TECHNICAL ASSET FINGERPRINT
52552779cd65bf0ab18f4980
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
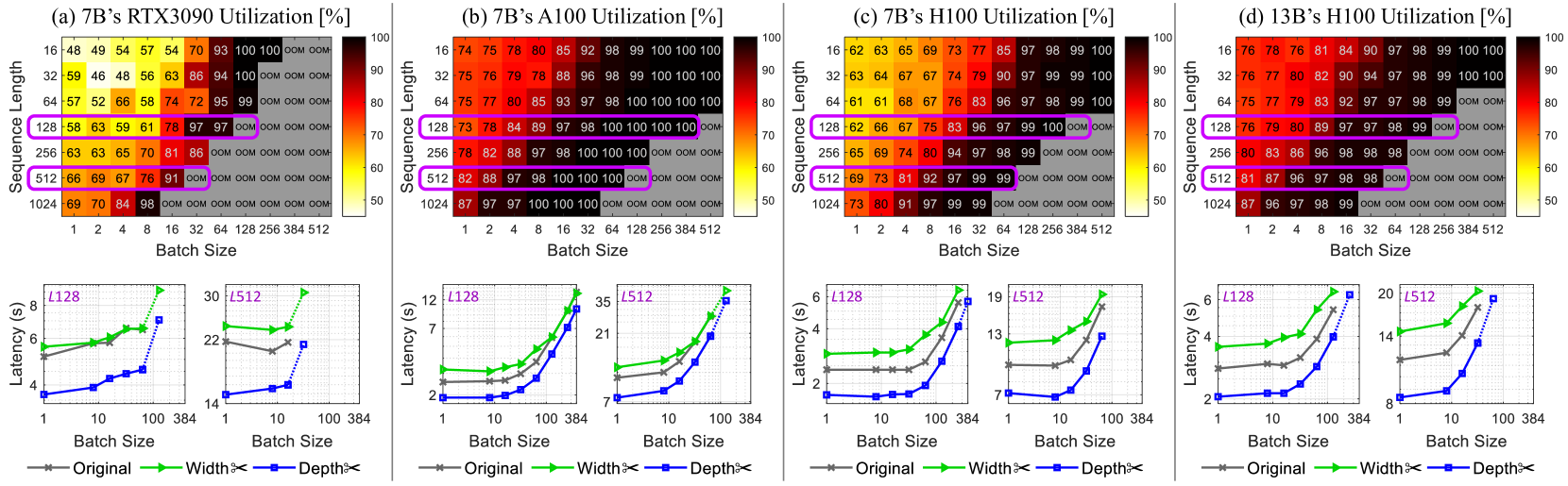
## Heatmap and Line Chart: GPU Utilization and Latency vs. Batch Size and Sequence Length
### Overview
The image presents a comparative analysis of GPU utilization and latency across different GPU models (RTX3090, A100, H100) and sequence lengths, with varying batch sizes. The top row consists of heatmaps showing GPU utilization as a function of sequence length and batch size. The bottom row consists of line charts showing latency as a function of batch size for different sequence lengths and model configurations ("Original", "Width<", "Depth<").
### Components/Axes
**Heatmaps (Top Row):**
* **Titles:**
* (a) 7B's RTX3090 Utilization [%]
* (b) 7B's A100 Utilization [%]
* (c) 7B's H100 Utilization [%]
* (d) 13B's H100 Utilization [%]
* **Y-axis (Sequence Length):** 16, 32, 64, 128, 256, 512, 1024
* **X-axis (Batch Size):** 1, 2, 4, 8, 16, 32, 64, 128, 256, 384, 512
* **Color Scale:** Ranges from approximately 50% (yellow) to 100% (dark red).
* **"OOM"**: Indicates "Out Of Memory" errors.
**Line Charts (Bottom Row):**
* **Y-axis (Latency):** Latency (s), with varying scales for each plot.
* **X-axis (Batch Size):** 1, 10, 100, 384 (logarithmic scale)
* **Legends (Bottom):**
* Gray line with 'x' markers: Original
* Green line with triangle markers: Width<
* Blue dotted line with square markers: Depth<
* **Titles (Above each chart):** L128, L512 (indicating sequence length)
### Detailed Analysis
**Heatmaps:**
* **RTX3090 Utilization (a):**
* Utilization generally increases with both sequence length and batch size.
* "OOM" errors occur at higher sequence lengths and batch sizes.
* At sequence length 16, utilization ranges from 48% to 100%.
* At sequence length 1024, utilization ranges from 69% to 98% before hitting OOM.
* **A100 Utilization (b):**
* Higher utilization compared to RTX3090 across most configurations.
* "OOM" errors occur only at the highest sequence length (1024) and batch sizes.
