## Bar Chart: Accuracy Comparison on MMLU
### Overview
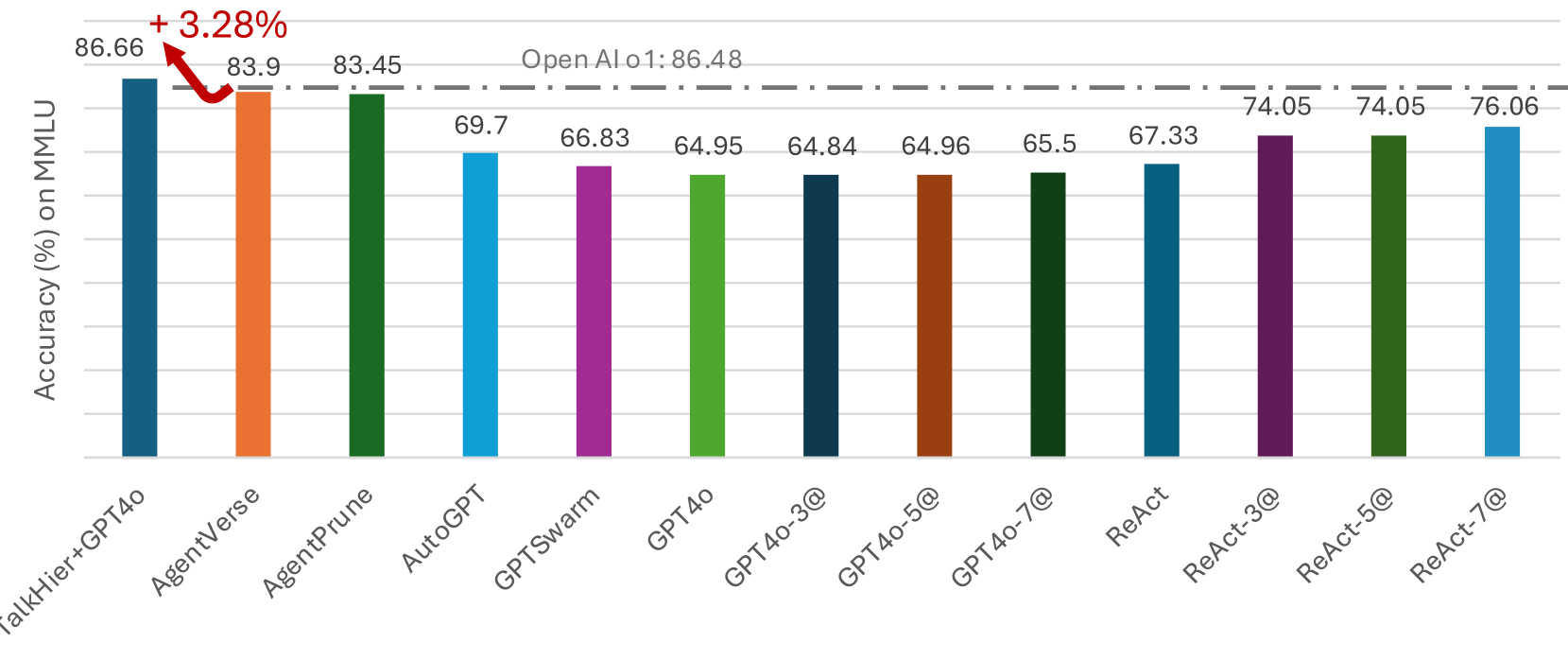
This bar chart compares the accuracy of several language model configurations on the MMLU (Massive Multitask Language Understanding) benchmark. The chart displays accuracy percentages for models including TalkHier+GPT4o, AgentVerse, AgentPrune, AutoGPT, GPTSwarm, GPT4o, GPT4o with varying numbers of queries (@), and ReAct with varying numbers of queries (@). A dashed horizontal line indicates the accuracy of OpenAI's GPT-4 (86.48%).
### Components/Axes
* **X-axis:** Model Configuration (TalkHier+GPT4o, AgentVerse, AgentPrune, AutoGPT, GPTSwarm, GPT4o, GPT4o-3@, GPT4o-5@, GPT4o-7@, ReAct, ReAct-3@, ReAct-5@, ReAct-7@)
* **Y-axis:** Accuracy (%) on MMLU. Scale ranges from approximately 64% to 87%.
* **Horizontal Dashed Line:** Represents OpenAI's GPT-4 accuracy at 86.48%.
* **Annotation:** A red arrow points from the TalkHier+GPT4o bar to the OpenAI GPT-4 line, indicating a +3.28% improvement.
### Detailed Analysis
The bars represent the accuracy of each model configuration. Let's analyze each one:
1. **TalkHier+GPT4o:** Accuracy is 86.66%. This is the highest accuracy shown in the chart.
2. **AgentVerse:** Accuracy is 83.9%.
3. **AgentPrune:** Accuracy is 83.45%.
4. **AutoGPT:** Accuracy is 69.7%.
5. **GPTSwarm:** Accuracy is 66.83%.
6. **GPT4o:** Accuracy is 64.95%.
7. **GPT4o-3@:** Accuracy is 64.84%.
8. **GPT4o-5@:** Accuracy is 64.96%.
9. **GPT4o-7@:** Accuracy is 65.5%.
10. **ReAct:** Accuracy is 67.33%.
11. **ReAct-3@:** Accuracy is 74.05%.
12. **ReAct-5@:** Accuracy is 74.05%.
13. **ReAct-7@:** Accuracy is 76.06%.
The GPT4o configurations with increasing numbers of queries (@) show a slight upward trend in accuracy, but the differences are small. The ReAct configurations also show an upward trend with increasing queries, with ReAct-7@ achieving the highest accuracy among the ReAct models.
### Key Observations
* TalkHier+GPT4o significantly outperforms all other configurations, exceeding OpenAI's GPT-4 accuracy by 3.28%.
* AgentVerse and AgentPrune perform similarly, both exceeding GPT-4's accuracy.
* AutoGPT, GPTSwarm, and GPT4o have considerably lower accuracy scores compared to the top performers.
* Increasing the number of queries (@) for GPT4o and ReAct models generally leads to a slight improvement in accuracy, but the gains diminish.
* ReAct-7@ achieves the highest accuracy among the ReAct models, approaching the performance of AgentVerse and AgentPrune.
### Interpretation
The data suggests that the TalkHier+GPT4o configuration is a highly effective approach for the MMLU benchmark, surpassing even OpenAI's GPT-4. The improvement could be attributed to the specific architecture or training methodology of TalkHier. The performance of AgentVerse and AgentPrune indicates that agent-based approaches can also yield strong results. The lower accuracy of AutoGPT, GPTSwarm, and GPT4o suggests that these models may require further optimization or different prompting strategies to achieve comparable performance. The slight improvements observed with increasing queries for GPT4o and ReAct models suggest that iterative refinement can be beneficial, but there may be a point of diminishing returns. The chart highlights the importance of model configuration and architecture in achieving high accuracy on complex language understanding tasks. The consistent upward trend in ReAct performance with more queries suggests that the model benefits from more opportunities to reason and refine its responses.