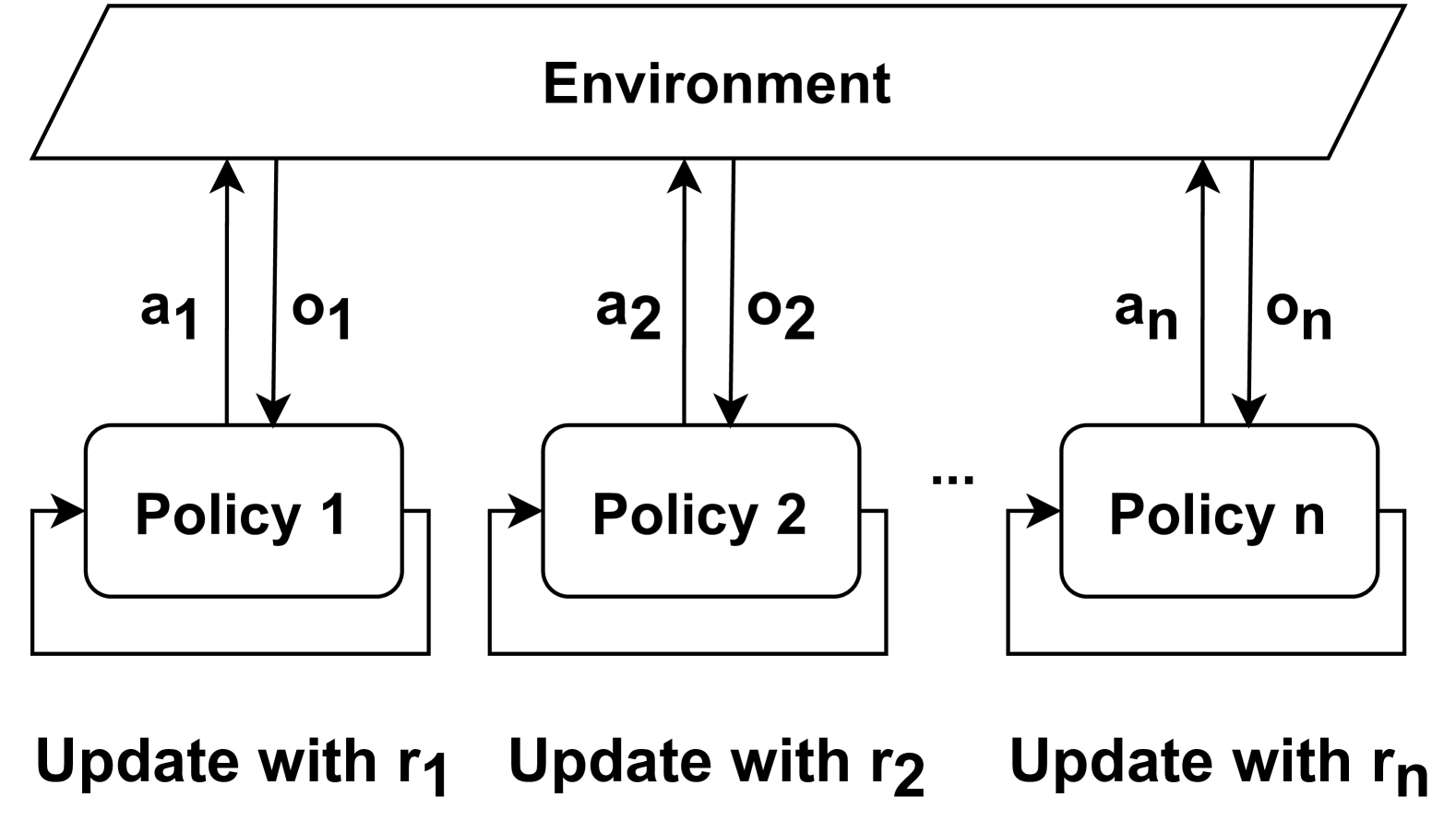
\n
## Diagram: Multi-Agent Reinforcement Learning Framework
### Overview
The image is a technical diagram illustrating a multi-agent reinforcement learning (MARL) framework. It depicts multiple independent learning agents (policies) interacting with a shared environment. Each agent operates in parallel, receiving observations and sending actions to the environment, and updates its policy based on its own reward signal.
