\n
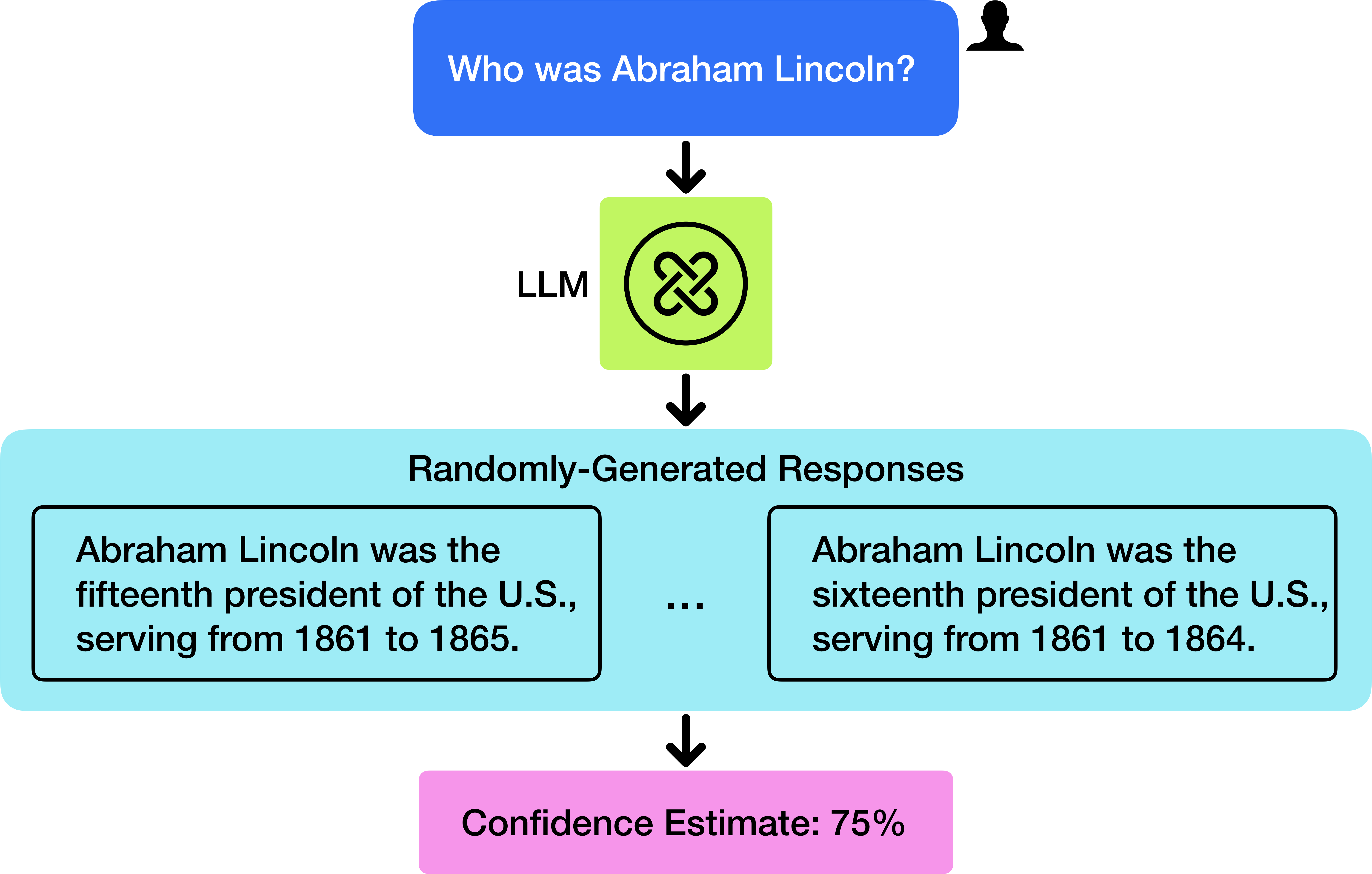
## Diagram: LLM Response Generation Flow
### Overview
This diagram illustrates the process of a Large Language Model (LLM) responding to a user query. It depicts the input query, the LLM processing stage, the generation of multiple responses, and a confidence estimate for the responses.
### Components/Axes
The diagram consists of the following components, arranged vertically:
1. **Input Query:** A light blue rounded rectangle at the top, labeled "Who was Abraham Lincoln?". A small grey icon of a person is positioned in the top-right corner.
2. **LLM Processing:** A green circular shape containing a stylized intertwined symbol, labeled "LLM".
3. **Responses:** A light blue rounded rectangle labeled "Randomly-Generated Responses". This contains two example responses, separated by ellipses ("..."), suggesting more responses exist.
4. **Confidence Estimate:** A pink rounded rectangle at the bottom, labeled "Confidence Estimate: 75%".
5. **Arrows:** Black downward-pointing arrows indicate the flow of information between the components.
### Detailed Analysis or Content Details
The diagram shows a sequential flow:
1. **Input:** The query "Who was Abraham Lincoln?" is presented as input.
2. **Processing:** The query is processed by the LLM.
3. **Output:** The LLM generates multiple responses. Two examples are provided:
* "Abraham Lincoln was the fifteenth president of the U.S., serving from 1861 to 1865."
* "Abraham Lincoln was the sixteenth president of the U.S., serving from 1861 to 1864."
4. **Confidence:** A confidence estimate of 75% is assigned to the generated responses.
### Key Observations
The diagram highlights a potential issue with LLMs: the generation of conflicting or inaccurate responses. The two provided responses disagree on Lincoln's presidential number (fifteenth vs. sixteenth) and the end year of his presidency (1865 vs. 1864). The confidence estimate of 75% suggests the LLM is not entirely certain about its responses, despite presenting them as factual.
### Interpretation
This diagram demonstrates the probabilistic nature of LLM responses. LLMs do not "know" facts in the same way humans do; they generate text based on patterns learned from training data. This can lead to inconsistencies and inaccuracies, even with a relatively high confidence estimate. The diagram suggests that LLM outputs should be critically evaluated and not accepted as definitive truth. The inclusion of a confidence estimate is a useful feature, but it does not guarantee the accuracy of the information. The "Randomly-Generated Responses" label implies that the LLM produces multiple possible answers, and the selection of the final response may be based on factors other than factual correctness. The diagram is a visual representation of the challenges associated with relying on LLMs for factual information.