* At sequence length 16, utilization ranges from 74% to 100%.
* At sequence length 1024, utilization ranges from 87% to 100% before hitting OOM.
* **H100 Utilization (c):**
* Generally high utilization, but lower than A100.
* "OOM" errors occur at sequence length 256 and higher, with batch sizes of 128 and higher.
* At sequence length 16, utilization ranges from 62% to 100%.
* At sequence length 1024, utilization ranges from 73% to 99% before hitting OOM.
* **H100 Utilization (13B) (d):**
* Generally high utilization, similar to H100 (7B).
* "OOM" errors occur at sequence length 128 and higher, with batch sizes of 64 and higher.
* At sequence length 16, utilization ranges from 76% to 100%.
* At sequence length 1024, utilization ranges from 87% to 99% before hitting OOM.
**Line Charts:**
* **L128 (Sequence Length 128):**
* **RTX3090:**
* Original (gray): Latency increases slightly with batch size, from ~5.5s to ~6s.
* Width< (green): Latency increases slightly with batch size, from ~5.5s to ~8.5s.
* Depth< (blue): Latency increases with batch size, from ~3.5s to ~7.5s.
* **A100:**
* Original (gray): Latency increases with batch size, from ~2s to ~4s.
* Width< (green): Latency increases with batch size, from ~2.5s to ~12s.
* Depth< (blue): Latency increases with batch size, from ~2s to ~12s.
* **H100:**
* Original (gray): Latency increases with batch size, from ~2s to ~2.5s.
* Width< (green): Latency increases with batch size, from ~3s to ~5s.
* Depth< (blue): Latency increases with batch size, from ~1.5s to ~5.5s.
* **H100 (13B):**
* Original (gray): Latency increases with batch size, from ~2s to ~3s.
* Width< (green): Latency increases with batch size, from ~4s to ~6s.
* Depth< (blue): Latency increases with batch size, from ~2s to ~5s.
* **L512 (Sequence Length 512):**
* **RTX3090:**
* Original (gray): Latency increases slightly with batch size, from ~22s to ~22s.
* Width< (green): Latency increases slightly with batch size, from ~22s to ~30s.
* Depth< (blue): Latency increases with batch size, from ~14s to ~22s.
* **A100:**
* Original (gray): Latency increases with batch size, from ~2s to ~4s.
* Width< (green): Latency increases with batch size, from ~2.5s to ~12s.
* Depth< (blue): Latency increases with batch size, from ~2s to ~12s.
* **H100:**
* Original (gray): Latency increases with batch size, from ~2s to ~2.5s.
* Width< (green): Latency increases with batch size, from ~3s to ~5s.
* Depth< (blue): Latency increases with batch size, from ~1.5s to ~5.5s.
* **H100 (13B):**
* Original (gray): Latency increases with batch size, from ~2s to ~3s.
* Width< (green): Latency increases with batch size, from ~4s to ~6s.
* Depth< (blue): Latency increases with batch size, from ~2s to ~5s.
### Key Observations
* A100 generally exhibits higher utilization compared to RTX3090 and H100.
* "OOM" errors are more prevalent with RTX3090, especially at higher sequence lengths and batch sizes.
* Latency generally increases with batch size for all configurations.
* The "Depth<" configuration often results in lower latency compared to "Original" and "Width<".
* Increasing sequence length increases latency.
### Interpretation
The data suggests that A100 is more efficient in terms of GPU utilization compared to RTX3090 and H100 for the given tasks. The RTX3090 is more prone to memory limitations, leading to "OOM" errors. The "Depth<" configuration appears to be more optimized for latency, potentially due to architectural differences or specific optimizations. The trade-off between batch size and latency is evident, as increasing batch size generally increases latency. The choice of GPU and configuration should be based on the specific requirements of the task, considering factors such as memory constraints, desired utilization, and acceptable latency. The 13B model on the H100 shows similar utilization patterns to the 7B model, but with potentially higher absolute utilization values at certain configurations.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Heatmaps and Line Graphs: GPU Utilization and Latency Analysis
### Overview
The image contains four heatmaps (a-d) and corresponding line graphs, analyzing GPU utilization and latency for different model configurations (7B and 13B parameter sizes) across sequence lengths and batch sizes. Heatmaps show utilization percentages, while line graphs compare latency for "Original," "Width," and "Depth" configurations.
