* **Group 2 (Bracketed as `<LAN>`):** `<CHI>`, `i`, `want`, `to`, `ride`, `that`
* **X-Axis (Bottom):** Lists the same tokens in the same order, rotated at a 45-degree angle.
* **Group 1 (Bracketed as `<ENV>`):** `<CHI>`, `saw`, `a`, `train`, `passing`, `by`
* **Group 2 (Bracketed as `<LAN>`):** `<CHI>`, `i`, `want`, `to`, `ride`, `that`
* **Color Scale:** Implicit gradient. Dark purple represents the lowest values (near 0), transitioning through blue and teal to green and finally bright yellow for the highest values (near 1.0).
* **Highlight:** A yellow rectangular box outlines the entire row corresponding to the token `train` on the Y-axis.
### Detailed Analysis
**Token List (Y-Axis, top to bottom):**
1. `<CHI>` (Start of first sentence group)
2. `saw`
3. `a`
4. `train` **(Highlighted Row)**
5. `passing`
6. `by`
7. `<CHI>` (Start of second sentence group)
8. `i`
9. `want`
10. `to`
11. `ride`
12. `that`
**Data Point Analysis (Row by Row):**
* **`<CHI>` (Row 1):** Very low values (dark purple) across all columns.
* **`saw` (Row 2):** Low to moderate values. Slightly higher (blue) attention to `<CHI>` and `saw` on the x-axis.
* **`a` (Row 3):** Low values (dark purple/blue).
* **`train` (Row 4 - Highlighted):** This row shows the strongest activations in the entire chart.
* Column `train`: **Bright yellow** (highest value, ~1.0).
* Column `a`: **Green** (high value, ~0.7-0.8).
* Column `<CHI>` (first one): **Teal/Blue** (moderate value, ~0.5-0.6).
* Column `saw`: **Blue** (moderate-low value, ~0.4).
* Other columns: Dark purple (very low).
* **`passing` (Row 5):** Low values, with a slight blue tint in columns `train` and `passing`.
* **`by` (Row 6):** Low values, with a slight blue tint in columns `passing` and `by`.
* **`<CHI>` (Row 7):** Shows a notable **teal/green** activation in the column for the second `<CHI>` token.
* **`i` (Row 8):** Low values, with a slight blue tint in its own column.
* **`want` (Row 9):** Low values.
* **`to` (Row 10):** Low values, with a slight blue tint in its own column and the `ride` column.
* **`ride` (Row 11):** Shows moderate **teal/green** activation in its own column and the `that` column.
* **`that` (Row 12):** Shows moderate **teal/green** activation in its own column and the `ride` column.
**Key Trend:** The heatmap is largely dark (low values) except for a strong diagonal pattern of self-attention (e.g., `train` to `train`, `ride` to `ride`) and specific cross-token relationships, most prominently within the highlighted `train` row.
### Key Observations
1. **Dominant Feature:** The token `train` exhibits exceptionally strong self-attention and significant attention to the preceding article `a`.
2. **Sentence Boundary Marker:** The second `<CHI>` token (Row 7) shows a distinct activation, suggesting it plays a role in separating or linking the two sentence segments.
3. **Verb-Object Relationship:** In the second sentence, the verb `ride` and the object `that` show mutual moderate attention.
4. **Asymmetry:** The attention pattern is not symmetric. For example, the attention from `train` to `a` (green) is much stronger than the attention from `a` to `train` (dark purple).
5. **Grouping:** The special tokens `<ENV>` and `<LAN>` successfully bracket two distinct semantic units: an observation ("saw a train passing by") and a desire ("i want to ride that").
### Interpretation
This heatmap likely visualizes the **attention weights** from a transformer-based neural network model (like BERT or GPT) processing the concatenated text: `"<CHI> saw a train passing by <CHI> i want to ride that"`. The special tokens `<ENV>` (Environment?) and `<LAN>` (Language?) are probably added by the model or researchers to denote different contextual segments.
* **What it demonstrates:** The model's "focus" when processing each word. The highlighted row shows that when the model processes the word `train`, it pays the most attention to itself (reinforcing its own meaning) and to the word `a`, correctly identifying the noun phrase "a train". This is a sign of syntactic understanding.
* **Relationships:** The mutual attention between `ride` and `that` indicates the model is linking the action to its intended object. The activation at the second `<CHI>` suggests it's using this token to manage the transition between the two clauses or contexts.
* **Anomalies/Notable Points:** The very strong, isolated peak at `train`→`train` is notable. It could indicate that `train` is the most information-rich or central token in the first clause for this model's internal representation. The overall sparsity (many dark cells) is typical for attention maps, showing the model focuses on a few key relationships rather than all possible pairs.
**Language:** The primary language of the tokens is **English**. The special tokens (`<CHI>`, `<ENV>`, `<LAN>`) are symbolic markers, not part of standard English.