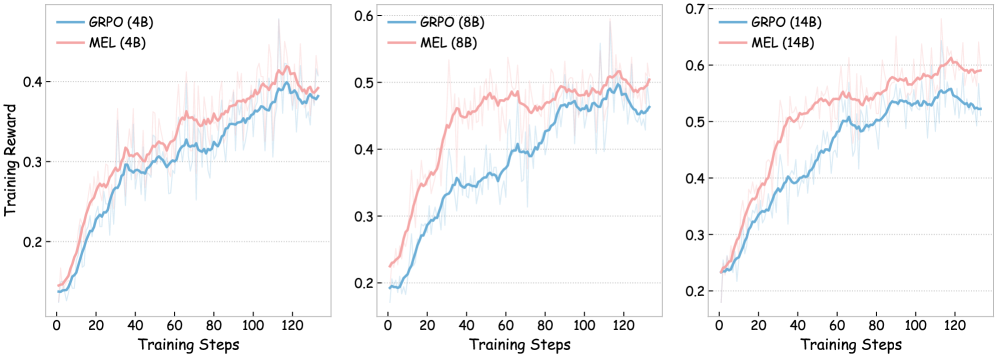
## Line Graphs: Training Reward vs. Training Steps for GRPO and MEL Models
### Overview
The image contains three line graphs comparing the training reward performance of two models, **GRPO** and **MEL**, across three parameter sizes: **4B**, **8B**, and **14B**. Each graph tracks training reward over 120 training steps, with distinct trends observed for each model size.
---
### Components/Axes
- **X-axis**: Training Steps (0 to 120, linear scale).
- **Y-axis**: Training Reward (0.2 to 0.7, linear scale).
- **Legends**:
- **GRPO**: Blue line with shaded blue region (top-right placement).
- **MEL**: Red line with shaded red region (top-right placement).
- **Graph Titles**:
- Left: "GRPO (4B)" and "MEL (4B)"
- Middle: "GRPO (8B)" and "MEL (8B)"
- Right: "GRPO (14B)" and "MEL (14B)"
---
### Detailed Analysis
#### 4B Model Size
- **GRPO (Blue)**: Starts at ~0.15, rises steadily to ~0.38 by step 120. Shows moderate variance (shaded region).
- **MEL (Red)**: Begins slightly higher (~0.18) but converges with GRPO by step 60, ending at ~0.39. Variance is higher than GRPO.
#### 8B Model Size
- **GRPO (Blue)**: Starts at ~0.18, increases to ~0.45 by step 120. Variance decreases after step 60.
- **MEL (Red)**: Begins at ~0.22, peaks at ~0.48 around step 60, then declines slightly to ~0.46. Variance is higher than GRPO.
#### 14B Model Size
- **GRPO (Blue)**: Starts at ~0.22, rises to ~0.55 by step 120. Variance is low after step 80.
- **MEL (Red)**: Begins at ~0.25, peaks at ~0.60 around step 100, then stabilizes at ~0.58. Variance is higher than GRPO.
---
### Key Observations
1. **Model Size Impact**:
- Larger models (14B) achieve higher training rewards than smaller models (4B/8B).
- GRPO consistently outperforms MEL in larger models (14B), while MEL has a slight edge in smaller models (4B).
2. **Training Dynamics**:
- GRPO shows steeper improvement in larger models, suggesting better scalability.
- MEL exhibits higher variance across all model sizes, indicating less stable training.
3. **Convergence Points**:
- In 4B and 8B, GRPO and MEL converge early (steps 40–60).
- In 14B, GRPO overtakes MEL around step 80, maintaining a lead thereafter.
4. **Shaded Regions**:
- Represent uncertainty or confidence intervals. MEL’s wider shaded regions suggest greater variability in training outcomes.
---
### Interpretation
The data demonstrates that **GRPO outperforms MEL in larger models (14B)**, with a clear advantage emerging after ~80 training steps. This suggests GRPO’s architecture or training strategy scales more effectively with model size. Conversely, MEL performs better in smaller models (4B) but struggles with stability as model size increases. The variance patterns imply that MEL’s training is less robust, potentially due to optimization challenges in larger parameter spaces. These trends highlight the importance of model architecture design for scalability and training efficiency in machine learning systems.