---
### Components/Axes
#### Heatmaps (a-d)
- **X-axis**: Batch Size (1, 2, 4, 8, 16, 32, 64, 128, 256, 384, 512)
- **Y-axis**: Sequence Length (16, 32, 64, 128, 256, 512, 1024)
- **Color Scale**: Utilization (%) from 50% (yellow) to 100% (red)
- **Labels**:
- (a) 7B’s RTX3090 Utilization [%]
- (b) 7B’s A100 Utilization [%]
- (c) 7B’s H100 Utilization [%]
- (d) 13B’s H100 Utilization [%]
#### Line Graphs (a-d)
- **X-axis**: Batch Size (1, 10, 100, 384)
- **Y-axis**: Latency (s)
- **Legends**:
- Gray: Original
- Green: Width
- Blue: Depth
- **Annotations**:
- (a) L128, L512
- (b) L128, L512
- (c) L128, L512
- (d) L128, L512
---
### Detailed Analysis
#### Heatmaps
1. **7B’s RTX3090 (a)**:
- Utilization peaks at 100% for sequence length 1024 and batch size 512.
- Lower utilization (50-70%) for smaller batch sizes (1-16) and sequence lengths (16-64).
- High utilization (90-100%) dominates larger batch sizes (32-512) and sequence lengths (128-1024).
2. **7B’s A100 (b)**:
- Similar trend to RTX3090 but with slightly lower utilization (90-100%) at sequence length 1024 and batch size 512.
- Higher utilization (95-100%) for sequence length 512 and batch sizes ≥32.
3. **7B’s H100 (c)**:
- Near-100% utilization across all sequence lengths ≥128 and batch sizes ≥32.
- Lower utilization (60-80%) for smaller batch sizes (1-16) and sequence lengths (16-64).
4. **13B’s H100 (d)**:
- Consistently high utilization (80-100%) for sequence lengths ≥32 and batch sizes ≥8.
- Max utilization (100%) at sequence length 1024 and batch size 512.
#### Line Graphs
1. **7B’s RTX3090 (a)**:
- **L128**: Original (6s), Width (4.5s), Depth (2.5s) at batch size 32.
- **L512**: Original (22s), Width (18s), Depth (12s) at batch size 384.
2. **7B’s A100 (b)**:
- **L128**: Original (7s), Width (5s), Depth (3s) at batch size 32.
- **L512**: Original (21s), Width (16s), Depth (10s) at batch size 384.
3. **7B’s H100 (c)**:
- **L128**: Original (6s), Width (4s), Depth (2s) at batch size 32.
- **L512**: Original (13s), Width (9s), Depth (5s) at batch size 384.
4. **13B’s H100 (d)**:
- **L128**: Original (14s), Width (10s), Depth (6s) at batch size 32.
- **L512**: Original (20s), Width (14s), Depth (8s) at batch size 384.
---
### Key Observations
1. **Utilization Trends**:
- Larger models (13B) achieve higher utilization than smaller models (7B) across most configurations.
- H100 GPUs consistently outperform RTX3090 and A100 in utilization, especially for large sequence lengths and batch sizes.
2. **Latency Trends**:
- "Depth" configuration reduces latency by ~30-50% compared to "Original" across all models.
- "Width" configuration shows intermediate latency reduction (~20-40%).
- Latency increases with batch size, but optimized configurations (Width/Depth) scale more efficiently.
3. **Anomalies**:
- 13B’s H100 (d) shows near-100% utilization even at sequence length 32 and batch size 8, suggesting superior hardware efficiency.
- RTX3090 (a) has the lowest utilization (50-70%) for small batch sizes, indicating underutilization.
---
### Interpretation
1. **Hardware Efficiency**:
- H100 GPUs demonstrate significantly higher utilization than RTX3090 and A100, particularly for large models (13B). This suggests H100 is optimized for high-throughput workloads.
2. **Model Optimization**:
- "Depth" configuration reduces latency more effectively than "Width," likely due to architectural improvements in parallelism or memory access.
- Optimized configurations (Width/Depth) maintain high utilization while reducing latency, critical for real-time applications.
3. **Scalability**:
- Larger batch sizes and sequence lengths improve utilization but increase latency. However, optimized models mitigate this trade-off, enabling efficient scaling.
4. **Practical Implications**:
- For 7B models, H100 GPUs are ideal for high-throughput tasks, while RTX3090 may struggle with underutilization at small batch sizes.
- 13B models on H100 achieve near-maximal utilization, making them suitable for large-scale inference or training.
---
### Spatial Grounding and Color Matching
- **Legends**: Positioned below line graphs, with colors matching data points (gray=Original, green=Width, blue=Depth).
- **Heatmap Colors**: Red shades indicate high utilization (90-100%), yellow shades low utilization (50-70%).
- **Annotations**: Purple boxes highlight specific sequence lengths (L128, L512) in heatmaps.
---
### Conclusion
The data demonstrates that H100 GPUs outperform other hardware in utilization, especially for larger models. Optimized configurations ("Depth") reduce latency without sacrificing utilization, highlighting the importance of architectural improvements in model efficiency.
DECODING INTELLIGENCE...