## Line Charts: Accuracy vs. Mean Response Length (Tokens)
### Overview
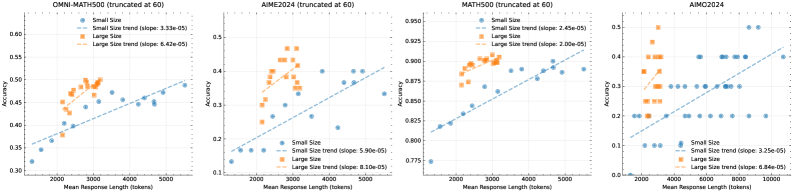
The image contains four line charts comparing the accuracy of "Small Size" and "Large Size" models across four datasets: OMNI-MATH500 (truncated at 60), AIME2024 (truncated at 60), MATH500 (truncated at 60), and AIMO2024. Each chart plots accuracy (y-axis) against mean response length in tokens (x-axis), with trend lines for both model sizes.
### Components/Axes
- **X-axis**: "Mean Response Length (tokens)" (ranges from ~2000 to 10,000 tokens across charts).
- **Y-axis**: "Accuracy" (ranges from 0.1 to 0.95 across charts).
- **Legends**:
- **Small Size**: Blue circles (dashed trend line).
- **Large Size**: Orange squares (dashed trend line).
- **Trend Lines**: Dashed lines for both model sizes, with slopes provided in legends.
### Detailed Analysis
#### OMNI-MATH500 (truncated at 60)
- **Small Size**:
- Slope: 3.33e-05.
- Data points: Accuracy increases from ~0.32 (2000 tokens) to ~0.48 (5000 tokens).
- **Large Size**:
- Slope: 6.42e-05.
- Data points: Accuracy peaks at ~0.50 (3000 tokens), then declines to ~0.45 (5000 tokens).
#### AIME2024 (truncated at 60)
- **Small Size**:
- Slope: 5.90e-05.
- Data points: Accuracy rises from ~0.15 (2000 tokens) to ~0.35 (5000 tokens).
- **Large Size**:
- Slope: 8.10e-05.
- Data points: Accuracy peaks at ~0.40 (3000 tokens), then drops to ~0.35 (5000 tokens).
#### MATH500 (truncated at 60)
- **Small Size**:
- Slope: 2.45e-05.
- Data points: Accuracy increases steadily from ~0.77 (2000 tokens) to ~0.90 (5000 tokens).
- **Large Size**:
- Slope: 2.00e-05.
- Data points: Accuracy starts at ~0.85 (2000 tokens), peaks at ~0.90 (3000 tokens), then declines to ~0.87 (5000 tokens).
#### AIMO2024
- **Small Size**:
- Slope: 3.25e-05.
- Data points: Accuracy fluctuates between ~0.20 (2000 tokens) and ~0.40 (8000 tokens).
- **Large Size**:
- Slope: 6.84e-05.
- Data points: Accuracy peaks at ~0.45 (4000 tokens), then drops to ~0.40 (8000 tokens).
### Key Observations
1. **MATH500** shows the highest accuracy for both model sizes, with Large Size outperforming Small Size consistently.
2. **AIME2024** and **AIMO2024** exhibit significant variability in Large Size accuracy, with peaks followed by declines.
3. **OMNI-MATH500** demonstrates a sharp drop in Large Size accuracy after 3000 tokens.
4. **Small Size models** generally show steadier trends compared to Large Size models.
### Interpretation
- **Model Size vs. Performance**: Larger models (orange squares) typically achieve higher accuracy but exhibit diminishing returns or declines at longer response lengths, suggesting potential inefficiencies or overfitting.
- **Dataset Variability**: MATH500’s consistent performance contrasts with AIMO2024’s volatility, indicating dataset-specific challenges for Large Size models.
- **Trend Slopes**: Larger models often have steeper slopes (e.g., AIMO2024: 6.84e-05 vs. Small Size: 3.25e-05), but this does not always translate to sustained accuracy gains.
- **Anomalies**: The drop in Large Size accuracy for OMNI-MATH500 and AIMO2024 at longer response lengths warrants further investigation into model behavior under extended computational constraints.
This analysis highlights trade-offs between model size, response length, and accuracy, emphasizing the need for dataset-specific optimization strategies.