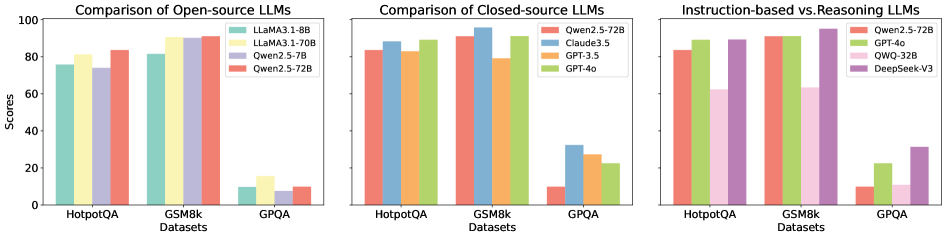
## Bar Chart: Comparison of LLMs
### Overview
The image presents three bar charts comparing the performance of different Large Language Models (LLMs) on three datasets: HotpotQA, GSM8k, and GPQA. The charts are grouped by LLM type: Open-source, Closed-source, and Instruction-based vs. Reasoning. The y-axis represents scores, ranging from 0 to 100.
### Components/Axes
**Chart 1: Comparison of Open-source LLMs**
* **Title:** Comparison of Open-source LLMs
* **Y-axis:** Scores (0 to 100, incrementing by 20)
* **X-axis:** Datasets (HotpotQA, GSM8k, GPQA)
* **Legend (Top-Right):**
* Llama3.1-8B (Teal)
* Llama3.1-70B (Yellow)
* Qwen2.5-7B (Light Purple)
* Qwen2.5-72B (Salmon)
**Chart 2: Comparison of Closed-source LLMs**
* **Title:** Comparison of Closed-source LLMs
* **Y-axis:** Scores (0 to 100, incrementing by 20)
* **X-axis:** Datasets (HotpotQA, GSM8k, GPQA)
* **Legend (Top-Right):**
* Qwen2.5-72B (Salmon)
* Claude3.5 (Light Blue)
* GPT-3.5 (Orange)
* GPT-4o (Light Green)
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **Title:** Instruction-based vs. Reasoning LLMs
* **Y-axis:** Scores (0 to 100, incrementing by 20)
* **X-axis:** Datasets (HotpotQA, GSM8k, GPQA)
* **Legend (Top-Right):**
* Qwen2.5-72B (Salmon)
* GPT-4o (Light Green)
* QWQ-32B (Pink)
* DeepSeek-V3 (Purple)
### Detailed Analysis
**Chart 1: Open-source LLMs**
* **Llama3.1-8B (Teal):**
* HotpotQA: ~76
* GSM8k: ~82
* GPQA: ~10
* **Llama3.1-70B (Yellow):**
* HotpotQA: ~82
* GSM8k: ~91
* GPQA: ~15
* **Qwen2.5-7B (Light Purple):**
* HotpotQA: ~74
* GSM8k: ~89
* GPQA: ~8
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~84
* GSM8k: ~91
* GPQA: ~10
**Chart 2: Closed-source LLMs**
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~84
* GSM8k: ~91
* GPQA: ~10
* **Claude3.5 (Light Blue):**
* HotpotQA: ~86
* GSM8k: ~93
* GPQA: ~32
* **GPT-3.5 (Orange):**
* HotpotQA: ~82
* GSM8k: ~79
* GPQA: ~25
* **GPT-4o (Light Green):**
* HotpotQA: ~89
* GSM8k: ~94
* GPQA: ~28
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~84
* GSM8k: ~91
* GPQA: ~10
* **GPT-4o (Light Green):**
* HotpotQA: ~89
* GSM8k: ~94
* GPQA: ~22
* **QWQ-32B (Pink):**
* HotpotQA: ~89
* GSM8k: ~93
* GPQA: ~12
* **DeepSeek-V3 (Purple):**
* HotpotQA: ~91
* GSM8k: ~95
* GPQA: ~32
### Key Observations
* All models perform significantly better on HotpotQA and GSM8k datasets compared to GPQA.
* Within Open-source LLMs, Llama3.1-70B and Qwen2.5-72B generally achieve higher scores than Llama3.1-8B and Qwen2.5-7B.
* Within Closed-source LLMs, GPT-4o and Claude3.5 generally outperform GPT-3.5 and Qwen2.5-72B.
* DeepSeek-V3 shows the highest performance on GSM8k.
* GPQA scores are consistently low across all models, indicating this dataset is more challenging.
### Interpretation
The charts provide a comparative analysis of different LLMs across various datasets. The data suggests that:
* **Model Size Matters:** Larger models (e.g., Llama3.1-70B vs. Llama3.1-8B) tend to perform better, especially on HotpotQA and GSM8k.
* **Closed-source Models Lead:** Closed-source models like GPT-4o and Claude3.5 generally outperform open-source models on these datasets.
* **GPQA is a Bottleneck:** The consistently low scores on GPQA indicate that this dataset poses a significant challenge for all models, regardless of their architecture or training. This could be due to the nature of the questions, the complexity of the reasoning required, or the format of the data.
* **Instruction-based vs. Reasoning Specialization:** The "Instruction-based vs. Reasoning LLMs" chart highlights models potentially optimized for different tasks. DeepSeek-V3 shows a strong performance, suggesting it may excel in reasoning-based tasks, while others might be more focused on instruction following.
The relationship between the elements is clear: the charts compare the performance of different LLMs on the same datasets, allowing for a direct comparison of their capabilities. The low GPQA scores are a notable outlier, suggesting a potential area for improvement in LLM design and training.