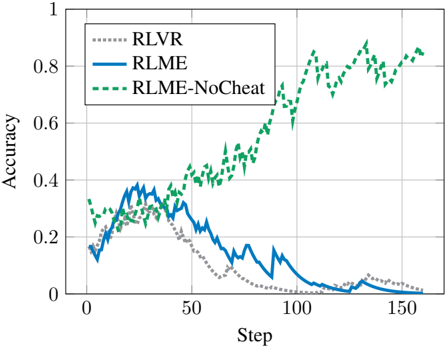
## Line Chart: Accuracy vs. Step for Different Models
### Overview
The image is a line chart comparing the accuracy of three different models (RLVR, RLME, and RLME-NoCheat) over a series of steps. The x-axis represents the step number, and the y-axis represents the accuracy, ranging from 0 to 1. The chart displays the performance of each model as a line, allowing for a visual comparison of their learning curves.
### Components/Axes
* **X-axis:** "Step", ranging from 0 to 150 in increments of 50.
* **Y-axis:** "Accuracy", ranging from 0 to 1 in increments of 0.2.
* **Legend:** Located in the top-left corner of the chart.
* **RLVR:** Represented by a gray dotted line.
* **RLME:** Represented by a solid blue line.
* **RLME-NoCheat:** Represented by a dashed green line.
### Detailed Analysis
* **RLVR (Gray Dotted Line):**
* Starts at approximately 0.12 accuracy at step 0.
* Increases to approximately 0.32 accuracy around step 30.
* Gradually decreases to approximately 0.02 accuracy by step 150.
* Trend: Initially increases, then steadily declines.
* **RLME (Solid Blue Line):**
* Starts at approximately 0.13 accuracy at step 0.
* Increases to approximately 0.40 accuracy around step 30.
* Decreases to approximately 0.03 accuracy by step 150.
* Trend: Initially increases, then steadily declines.
* **RLME-NoCheat (Dashed Green Line):**
* Starts at approximately 0.30 accuracy at step 0.
* Increases to approximately 0.45 accuracy around step 30.
* Experiences a sharp increase in accuracy around step 80.
* Fluctuates between approximately 0.70 and 0.90 accuracy from step 100 to step 160.
* Trend: Initially increases, then shows a significant and sustained increase.
### Key Observations
* RLME-NoCheat consistently outperforms RLVR and RLME after approximately step 80.
* RLVR and RLME show a similar trend of initial increase followed by a decline in accuracy.
* RLME-NoCheat exhibits a significant jump in accuracy around step 80, suggesting a change in learning dynamics.
### Interpretation
The chart illustrates the learning performance of three different models. RLME-NoCheat demonstrates a clear advantage, achieving significantly higher accuracy compared to RLVR and RLME, especially after a certain number of steps. The decline in accuracy for RLVR and RLME suggests that these models may be overfitting or failing to generalize effectively as the number of steps increases. The "NoCheat" aspect of RLME-NoCheat likely contributes to its superior performance, possibly by preventing the model from exploiting unintended shortcuts or biases in the training data. The jump in accuracy around step 80 for RLME-NoCheat could indicate a critical point in its learning process, where it begins to leverage learned features more effectively.