# Technical Document Extraction: Memory Cost Comparison for Optimization Methods
## 1. Image Overview
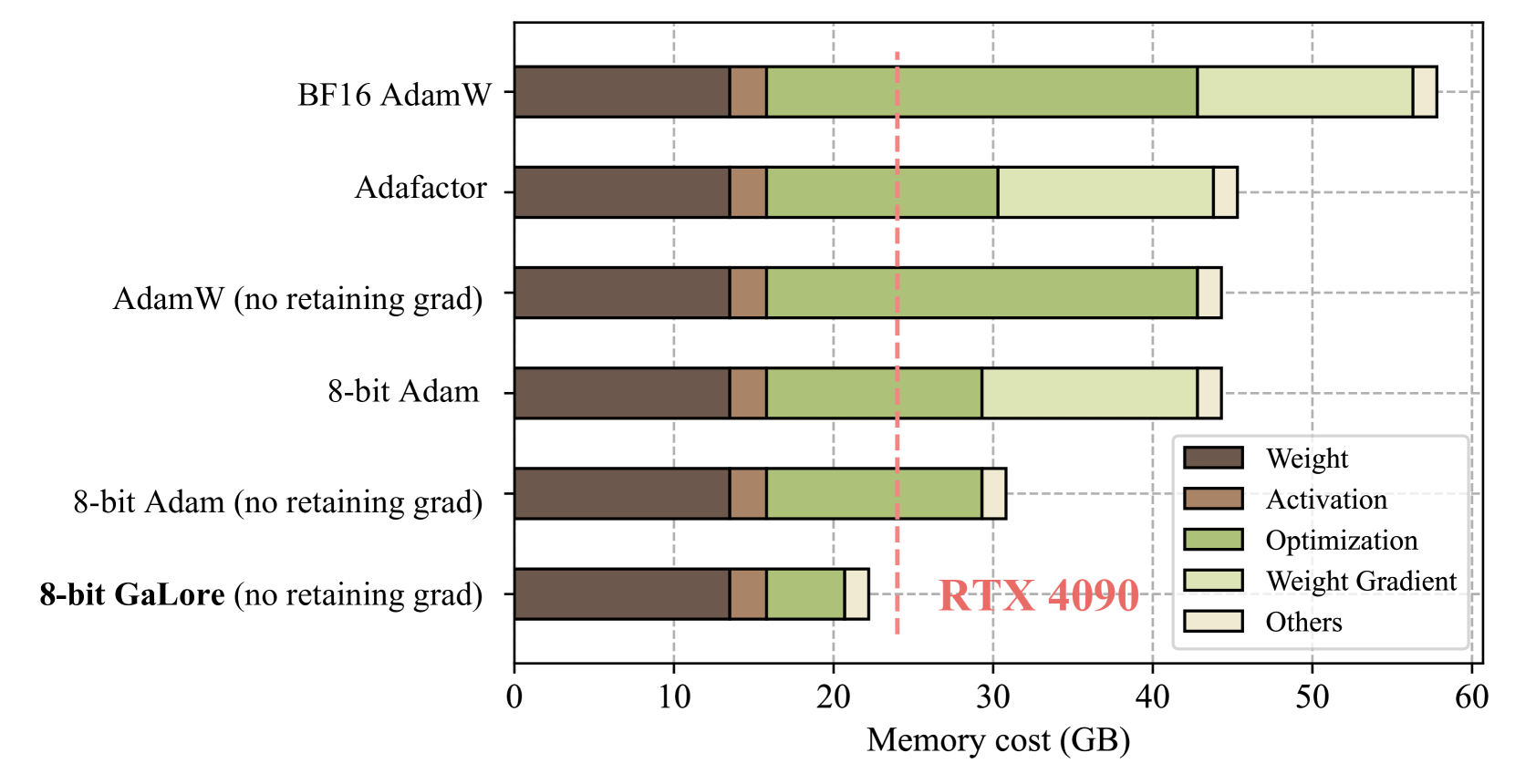
This image is a horizontal stacked bar chart comparing the memory consumption (in Gigabytes) of six different deep learning optimization configurations. The chart highlights the memory efficiency of "8-bit GaLore" relative to standard optimizers and a specific hardware threshold (NVIDIA RTX 4090).
