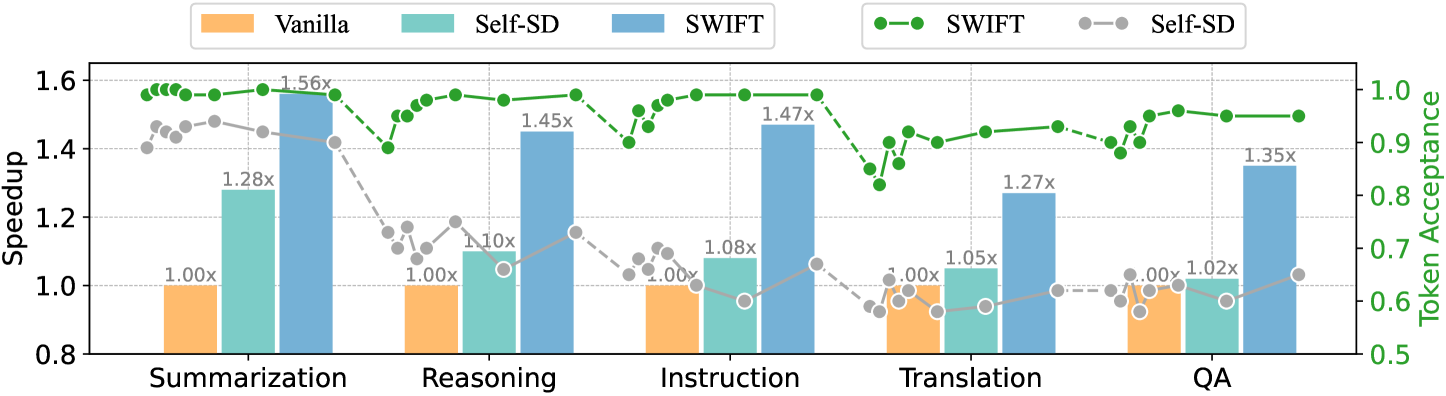
## Chart: Speedup and Token Acceptance Comparison
### Overview
The image is a combination bar and line chart comparing the performance of three systems (Vanilla, Self-SD, and SWIFT) across five tasks (Summarization, Reasoning, Instruction, Translation, and QA). The primary y-axis on the left represents "Speedup," measured by bars for each system and task. The secondary y-axis on the right represents "Token Acceptance," measured by lines for Self-SD and SWIFT.
### Components/Axes
* **X-axis:** Categorical axis representing the tasks: Summarization, Reasoning, Instruction, Translation, QA.
* **Left Y-axis:** "Speedup" ranging from 0.8 to 1.6 in increments of 0.2.
* **Right Y-axis:** "Token Acceptance" ranging from 0.5 to 1.0 in increments of 0.1.
* **Legend (Top):**
* Vanilla (Orange bar)
* Self-SD (Light Blue bar)
* SWIFT (Blue bar)
* SWIFT (Green line with circles)
* Self-SD (Gray dashed line with circles)
### Detailed Analysis
**Bar Chart (Speedup):**
* **Summarization:**
* Vanilla: 1.00x
* Self-SD: 1.28x
* SWIFT: 1.56x
* **Reasoning:**
* Vanilla: 1.00x
* Self-SD: 1.10x
* SWIFT: 1.45x
* **Instruction:**
* Vanilla: 1.00x
* Self-SD: 1.08x
* SWIFT: 1.47x
* **Translation:**
* Vanilla: 1.00x
* Self-SD: 1.05x
* SWIFT: 1.27x
* **QA:**
* Vanilla: 1.00x
* Self-SD: 1.02x
* SWIFT: 1.35x
**Line Chart (Token Acceptance):**
* **SWIFT (Green):** The line starts at approximately 0.98 for Summarization, remains relatively high, fluctuating between 0.9 and 1.0 across all tasks, ending at approximately 0.95 for QA.
* **Self-SD (Gray):** The line starts at approximately 0.93 for Summarization, decreases significantly for Reasoning (to approximately 0.7), fluctuates between 0.6 and 0.7 for Instruction and Translation, and ends at approximately 0.65 for QA.
### Key Observations
* SWIFT consistently outperforms Vanilla and Self-SD in terms of speedup across all tasks.
* Self-SD shows a modest speedup compared to Vanilla, but is significantly lower than SWIFT.
* Token acceptance for SWIFT is consistently higher than Self-SD across all tasks.
* Token acceptance for Self-SD drops significantly for Reasoning.
### Interpretation
The chart demonstrates that SWIFT provides a significant speedup compared to Vanilla and Self-SD across various natural language processing tasks. Additionally, SWIFT maintains a higher token acceptance rate than Self-SD, suggesting better overall performance and quality. The drop in token acceptance for Self-SD during the Reasoning task indicates a potential weakness in handling reasoning-related prompts. The consistent 1.00x speedup for Vanilla across all tasks suggests it serves as a baseline for comparison.