### Components/Axes
The diagram is structured into three main vertical sections, with a clear hierarchical flow.
1. **Top Section (Environment):**
* A large, light-gray parallelogram spanning the top of the diagram.
* Contains the single label: **"Environment"**.
2. **Middle Section (Agents/Policies):**
* Three rounded rectangles are shown, representing individual learning agents.
* Labels from left to right: **"Policy 1"**, **"Policy 2"**, **"Policy n"**.
* An ellipsis (**"..."**) is placed between "Policy 2" and "Policy n", indicating a sequence that can be extended to an arbitrary number of agents.
* **Interaction Arrows:** Each policy box has two vertical arrows connecting it to the Environment parallelogram above.
* An upward-pointing arrow labeled with an action: **"a₁"** (for Policy 1), **"a₂"** (for Policy 2), **"aₙ"** (for Policy n).
* A downward-pointing arrow labeled with an observation: **"o₁"** (for Policy 1), **"o₂"** (for Policy 2), **"oₙ"** (for Policy n).
* **Update Loop:** Each policy box has a self-referential arrow forming a loop on its left side, indicating an internal update process.
3. **Bottom Section (Update Instructions):**
* Text is placed directly below each corresponding policy box.
* Labels from left to right: **"Update with r₁"**, **"Update with r₂"**, **"Update with rₙ"**.
* The "r" variables (r₁, r₂, rₙ) represent the reward signals used by each respective policy for its learning update.
### Detailed Analysis
* **Spatial Layout:** The Environment is the central, top-level entity. The policies are arranged horizontally below it, suggesting parallel and independent operation. The update instructions are anchored at the bottom, directly linked to their respective policies.
* **Flow of Information:**
1. Each Policy `i` sends an action `aᵢ` to the Environment.
2. The Environment returns an observation `oᵢ` to that same Policy `i`.
3. Policy `i` then performs an internal update using its dedicated reward signal `rᵢ`.
* **Notation:** The diagram uses subscript notation (`1, 2, ..., n`) to generalize the framework for any number of agents. The variables follow a consistent pattern: `a` for action, `o` for observation, `r` for reward.
### Key Observations
* **Independent Learning:** There are no arrows connecting the different Policy boxes to each other. This visually emphasizes that the agents are learning independently, without direct communication or shared parameters.
* **Shared Environment:** All policies interact with the same, singular "Environment" block, indicating a shared state space or world that all agents influence and observe.
* **Scalability:** The use of "Policy n" and the ellipsis explicitly denotes that the framework is designed to scale to a variable number of agents.
* **Closed-Loop Systems:** Each agent-environment pair forms a classic reinforcement learning feedback loop (state -> policy -> action -> new state/reward). The diagram shows `n` such loops operating in parallel.
### Interpretation
This diagram represents a **decentralized** or **independent learners** approach to multi-agent reinforcement learning. The core concept is that multiple agents coexist and learn within a common environment, but their learning processes are isolated from one another.
* **What it demonstrates:** It models scenarios like a group of robots navigating a shared space, multiple trading algorithms in a market, or non-player characters (NPCs) in a game world, where each entity learns its own strategy based solely on its personal experiences (its own actions, observations, and rewards).
* **Relationships:** The primary relationship is between each individual agent and the environment. The lack of inter-agent connections is the defining feature, distinguishing this from cooperative or communication-based MARL frameworks.
* **Potential Challenges (Implied):** While not stated in the diagram, this setup is known to face challenges like **non-stationarity**. From the perspective of any single agent, the environment appears to change unpredictably because the other agents are also learning and altering their behavior simultaneously. This can make stable learning difficult. The diagram's clean, parallel structure elegantly captures the independent learning paradigm while implicitly highlighting the complexity that arises from their shared impact on the environment.