## 2. Component Isolation
### A. Header / Y-Axis (Optimization Methods)
The Y-axis lists six categories of optimization methods, ordered from highest memory consumption at the top to lowest at the bottom:
1. **BF16 AdamW**
2. **Adafactor**
3. **AdamW (no retaining grad)**
4. **8-bit Adam**
5. **8-bit Adam (no retaining grad)**
6. **8-bit GaLore (no retaining grad)** (Highlighted in bold)
### B. Main Chart Area (Data Visualization)
* **X-Axis:** Labeled "Memory cost (GB)". It ranges from 0 to 60, with major tick marks and dashed vertical grid lines every 10 units (0, 10, 20, 30, 40, 50, 60).
* **Stacked Bars:** Each bar represents the total memory cost, segmented by the type of memory allocation.
* **Threshold Line:** A vertical dashed red line is positioned at approximately **24 GB**.
* **Annotation:** To the right of the 20 GB mark, near the bottom bar, is a red text label: **"RTX 4090"**. This indicates the 24 GB VRAM limit of that specific GPU.
### C. Legend
The legend defines five color-coded categories for the stacked bars:
* **Dark Brown:** Weight
* **Medium Brown:** Activation
* **Olive Green:** Optimization
* **Pale Yellow:** Weight Gradient
* **Cream/Off-White:** Others
## 3. Data Extraction and Table Reconstruction
The following table estimates the numerical values (in GB) based on the X-axis alignment. Note that "Weight" and "Activation" remain constant across all methods.
| Optimization Method | Weight | Activation | Optimization | Weight Gradient | Others | Total (Approx) |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: |
| **BF16 AdamW** | 13.5 | 2.5 | 27.0 | 13.5 | 1.5 | **58.0** |
| **Adafactor** | 13.5 | 2.5 | 14.5 | 13.0 | 2.0 | **45.5** |
| **AdamW (no retaining grad)** | 13.5 | 2.5 | 27.0 | 0.0 | 1.5 | **44.5** |
| **8-bit Adam** | 13.5 | 2.5 | 13.5 | 13.5 | 1.5 | **44.5** |
| **8-bit Adam (no retaining grad)** | 13.5 | 2.5 | 13.5 | 0.0 | 1.5 | **31.0** |
| **8-bit GaLore (no retaining grad)** | 13.5 | 2.5 | 5.0 | 0.0 | 1.5 | **22.5** |
## 4. Trend Verification and Analysis
### Component Trends
* **Weight (Dark Brown):** Constant across all methods (~13.5 GB). This represents the base model size.
* **Activation (Medium Brown):** Constant across all methods (~2.5 GB).
* **Optimization (Olive Green):** This is the primary variable. It is largest in BF16 AdamW and AdamW (~27 GB), reduced in 8-bit Adam (~13.5 GB), and significantly minimized in **8-bit GaLore (~5 GB)**.
* **Weight Gradient (Pale Yellow):** Present in standard methods (~13-13.5 GB) but completely removed in all "(no retaining grad)" configurations.
* **Others (Cream):** A small, consistent overhead of ~1.5–2 GB.
### Key Findings
1. **Hardware Compatibility:** The red dashed line represents the 24 GB limit of an **RTX 4090**. Only the **8-bit GaLore (no retaining grad)** method falls below this line (at ~22.5 GB), making it the only configuration shown capable of running on a single consumer-grade RTX 4090 GPU.
2. **Efficiency of GaLore:** By comparing "8-bit Adam (no retaining grad)" to "8-bit GaLore (no retaining grad)", it is evident that GaLore specifically reduces the "Optimization" memory footprint by more than 60% (from ~13.5 GB to ~5 GB).
3. **Gradient Impact:** Removing the "retaining grad" requirement (Weight Gradient) provides a massive memory saving of roughly 13.5 GB across all applicable methods.