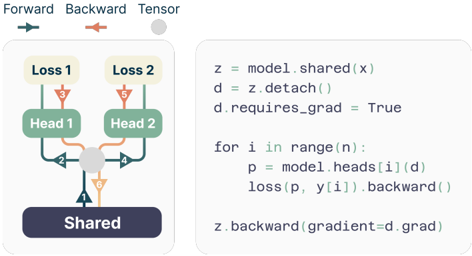
## Diagram: Multi-Head Model with Shared Layer and Gradient Flow
### Overview
The image depicts a diagram illustrating the forward and backward pass of a multi-head model with a shared layer. The diagram shows the flow of data and gradients through the model, highlighting the shared layer and the individual heads. A code snippet is provided alongside the diagram, likely representing the implementation of the backward pass.
### Components/Axes
The diagram consists of the following components:
* **Shared Layer:** A blue rounded rectangle labeled "Shared".
* **Heads:** Two green rounded rectangles labeled "Head 1" and "Head 2".
* **Losses:** Two yellow rounded rectangles labeled "Loss 1" and "Loss 2".
* **Arrows:** Arrows indicating the direction of data flow (forward pass - blue) and gradient flow (backward pass - orange). Numbers are placed along the arrows to indicate the order of operations.
* **Legend:** A small legend at the top-left corner indicating the meaning of the arrow colors: "Forward" (blue), "Backward" (orange), and "Tensor" (grey).
* **Code Snippet:** A block of code written in Python, detailing the backward pass calculation.
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. **Forward Pass:** Data flows from the "Shared" layer (arrow 1, blue) to both "Head 1" and "Head 2" (arrows 2, blue).
2. **Loss Calculation:** Each head then calculates a loss: "Head 1" to "Loss 1" (arrow 3, blue) and "Head 2" to "Loss 2" (arrow 5, blue).
3. **Backward Pass:** Gradients flow backward from "Loss 1" and "Loss 2". "Loss 1" to "Head 1" (arrow 3, orange), "Loss 2" to "Head 2" (arrow 5, orange).
4. **Gradient Aggregation:** Gradients from both heads converge at the "Shared" layer (arrows 4 and 6, orange).
The code snippet details the backward pass:
```python
z = model.shared(x)
d = z.detach()
d.requires_grad = True
for i in range(n):
p = model.heads[i](d)
loss(p, y[i]).backward()
z.backward(gradient=d.grad)
```
* `z = model.shared(x)`: The shared layer is applied to the input `x`.
* `d = z.detach()`: A detached copy of `z` is created. This prevents gradients from flowing back through `z` directly during the head calculations.
* `d.requires_grad = True`: Gradients are enabled for the detached tensor `d`.
* `for i in range(n):`: A loop iterates through the heads.
* `p = model.heads[i](d)`: Each head `i` is applied to the detached tensor `d`.
* `loss(p, y[i]).backward()`: The loss is calculated for the output `p` and the target `y[i]`, and the backward pass is initiated.
* `z.backward(gradient=d.grad)`: The gradient is backpropagated through the shared layer `z`, using the gradient of the detached tensor `d`.
### Key Observations
* The shared layer is central to the model, receiving input from the data and providing output to multiple heads.
* The use of `detach()` in the code suggests a specific gradient flow strategy, likely to avoid unintended gradient accumulation in the shared layer.
* The code snippet implements a loop to handle multiple heads, indicating a multi-head architecture.
* The numbers on the arrows indicate the order of operations, which is important for understanding the flow of information.
### Interpretation
The diagram and code snippet illustrate a common technique in deep learning, particularly in multi-task learning or multi-head attention mechanisms. The shared layer allows for parameter sharing between different heads, potentially improving generalization and reducing the number of parameters. The use of `detach()` and the subsequent gradient manipulation suggest a careful control of gradient flow, which is crucial for training such models effectively. The diagram visually represents the computational graph, making it easier to understand the dependencies between different parts of the model. The code snippet provides a concrete implementation of the backward pass, allowing for a deeper understanding of the gradient calculation process. The overall design suggests a model where different heads can learn different representations from the same shared features, potentially leading to improved performance on multiple tasks.